Реферат: Протоколы обмена маршрутной информацией стека TCP/IP
Обмен маршрутной информацией начинается с посылки одним из шлюзов другому сообщения запрос данных (poll request) о номерах сетей, обслуживаемых другим шлюзом и расстояниях до них от него. Ответом на это сообщение служит сообщение обновленная маршрутная информация (routing update). Если же запрос оказался некорректным, то в ответ на него отсылается сообщение об ошибке.
Все сообщения протокола EGP передаются в поле данных IP-пакетов. Сообщения EGP имеют заголовок фиксированного формата (рисунок 8.4).
Поля Тип и Код совместно определяют тип сообщения, а поле Статус - информацию, зависящую от типа сообщения. Поле Номер автономной системы - это номер, назначенный той автономной системе, к которой присоединен данный внешний шлюз. Поле Номер последовательности служит для синхронизации процесса запросов и ответов.
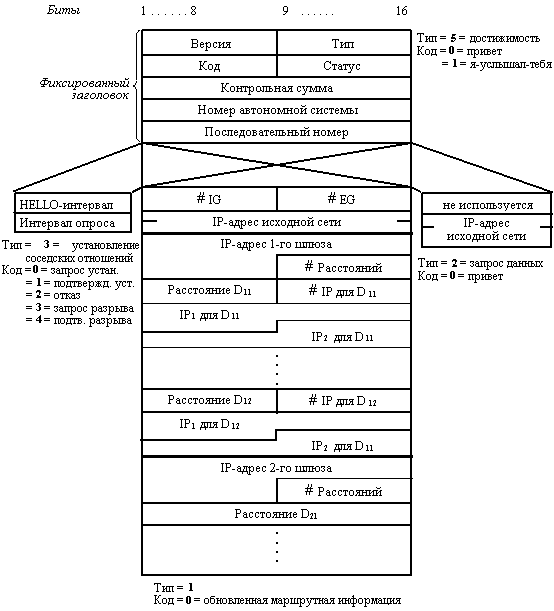
Рис. 8.4. Формат сообщения протокола EGP
Поле IP-адрес исходной сети в сообщениях запроса и обновления маршрутной информации обозначает сеть, соединяющую два внешних шлюза (рисунок 8.5).
Сообщение об обновленной маршрутной информации содержит список адресов сетей, которые достижимы в данной автономной системе. Этот список упорядочен по внутренним шлюзам, которые подключены к исходной сети и через которые достижимы данные сети, а для каждого шлюза он упорядочен по расстоянию до каждой достижимой сети от исходной сети , а не от данного внутреннего шлюза . Для примера, приведенного на рисунке 8.5, внешний шлюз R2 в своем сообщении указывает, что сеть 4 достижима с помощью шлюза R3 и расстояние ее равно 2, а сеть 2 достижима через шлюз R2 и ее расстояние равно 1 (а не 0, как если бы шлюз измерял ее расстояние от себя, как в протоколе RIP).
Протокол EGP имеет достаточно много ограничений, связанных с тем, что он рассматривает магистральную сеть как одну неделимую магистраль.
Развитием протокола EGP является протокол BGP (Border Gateway Protocol), имеющий много общего с EGP и используемый наряду с ним в магистрали сети Internet.
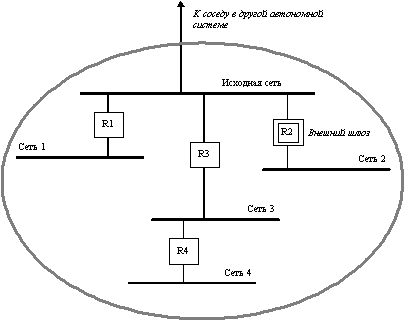
Рис. 8.5. Пример автономной системы
Протокол состояния связей OSPF
Протокол OSPF (Open Shortest Path Firs) является достаточно современной реализацией алгоритма состояния связей (он принят в 1991 году) и обладает многими особенностями, ориентированными на применение в больших гетерогенных сетях.
Протокол OSPF вычисляет маршруты в IP-сетях, сохраняя при этом другие протоколы обмена маршрутной информацией.
Непосредственно связанные (то есть достижимые без использования промежуточных маршрутизаторов) маршрутизаторы называются "соседями". Каждый маршрутизатор хранит информацию о том, в каком состоянии по его мнению находится сосед. Маршрутизатор полагается на соседние маршрутизаторы и передает им пакеты данных только в том случае, если он уверен, что они полностью работоспособны. Для выяснения состояния связей маршрутизаторы-соседи достаточно часто обмениваются короткими сообщениями HELLO.
Для распространения по сети данных о состоянии связей маршрутизаторы обмениваются сообщениями другого типа. Эти сообщения называются router links advertisement - объявление о связях маршрутизатора (точнее, о состоянии связей). OSPF-маршрутизаторы обмениваются не только своими, но и чужими объявлениями о связях, получая в конце-концов информацию о состоянии всех связей сети. Эта информация и образует граф связей сети, который, естественно, один и тот же для всех маршрутизаторов сети.
Кроме информации о соседях, маршрутизатор в своем объявлении перечисляет IP-подсети, с которыми он связан непосредственно, поэтому после получения информации о графе связей сети, вычисление маршрута до каждой сети производится непосредственно по этому графу по алгоритму Дэйкстры. Более точно, маршрутизатор вычисляет путь не до конкретной сети, а до маршрутизатора, к которому эта сеть подключена. Каждый маршрутизатор имеет уникальный идентификатор, который передается в объявлении о состояниях связей. Такой подход дает возможность не тратить IP-адреса на связи типа "точка-точка" между маршрутизаторами, к которым не подключены рабочие станции.
Маршрутизатор вычисляет оптимальный маршрут до каждой адресуемой сети, но запоминает только первый промежуточный маршрутизатор из каждого маршрута. Таким образом, результатом вычислений оптимальных маршрутов является список строк, в которых указывается номер сети и идентификатор маршрутизатора, которому нужно переслать пакет для этой сети. Указанный список маршрутов и является маршрутной таблицей, но вычислен он на основании полной информации о графе связей сети, а не частичной информации, как в протоколе RIP.
Описанный подход приводит к результату, который не может быть достигнут при использовании протокола RIP или других дистанционно-векторных алгоритмов. RIP предполагает, что все подсети определенной IP-сети имеют один и тот же размер, то есть, что все они могут потенциально иметь одинаковое число IP-узлов, адреса которых не перекрываются. Более того, классическая реализация RIP требует, чтобы выделенные линии "точка-точка" имели IP-адрес, что приводит к дополнительным затратам IP-адресов.
В OSPF такие требования отсутствуют: сети могут иметь различное число хостов и могут перекрываться. Под перекрытием понимается наличие нескольких маршрутов к одной и той же сети. В этом случае адрес сети в пришедшем пакете может совпасть с адресом сети, присвоенным нескольким портам.
Если адрес принадлежит нескольким подсетям в базе данных маршрутов, то продвигающий пакет маршрутизатор использует наиболее специфический маршрут, то есть адрес подсети, имеющей более длинную маску.
Например, если рабочая группа ответвляется от главной сети, то она имеет адрес главной сети наряду с более специфическим адресом, определяемым маской подсети. При выборе маршрута к хосту в подсети этой рабочей группы маршрутизатор найдет два пути, один для главной сети и один для рабочей группы. Так как последний более специфичен, то он и будет выбран. Этот механизм является обобщением понятия "маршрут по умолчанию", используемого во многих сетях.
Использование подсетей с различным количеством хостов является вполне естественным. Например, если в здании или кампусе на каждом этаже имеются локальные сети, и на некоторых этажах компьютеров больше, чем на других, то администратор может выбрать размеры подсетей, отражающие ожидаемые требования каждого этажа, а не соответствующие размеру наибольшей подсети.
В протоколе OSPF подсети делятся на три категории:
- "хост-сеть", представляющая собой подсеть из одного адреса,
- "тупиковая сеть", которая представляет собой подсеть, подключенную только к одному маршрутизатору,
- "транзитная сеть", которая представляет собой подсеть, подключенную к более чем одному маршрутизатору.
Транзитная сеть является для протокола OSPF особым случаем. В транзитной сети несколько маршрутизаторов являются взаимно и одновременно достижимыми. В широковещательных локальных сетях, таких как Ethernet или Token Ring, маршрутизатор может послать одно сообщение, которое получат все его соседи. Это уменьшает нагрузку на маршрутизатор, когда он посылает сообщения для определения существования связи или обновленные объявления о соседях. Однако, если каждый маршрутизатор будет перечислять всех своих соседей в своих объявлениях о соседях, то объявления займут много места в памяти маршрутизатора. При определении пути по адресам транзитной подсети может обнаружиться много избыточных маршрутов к различным маршрутизаторам. На вычисление, проверку и отбраковку этих маршрутов уйдет много времени.
Когда маршрутизатор начинает работать в первый раз (то есть инсталлируется), он пытается синхронизировать свою базу данных со всеми маршрутизаторами транзитной локальной сети, которые по определению имеют идентичные базы данных. Для упрощения и оптимизации этого процесса в протоколе OSPF используется понятие "выделенного" маршрутизатора, который выполняет две функции.
Во-первых, выделенный маршрутизатор и его резервный "напарник" являются единственными маршрутизаторами, с которыми новый маршрутизатор будет синхронизировать свою базу. Синхронизировав базу с выделенным маршрутизатором, новый маршрутизатор будет синхронизирован со всеми маршрутизаторами данной локальной сети.
Во-вторых, выделенный маршрутизатор делает объявление о сетевых связях, перечисляя своих соседей по подсети. Другие маршрутизаторы просто объявляют о своей связи с выделенным маршрутизатором. Это делает объявления о связях (которых много) более краткими, размером с объявление о связях отдельной сети.
Для начала работы маршрутизатора OSPF нужен минимум информации - IP-конфигурация (IP-адреса и маски подсетей), некоторая информация по умолчанию (default) и команда на включение. Для многих сетей информация по умолчанию весьма похожа. В то же время протокол OSPF предусматривает высокую степень программируемости.
Интерфейс OSPF (порт маршрутизатора, поддерживающего протокол OSPF) является обобщением подсети IP. Подобно подсети IP, интерфейс OSPF имеет IP-адрес и маску подсети. Если один порт OSPF поддерживает более, чем одну подсеть, протокол OSPF рассматривает эти подсети так, как если бы они были на разных физических интерфейсах, и вычисляет маршруты соответственно.
Интерфейсы, к которым подключены локальные сети, называются широковещательными (broadcast) интерфейсами, так как они могут использовать широковещательные возможности локальных сетей для обмена сигнальной информацией между маршрутизаторами. Интерфейсы, к которым подключены глобальные сети, не поддерживающие широковещание, но обеспечивающие доступ ко многим узлам через одну точку входа, например сети Х.25 или frame relay, называются нешироковещательными интерфейсами с множественным доступом или NBMA (non-broadcast multi-access). Они рассматриваются аналогично широковещательным интерфейсам за исключением того, что широковещательная рассылка эмулируется путем посылки сообщения каждому соседу. Так как обнаружение соседей не является автоматическим, как в широковещательных сетях, NBMA-соседи должны задаваться при конфигурировании вручную. Как на широковещательных, так и на NBMA-интерфейсах могут быть заданы приоритеты маршрутизаторов для того, чтобы они могли выбрать выделенный маршрутизатор.
Интерфейсы "точка-точка", подобные PPP, несколько отличаются от традиционной IP-модели. Хотя они и могут иметь IP-адреса и подмаски, но необходимости в этом нет.
В простых сетях достаточно определить, что пункт назначения достижим и найти маршрут, который будет удовлетворительным. В сложных сетях обычно имеется несколько возможных маршрутов. Иногда хотелось бы иметь возможности по установлению дополнительных критериев для выбора пути: например, наименьшая задержка, максимальная пропускная способность или наименьшая стоимость (в сетях с оплатой за пакет). По этим причинам протокол OSPF позволяет сетевому администратору назначать каждому интерфейсу определенное число, называемое метрикой, чтобы оказать нужное влияние на выбор маршрута.
Число, используемое в качестве метрики пути, может быть назначено произвольным образом по желанию администратора. Но по умолчанию в качестве метрики используется время передачи бита в 10-ти наносекундных единицах (10 Мб/с Ethernet'у назначается значение 10, а линии 56 Кб/с - число 1785). Вычисляемая протоколом OSPF метрика пути представляет собой сумму метрик всех проходимых в пути связей; это очень грубая оценка задержки пути. Если маршрутизатор обнаруживает более, чем один путь к удаленной подсети, то он использует путь с наименьшей стоимостью пути.