Дипломная работа: Расчет параметров асинхронного энергосберегающего электродвигателя
В отношении R атрибут Y функционально зависит от атрибута X (X и Y могут быть составными) в том и только в том случае, если каждому значению X соответствует в точности одно значение Y: R.X (r) R.Y.
Функциональная зависимость R.X (r) R.Y называется полной, если атрибут Y не зависит функционально от любого точного подмножества X.
Функциональная зависимость R.X R.Y называется транзитивной, если существует такой атрибут Z, что имеются функциональные зависимости R.X R.Z и R.Z R.Y и отсутствует функциональная зависимость R.Z --> R.X. (При отсутствии последнего требования мы имели бы "неинтересные" транзитивные зависимости в любом отношении, обладающем несколькими ключами.)
Неключевым атрибутом называется любой атрибут отношения, не входящий в состав первичного ключа (в частности, первичного).
Два или более атрибута взаимно независимы, если ни один из этих атрибутов не является функционально зависимым от других.
Отношение R находится во второй нормальной форме (2NF) в том и только в том случае, когда находится в 1NF, и каждый неключевой атрибут полностью зависит от первичного ключа.
Отношение R находится в третьей нормальной форме (3NF) в том и только в том случае, если находится в 2NF и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
На практике третья нормальная форма схем отношений достаточна в большинстве случаев, и приведением к третьей нормальной форме процесс проектирования реляционной базы данных обычно заканчивается. Однако иногда полезно продолжить процесс нормализации.
1.3.2 Язык реляционных баз данных SQL
Structured Query Language представляет собой непроцедурный язык, используемый для управления данными реляционных СУБД. Термин «непроцедурный» означает, что на данном языке можно сформулировать, что нужно сделать с данными, но нельзя проинструктировать, как именно это следует сделать. Иными словами, в этом языке отсутствуют алгоритмические конструкции, такие как метки, операторы цикла, условные переходы и др.
Язык SQL был создан в начале 70-х годов в результате исследовательского проекта IBM, целью которого было создание языка манипуляции реляционными данными. Первоначально он назывался SEQUEL (Structured English Query Language), затем — SEQUEL/2, а затем — просто SQL. Официальный стандарт SQL был опубликован ANSI (American National Standards Institute — Национальный институт стандартизации, США) в 1986 году (это наиболее часто используемая ныне реализация SQL). Данный стандарт был расширен в 1989 и 1992 годах. В настоящее время ведется работа над стандартом SQL3, содержащим некоторые объектно-ориентированные расширения.
Существует три уровня соответствия стандарту ANSI — начальный, промежуточный и полный. Многие производители серверных СУБД, такие как IBM, Informix, Microsoft, Oracle и Sybase, применяют собственные реализации SQL, основанные на стандарте ANSI (отвечающие как минимум начальному уровню соответствия стандарту) и содержащие некоторые расширения, специфические для данной СУБД.
Предположим, что имеется база данных, управляемая с помощью какой-либо СУБД. Для извлечения из нее данных используется запрос, сформулированный на языке SQL. СУБД обрабатывает этот запрос, извлекает запрашиваемые данные и возвращает их. Этот процесс схематически изображен на рисунке 1.7.
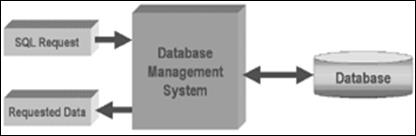
Рисунок 1.7 – Извлечение данных с использованием SQL запроса.
SQL позволяет не только извлекать данные, но и определять структуру данных, добавлять и удалять данные, ограничивать или предоставлять доступ к данным, поддерживать ссылочную целостность.
SQL сам по себе не является ни СУБД, ни отдельным продуктом. Это язык, применяемый для взаимодействия с СУБД и являющийся в определенном смысле ее неотъемлемой частью.
SQL содержит примерно 40 операторов для выполнения различных действий внутри СУБД. Ниже приводится краткое описание категорий этих операторов.
Data Definition Language содержит операторы, позволяющие создавать, изменять и уничтожать базы данных и объекты внутри них (таблицы, представления и др.).
Data Manipulation Language содержит операторы, позволяющие выбирать, добавлять, удалять и модифицировать данные. Эти операторы не обязаны завершать транзакцию, внутри которой они вызваны.
Операторы Transaction Control Language применяются для управления изменениями, выполненными группой операторов DML.
Операторы Data Control Language, иногда называемые операторами Access Control Language, применяются для осуществления административных функций, присваивающих или отменяющих право (привилегию) использовать базу данных, таблицы в базе данных, а также выполнять те или иные операторы SQL.
Операторы Cursor Control Language используются для определения курсора, подготовки SQL-предложений для выполнения, а также для некоторых других операторов.
Каждый оператор SQL начинается с глагола, представляющего собой ключевое слово, определяющее, что именно делает этот оператор (SELECT, INSERT, DELETE...). В операторе содержатся также предложения, содержащие сведения о том, над какими данными производятся операции. Каждое предложение начинается с ключевого слова, такого как FROM, WHERE и др. Структура предложения зависит от его типа — ряд предложений содержит имена таблиц или полей, некоторые могут содержать дополнительные ключевые слова, константы или выражения.
Все операторы SQL имеют вид, показанный на рисунке 1.8.
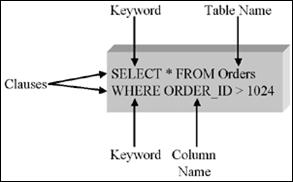
Рисунок 1.8 – Общий вид операторов SQL
1.3.3 СУБД dBase и Visual dBase
Первая промышленная версия СУБД dBase — dBase II (принадлежащая тогда компании Ashton-Tate, приобретенной позже компанией Borland) появилась в начале 80-х годов. Благодаря простоте в использовании, нетребовательности к ресурсам компьютера и, что не менее важно, грамотной маркетинговой политике компании-производителя этот продукт приобрел немалую популярность, а с выходом следующих его версий — dBase III и dBase III Plus (1986 г.), оснащенных весьма комфортной по тем временам средой разработки и средствами манипуляции данными, быстро занял лидирующие позиции среди настольных СУБД и средств создания использующих их приложений.
Хранение данных в dBase основано на принципе «одна таблица — один файл» (эти файлы обычно имеют расширение *.dbf). MEMO-поля и BLOB-поля (доступные в поздних версиях dBase) хранятся в отдельных файлах (обычно с расширением *.dbt). Индексы для таблиц также хранятся в отдельных файлах. При этом в ранних версиях этой СУБД требовалась специальная операция реиндексирования для приведения индексов в соответствие с текущим состоянием таблицы.
Формат данных dBase является открытым, что позволило ряду других производителей заимствовать его для создания dBase-подобных СУБД, частично совместимых с dBase по форматам данных.