Реферат: Сравнение архитектуры POWER с другими RISC архитектурами.
2.2 Очередь команд и устройство распределения.
Очередь команд (IQ) содержит шесть команд и может быть загружена четырьмя командами за такт. Устройство выборки пытается загрузить команды на все свободные места в очереди. Все команды распределяются к соответствующим устройствам выполнения (IU1, IU2, FPU, LSU, SRU) из двух верхних позиций в очереди с максимальной скоростью две за такт. Устройство распределения проверяет зависимости регистров источника и приемника, определяет свободна ли место в очереди завершения команд, и распределяет последовательные команды по назначению.
2.3 Устройство обработки переходов.
BPU получает команды перехода из устройства выборки и делает упреждающий поиск условных ветвей для их раннего предсказания, достигая попадания в большинстве случаев.
Команды безусловного перехода или с известным условием могут быть предсказаны сразу. Для переходов с неопределенными условиями используется динамическое или статическое предсказание. Команды из предсказанной ветви выполняются, но не завершаются и не записывают результаты до подтверждения корректности перехода.
Динамическое предсказание использует таблицу истории переходов (BHT) из 512 записей, кэш который содержит по 2 бита, определяющие 4 уровня вероятности перехода. Когда динамическое предсказание запрещено переход выбирается исходя из бита в коде команды для предсказания условных переходов.
Когда переход сделан ( или предсказан), команды из остальных ветвей удаляются и загружаются команды из нужной ветви. BTIC - кэш на 64 элемента, содержащий команды из последних переходов. Когда команды находятся в BTIC, они считываются на следующем такте, иначе через один такт.
BPU содержит сумматор для вычисления адресов переходов и использует три регистра - регистр связи (LR), регистр-счетчик (CTR) и CR. BPU вычисляет точку возврата из процедуры и сохраняет результат в LR определенных команд перехода. Также в регистрах LR и CTR содержат адреса для некоторых команд обработки переходов. Из-за использования специальных регистров обработка команд переходов независима от выполнения целочисленных команд и команд с ПТ.
2.4 Устройство завершения команд.
В точке распределения команд, порядок выполнения команд поддерживается назначение команде места в очереди завершения на 6 мест. Устройство завершения отслеживает команды от распределения через устройства выполнения и возвращает результаты в порядке выполнения команд в программе из 2 нижних мест в очереди выполнения.
Команда не может быть отправлена на выполнение, если нет места в очереди завершения. Команды перехода, не модифицирующие CTR и LR удаляются из потока команд и не занимают места в очереди завершения. Команды, модифицирующие CTR и LR занимают место в очереди, но не посылаются на выполнение.
Завершение команды состоит в записи результатов в регистры (GPR, FPR, LR и CTR).
Завершенные команды удаляются из очереди завершения.
2.5 Устройства выполнения.
2.5.1 Устройства выполнения целочисленных команд (IU).
Каждое IU состоит из трех однотактовых подустройств - быстрый сумматор/компаратор, обработки логических операций и выполнения сдвигов и циклических сдвигов. Только одно подустройство может выполнять команду в каждый момент времени.
2.5.2 Устройство выполнения команд с плавающей точкой (FPU)
FPU выполняет операции одинарной точности (32 разряда) за один проход, состоящий из трех тактов. Операнды берутся из регистров FPR или буфера переименования FPR. Результаты записываются в буфер переименования регистров и доступны для последующих команд. Команды поступают в FPU в порядке распределения устройством управления командами.
FPU содержит массив для умножения-сложения одинарной точности и контрольный регистр (FPSCR). Массив умножения-сложения позволяет 750 эффективно выполнять команды умножения и умножения-сложения. FPU является конвейерным, так что за один такт выдается одна обработанная команда. Для поддержки команд с ПТ предоставляются 32 64-разрядных регистра. Остановки, вызванные конфликтами при записи в FPR минимизируются 6 регистрами переименования с ПТ. 750 записывает содержимое регистров переименования при выходе команды из устройства завершения.
750 поддерживает все форматы с ПТ стандарта IEEE 754 (нормализованные, ненормализованные, NaN, ноль, бесконечность).
2.5.3 Устройство загрузки/записи (LSU).
LSU выполняет все команды загрузки и сохранения и предоставляет интерфейс пересылки данных между GPR, FPR, и подсистем кэш/память.
Команды загрузки и записи выполняются в порядке программы; однако некоторые обращения в память могут происходить вне очереди команд. Команды синхронизации могут быть использованы для изменения порядка команд. Максимум одна операция загрузки из кэша вне очереди может быть выполнена за такт, с двухтактовой задержкой загрузки из кэша. Данные из кэша хранятся в регистрах переименования до их записи в GPR или FPR. Сохранение не может выполняться вне очереди и операции сохранения находятся в очереди сохранения до разрешения на запись. 750 выполняет команды сохранения максимум одну за такт с общей трехтактовой задержкой записи в кэш.
2.5.4 Устройство системных регистров (SRU).
SRU выполняет различные команды системного уровня, такие как логические операции с регистром условия и команды работы с регистрами специального назначения. Команды, выполняемые SRU, сохраняются в нем и обрабатываются после выполнения всех предыдущих команд.
2.6 Устройство управления памятью (MMU) .
MMU поддерживает до 4 Петабайт (252) виртуальной памяти и до 4 Гигабайт (232) физической памяти для команд и данных со страницами по 4 Кб и сегментами по 256 Мб. MMU контролирует привилегии доступа , разбивая память на блоки и страницы. Вообще, механизм преобразования адресов состоит в преобразовании эффективного адреса в промежуточный виртуальный исходя из сегментной информации и затем в физический по таблицам страниц. Дескрипторы сегментов, используемые для генерации промежуточного внутреннего адреса, хранятся как встроенные 32-разрядные сегментные регистры.
В 750 реализовано 2 буфера TLB, так что доступ к TLB для команд и данных может производится независимо. 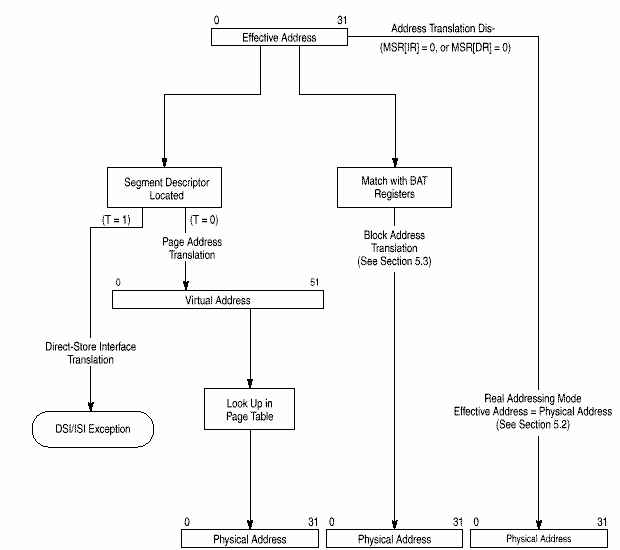
Механизм преобразования адресов блоков (block address translation, BAT) - программно-контролируемый массив доступных преобразований адресов блоков. Механизм BAT управляет преобразованием блоков до 256 Мб из 32-разрядного эффективного адресного пространства в физическое. Используются для преобразования адресов, не часто меняющих свое отображение. Элементами массива BAT являются пары BAT-регистров, доступных в режиме супервизора. В 750 есть отдельные механизмы BAT для команд и данных (4 IBAT и 4 DBAT).
LSU и устройство управления потоком команд вычисляют эффективные адреса данных и команд. MMU преобразует эффективные адреса в физические для доступа к памяти.
750 поддерживает следующие режимы преобразования адресов:
· Реальный (real addressing) - физический адрес совпадает с эффективным.
· Страничный (page address translation) - преобразует адреса страниц (4 Кб)
· Блочный (block address translation) - преобразует базовые адреса блоков (от 128 Кб до 256 Мб)
Если работает преобразование адресов, MMU преобразует старшие биты эффективного адреса в физический. Если адрес найден в массиве BAT, то физический адрес выдается сразу, иначе 32-битный эффективный адрес расширяется в 52-битный виртуальный замещением 24 старших битов на сегментный регистр, адресуемый 4 старшими битами ЕА. 52-разрядные виртуальные адреса разделены на 4 Кб страницы, отображаемые в физические.
Младшие биты адреса одинаковы и используются для вычисления индекса в массиве тэгов кэша. После преобразования адресов MMU посылает физический адрес в кэш и данные считываются. Если кэш не используется или данных в нем нет, то не преобразованные младшие биты соединяются с преобразованными старшими в 32-разрядный физический адрес, который используется для доступа к внешней памяти. 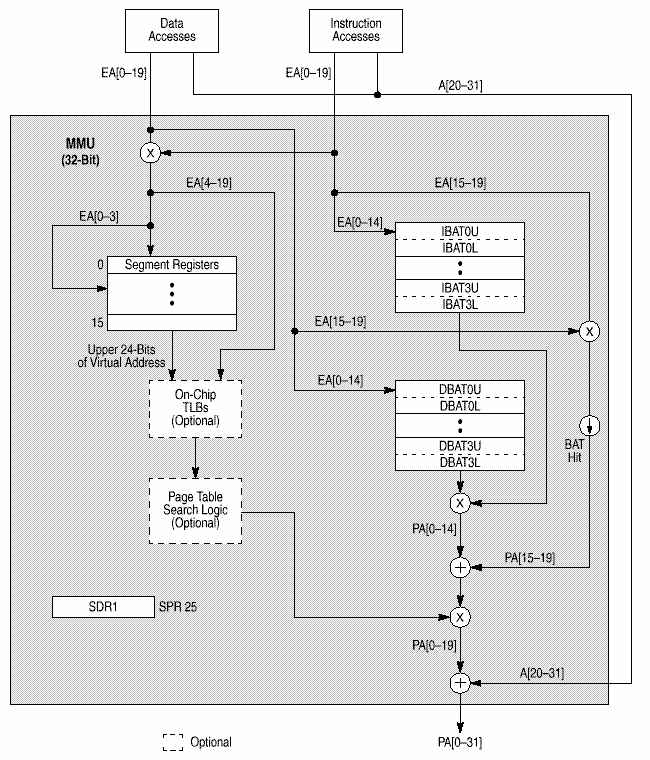
TLB используется для сохранения последних преобразований адресов при обращении к памяти. При каждом обращении, преобразование эффективного адреса по страницам или блокам производится одновременно. Если преобразование найдено и в TLB и в BAT, используется преобразование адреса блока в BAT. Обычно преобразование адреса находится в TLB и физический адрес доступен для считывания из кэша сразу. Иначе адрес ищется в таблице страниц следуя модели, определенной архитектурой PowerPC.
TLB команд и данных преобразует адрес одновременно с доступом к внутреннему кэшу, исключая затраты времени в случае попадания в TLB.
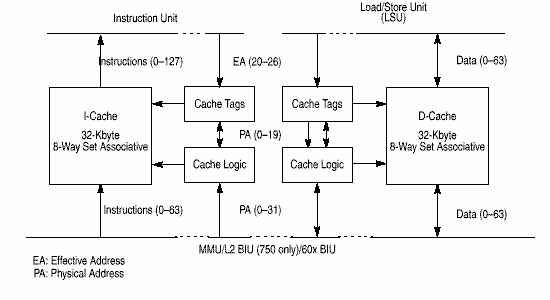
2.7 Встроенные кэши команд и данных.
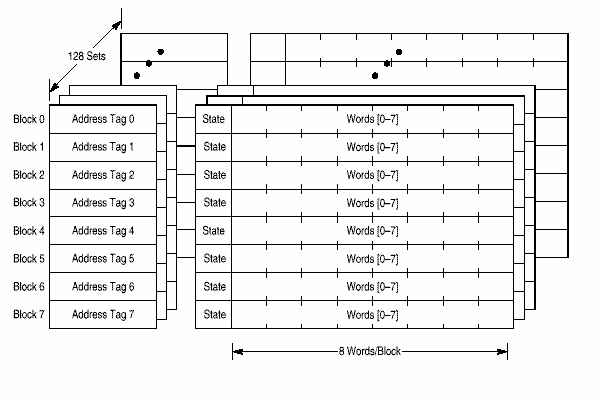
В 750 реализованы отдельные 32 Кб кэши для команд и данных (Гарвардская архитектура). Оба кэша восьмиканальные частично ассоциативные. По архитектуре PowerPC кэши адресуются физически, реальный адрес хранится в директории кэша. Оба кэша организованы в блоки по 32 байта. Блок кэша - блок памяти, для которого описано состояние когерентности. Для каждого банка данных кэша используется алгоритм PLRU (pseudo least-recently-used) замены данных (алгоритм изложен в документации). Когерентность данных глобальной памяти и данных в кэше производится по протоколу MEI процедурой слежения (snooping) по шине когерентности. Состояниякогерентностидлякэшаданных: Modified (Exclusive) (M), Exclusive (Unmodified) (E), Invalid (I). Для кэша команд: Invalid (INV), Valid (VAL). Каждый кэш можно сделать недействительным (invalidate) установкой соответствующих битов в специальных регистрах (HID0).
При непопадании в кэш, блоки заполняются за 4 прохода по 64 бита. Двойные слова одновременно записываются в кэш и в запрашивающее устройство, минимизируя задержки.
Оба кэша тесно связаны с устройством шины интерфейса (bus interface unit, BUI). BUI получает запросы от кэшей и выполняет эти операции в соответствии с протоколом 60х. BUI предоставляет очереди адресов, логику приоритетов и логику контроля шины.
Кэш данных предоставляет буферы для сохранения и загрузки операций шины. Все данные из соответствующих адресных очередей помещены в кэш данных. В кэше данных также производится сохранение тэгов, требуемых для когерентности с памятью и замещение блоков кэша функциями PLRU.
Кэш данных организован в 128 банков по 8 блоков. Каждый блок содержит 32 байта, 2 бита состояния и адресный тэг. Каждый блок кэша содержит 8 последовательных слов из памяти которые загружаются с границы в 8 слов (т.е. биты ЕА[27-31] равны 0): таким образом блок кэша никогда не пересекает границу страницы. Не выровненные обращения через границу страницы могут повлечь уменьшение производительности. Во время загрузки данных кэш не блокируется для внешних доступов до полной загрузки.
В течение такта кэш данных предоставляет для считывания в LSU двойное слово. Как и кэш команд, кэш данных может быть сделан недействительным (invalidated) весь или поблочно. Данные кэша делаются недоступными и недействительными сбросом HID0[DCE] и установкой HID0[DCFI], кэш данных может быть заблокирован установкой HID0[DLOCK]. Тэги кэша имеют один порт, поэтому одновременная загрузка/сохранение и обращения для когерентности кэша вызывают конфликт, при этом LSU внутренне блокируется на один такт для записи блока данных в 8 слов в буфер обратной записи.
Кэш команд также состоит из 128 банков по 8 блоков. Каждый блок состоит из 32 байтов, 1 бита состояния и адресного тэга. За один цикл кэш команд предоставляет до 4 команд в очередь команд. В кэше команд поддерживаются только состояния верно/неверно (valid/invalid) для данных. Кэш команд не отслеживается, поэтому если изменяется память, данные которой содержатся в кэше, программа должна сообщать об этом устройству выборки команд. Кэш команд может быть сделан недействительным весь или поблочно. Доступ к кэшу запрещается и кэш делается недействительным сбросом HID0[ICE] и установкой HID0[ICFI], кэш блокируется установкой HID0[ILOCK].
В 750 реализован также кэш команд переходов (branch target instruction cache, BTIC). В BTIC хранятся встретившиеся в программе команды переходов/циклов. Если команда находится в BTIC она поступает в очередь команд на такт быстрее, чем из кэша команд.
3. Системный интерфейс. Схема выводов процессора.

3.1 Шины адреса и данных функционируют раздельно. Используются два вида доступов к памяти и пересылки данных:
· Однотактовая (single-beat) пересылка - пересылка 8, 16, 24, 32 или 64 битов за такт шины. Используется при некэшируемых доступах в память.
· Четырехтактовая пакетная (four-beat burst) пересылка данных - используется для чтения блоков кэша. Так как кэши первого уровня с обратной записью, то пакетные доступы к памяти используются наиболее часто.
Доступ к системной шине дается через механизм внутреннего арбитража.
Обычно доступы к памяти слабо упорядочены - последовательности команд загрузки/записи не обязательно выполнять ?