Реферат: Выделение ключевых слов в текстовых документах
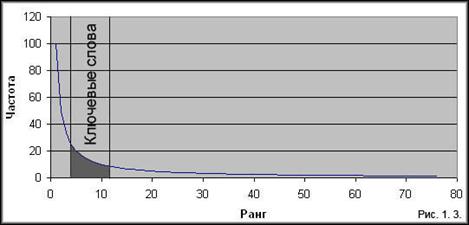
Одним из способов, например, является предварительное исключение из исследуемого текста слов, которые изначально не могут являться значимыми и, поэтому, являющиеся «шумом». Такие слова называются нейтральными или стоповыми (стоп-словами).
Для русского текста стоповыми словами могли бы являться все предлоги, частицы, личные местоимения. Есть и другие способы повысить точность оценки значимости слов.
Некоторые слова могут встречаться почти во всех документах некоторой коллекции и, соответственно, оказывать малое влияние на принадлежность документа к той или иной категории, а значит не быть ключевыми для этого документа. Поэтому очевидно, что, рассматривая всю коллекцию документов, мы повысим информативность выделения ключевых слов.
2. Глобальная статистика, модель TF*IDF
Выше отмечалось, к коллекции документов тоже применимы законы Ципфа. Для понижения значимости слов, которые встречаются почти во всех документах, вводят инверсную частоту термина IDF (inversedocumentfrequency) – это логарифм отношения числа всех документов (![]() ) к числу документов содержащих некоторое слово t (2.1.). Значение этого параметра тем меньше, чем чаще слово встречается в документах базы данных. Таким образом, для слов, которые встречаются в большом числе документов IDFбудет близок к нулю (если слово встречается во всех документах IDFравен нулю), что помогает выделить важные слова.
) к числу документов содержащих некоторое слово t (2.1.). Значение этого параметра тем меньше, чем чаще слово встречается в документах базы данных. Таким образом, для слов, которые встречаются в большом числе документов IDFбудет близок к нулю (если слово встречается во всех документах IDFравен нулю), что помогает выделить важные слова.

![]() (2.1)
(2.1)
Параметр TF (termfrequency) – это отношение числа раз, которое некоторое слово t встретилось в документе d, к длине документа (2.2.). Нормализация длиной документа нужна для того, чтобы уравнять в правах короткие и длинные (в которых абсолютная встречаемость слов может быть гораздо больше) документы.

![]() (2.2.)
(2.2.)
Коэффициент TFIDFравен произведению TFи IDF. TFиграет роль повышающего множителя, IDF– понижающего. Тогда весовыми параметрами векторной модели некоторого документа можно принять коэффициенты TF*IDFвходящих в него слов [10].
Для того чтобы веса находились в интервале (0, 1), а векторы документов имели равную длину, значения TF*IDFобычно нормализуются по косинусу.
Отметим, что эта формула оценивает значимость термина только с точки зрения частоты вхождения в документ, тем самым не учитывая порядок следования терминов в документе и их синтаксическую роль; другими словами, семантика документа сводится к лексической семантике входящих в него терминов, а композиционная семантика не рассматривается.
Ключевыми в данном случае будут являться слова набравший наибольший вес. Слова с малым весом, вообще можно не учитывать при классификации.
Проиллюстрируем на простом примере.
Пусть коллекция состоит из 2 предложений.
1). Мама мыла мылом Машу.
2). Мама мыла, мыла раму.
3). В магазине купила мама мыло.
Вид словаря тогда будет следующим:
| Слово | Всего | Встретилось в предложениях | IDF |
| Мама | 3 | 3 | 0 |
| мыть | 3 | 2 | 0,18 |
| мыло | 2 | 2 | 0,47 |
| Маша | 1 | 1 | 0,47 |
| рама | 1 | 1 | 0,47 |
| магазин | 1 | 1 | 0,47 |
| купить | 1 | 1 | 0,47 |
Вид векторов
| 1 | 2 | 3 | ||||||
| Слово | TF | TF*IDF | Слово | TF | TF*IDF | Слово | TF | TF*IDF |
| Маша | 0,25 | 0,12 | рама | 0,25 | 0,11 | магазин | 0,25 | 0,12 |
| мыло | 0,25 | 0,12 | мыть | 0,5 | 0,09 | купить | 0,25 | 0,12 |
| мыть | 0,25 | 0,05 | мама | 0,25 | 0 | мыло | 0,25 | 0,12 |
| мама | 0,25 | 0 | мама | 0,25 | 0 | |||
Влияние TFвидно во втором векторе. Так как слово «мыть» встречается 2 раза, он выше, чем у остальных слов. Однако из-за того, что это слово встречается и в других документах, у него ниже параметр IDF, поэтому его общий вес в векторе будет ниже, чем у слова «рама». Так влияет параметр IDF.
Слово «мама» же вообще можно не учитывать в векторном представлении. Так как оно встречается во всех предложениях коллекции, его значение TF*IDFвсегда будет равно нулю.
Заметим, что все слова примера мы приводим к нормальной форме (лематизируем). Существуют противоречивые мнения относительно полезности данного шага в текстовой категоризации. Некоторые исследования (Baker, McCallum) отмечают снижение эффективности при использовании морфологической обработки, хотя в основном многие прибегают к ней, поскольку это способствует значительному сокращению размерности пространства.
Еще одним способом к сокращению словаря является возможный учет синонимии, так что слова – синонимы, объявляются одним термином словаря
Конечно, при данном подходе есть вероятность попадания в ключевые слова случайных специальных терминов, редких слов и имен собственных и другого «шума». Поэтому необходимо в предобработку текста включать алгоритмы повышающее качество отбора. Эвристики такого отбора чаще зависят от конкретно взятого случая.
Модель TF*IDFявляется, пожалуй, наиболее популярной. Однако используются и другие индексирующие функции, включая вероятные способы индексирования [3] и методики индексирования структурированных документов [4]. Иные функции индексации могут потребоваться в тех случаях, когда изначально обучающее множество не дано и документную частоту не удаётся посчитать. В этих случая TF*IDFменяют на эмпирические функции [2].
3. Экспериментальная оценка статистического анализа текста по модели TF*IDF
Для оценки выделения ключевых слов с помощью модели TF*IDFбыл разработан модуль, реализующий данный алгоритм. Целью эксперимента является оценка алгоритма.
В качестве входных примеров было использованы две коллекции документов. Коллекция COMPUTERвключает в себя 450 статей по общекомпьютерной тематике (материал из электронной версии журнала «Компьютера»), коллекция ANIMALвключает 190 статей о животных (материал из Википедии).
| Название | Количество документов | Суммарный объем |
| COMPUTER | 450 | 12,6 Мб |
| ANIMAL | 190 | 4,1 Мб |
Для каждого документа строилась векторная модель, в качестве ключевых брались 20 слов, набравших наибольший вес.
По каждому документу из коллекции проводилась экспертная оценка от 0 до 10 баллов (0 – ни одно из слов не может являться ключевым, 10 – все слова ключевые для данного документа). Данные по каждой коллекции усреднялись.