Реферат: Латентно-семантический анализ
Давайте теперь отметим на графике точки соответствующие отдельным текстам и словам, получится такая занятная картинка:
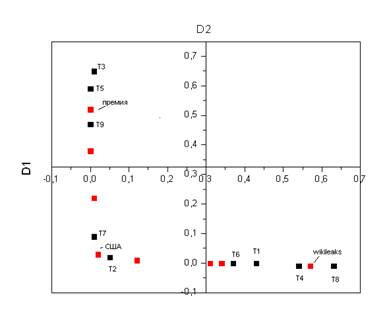
Из данного графика видно, что статьи образуют три независимые группы, первая группа статей располагается рядом со словом «wikileaks», и действительно, если мы посмотрим названия этих статей становится понятно, что они имеют отношение к wikileaks. Другая группа статей образуется вокруг слова «премия», и действительно в них идет обсуждение нобелевской премии.
На практике, конечно, количество групп будет намного больше, пространство будет не двумерным а многомерным, но сама идея остается той же. Мы можем определять местоположения слов и статей в нашем пространстве и использовать эту информацию для, например, определения тематики статьи.
Улучшения алгоритма
Легко заметить что подавляющее число ячеек частотной матрицы индексируемых слов, созданной на первом шаге, содержат нули. Матрица сильно разрежена и это свойство может быть использовано для улучшения производительности и потребления памяти при создании более сложной реализации.
В нашем случае тексты были примерно одной и той же длины, в реальных ситуациях частотную матрицу следует нормализовать. Стандартный способ нормализации матрицы TF-IDF
Мы использовали двухмерную декомпозицию SVD-2, в реальных примерах, размерность может составлять несколько сотен и больше. Выбор размерности определяется конкретной задачей, но общее правило таково: чем меньше размерность тем меньше семантических групп вы сможете обнаружить, чем больше размерность, тем большее влияние шумов.
Замечания
Для написания статьи использовалась Java-библиотека для работы с матрицами Jama. Кроме того, функция SVD реализована в известных математических пакетах вроде Mathcad, существуют библиотеки для Python и C++.