Реферат: Классификация систем параллельной обработки данных
1) Конвейерная и векторная обработка.
Основу конвейерной обработки составляет раздельное выполнение некоторой операции в несколько этапов (за несколько ступеней) с передачей данных одного этапа следующему. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько операций. Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых операндов соответствует максимальной производительности конвейера. Если происходит задержка, то параллельно будет выполняться меньше операций и суммарная производительность снизится. Векторные операции обеспечивают идеальную возможность полной загрузки вычислительного конвейера.
При выполнении векторной команды одна и та же операция применяется ко всем элементам вектора (или чаще всего к соответствующим элементам пары векторов). Для настройки конвейера на выполнение конкретной операции может потребоваться некоторое установочное время, однако затем операнды могут поступать в конвейер с максимальной скоростью, допускаемой возможностями памяти. При этом не возникает пауз ни в связи с выборкой новой команды, ни в связи с определением ветви вычислений при условном переходе. Таким образом, главный принцип вычислений на векторной машине состоит в выполнении некоторой элементарной операции или комбинации из нескольких элементарных операций, которые должны повторно применяться к некоторому блоку данных. Таким операциям в исходной программе соответствуют небольшие компактные циклы.
2) Машины типа SIMD.
SIMD компьютер имеет N идентичных процессоров, N потоков данных и один поток команд. Каждый процессор обладает собственной локальной памятью. Процессоры интерпретируют адреса данных либо как локальные адреса собственной памяти, либо как глобальные адреса, возможно, модифицированные добавлением локального базового адреса. Процессоры получают команды от одного центрального контроллера команд и работают синхронно, то есть на каждом шаге все процессоры выполняют одну и ту же команду над данными из собственной локальной памяти.


Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все процессорные элементы в такой машине выполняют одну и ту же программу. Очевидно, что такая машина, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу. Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных.
Такая архитектура с распределенной памятью часто упоминается как архитектура с параллелизмом данных(data-parallel), так как параллельность достигается при наличии одиночного потока команд, действующего одновременно на несколько частей данных. Сеть, соединяющая процессоры, обычно имеет регулярную топологию такую как кольцо SLAP:

Сеть с топологией кольцо
В отличие от ограниченного конвейерного функционирования векторного процессора, матричный процессор (синоним для большинства SIMD-машин) может быть значительно более гибким. Обрабатывающие элементы таких процессоров - это универсальные программируемые ЭВМ, так что задача, решаемая параллельно, может быть достаточно сложной и содержать ветвления. Обычное проявление этой вычислительной модели в исходной программе примерно такое же, как и в случае векторных операций: циклы на элементах массива, в которых значения, вырабатываемые на одной итерации цикла, не используются на другой итерации цикла.
Модели вычислений на векторных и матричных ЭВМ настолько схожи, что эти ЭВМ часто обсуждаются как эквивалентные.
3) Машины типа MIMD.
MIMD компьютер имеет N процессоров, независимо исполняющих N потоков команд и обрабатывающих N потоков данных. Каждый процессор функционирует под управлением собственного потока команд, то есть MIMD компьютер может параллельно выполнять совершенно разные программы.
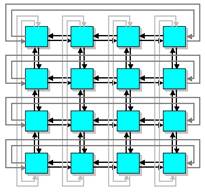
![]()

MIMD архитектуры далее классифицируются в зависимости от физической организации памяти, то есть имеет ли процессор свою собственную локальную память и обращается к другим блокам памяти, используя коммутирующую сеть, или коммутирующая сеть подсоединяет все процессоры к общедоступной памяти. Исходя из организации памяти, различают следующие типы параллельных архитектур:
• Компьютеры с распределенной памятью (Distributed memory)
Процессор может обращаться к локальной памяти, может посылать и получать сообщения, передаваемые по сети, соединяющей процессоры. Сообщения используются для осуществления связи между процессорами или, что эквивалентно, для чтения и записи удаленных блоков памяти. В идеализированной сети стоимость посылки сообщения между двумя узлами сети не зависит как от расположения обоих узлов, так и от трафика сети, но зависит от длины сообщения.

• Компьютеры с общей (разделяемой) памятью (True shared memory)
Все процессоры совместно обращаются к общей памяти, обычно, через шину или иерархию шин. В идеализированной PRAM (Parallel Random Access Machine - параллельная машина с произвольным доступом) модели, часто используемой в теоретических исследованиях параллельных алгоритмов, любой процессор может обращаться к любой ячейке памяти за одно и то же время. На практике масштабируемость этой архитектуры обычно приводит к некоторой форме иерархии памяти. Частота обращений к общей памяти может быть уменьшена за счет сохранения копий часто используемых данных в кэш-памяти, связанной с каждым процессором. Доступ к этому кэш-памяти намного быстрее, чем непосредственно доступ к общей памяти.
• Компьютеры с виртуальной общей (разделяемой) памятью (Virtual shared memory)
Общая память как таковая отсутствует. Каждый процессор имеет собственную локальную память и может обращаться к локальной памяти других процессоров, используя "глобальный адрес". Если "глобальный адрес" указывает не на локальную память, то доступ к памяти реализуется с помощью сообщений, пересылаемых по коммуникационной сети.
MIMD архитектуры с распределенной памятью можно так же классифицировать по пропускной способности коммутирующей сети. Например, в архитектуре, в которой пары из процессора и модуля памяти (процессорный элемент) соединены сетью с топологий решетка, каждый процессор имеет одно и то же число подключений к сети вне зависимости от числа процессоров компьютера. Общая пропускная способность такой сети растет линейно относительно числа процессоров. В топологии клика каждый процессор должен быть соединен со всеми другими процессорами. С другой стороны в архитектуре, имеющей сеть с топологий гиперкуб, число соединений процессора с сетью является логарифмической функцией от числа процессоров, а пропускная способность сети растет быстрее, чем линейно по отношению к числу процессоров.
Сеть с топологией 2D решетка(тор)