Контрольная работа: Интернет, системы адресации. Информационная система "Кадровый учет"
Некоторым недостатком иерархических моделей является их неэффективность при реализации отношений типа L:L, медленный доступ к сегментам данных нижних уровней иерархии и четкая ориентация только на определенные типы запросов и др. В связи с этим в настоящее время СУБД, базирующиеся на иерархических моделях, подвергаются существенным модификациям, позволяющим поддерживать более сложные типы структур и, в первую очередь, сетевые их модификации.
Сетевая модель во многом подобна иерархической и отличается от нее только тем, что допускает несколько входных сегментов наряду с возможностью наличия сегментов без входов с точки зрения иерархической структуры. На рис. 2 представлен простой пример сетевой структуры, полученной на основе модификации иерархической топологии (рис. 2).
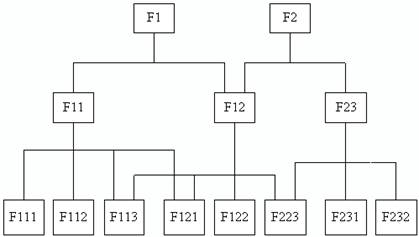
Рис. 2. Структура сетевой базы данных
Графическое отображение структуры связей сегментов такого типа моделей представляет собой сеть. Сегменты данных в сетевых базах данных могут иметь множественные связи с сегментами старшего уровня. В связи с тем, что в сетевых моделях имена и направление связей не так очевидны, как в иерархических моделях данных, они должны указываться при описании базы данных. В сетевых моделях данных любая запись старшего уровня может содержать данные, относящиеся к набору записей подчиненного уровня. Обращение к набору всех записей реализуется, начиная с записи старшего уровня. При этом нет необходимости, как это выполняется в иерархических моделях, осуществлять доступ к искомому набору записей через корневой сегмент. Обращение к данным возможно с любой точки доступа по связям.
Сетевые модели данных по сравнению с иерархическими являются более универсальным средством отображения во внутримашинной сфере структуры информации для разных предметных областей и это существенно расширяет сферу их применения. Достоинством сетевых моделей является отсутствие дублирования данных в различных элементах модели. Кроме того, технология работы с сетевыми моделями является более удобной, так как доступ к данным практически не имеет ограничений и возможен непосредственно к объекту любого уровня. Допустимы всевозможные запросы. Однако следует отметить, что ввиду сложности сетевых моделей, разработка СУБД на их основе предполагает использование опытных системных аналитиков и программистов. Кроме того, при использовании сетевых моделей более остро стоит проблема обеспечения сохранности информации в базе данных.
Реляционные модели данных отличаются от сетевых и иерархических простотой структур данных, удобным для пользователя табличным представлением и доступом к данным. Большинство современных баз данных в настоящее время разрабатываются на основе моделей подобного типа. Реляционную модель представления информации предложил в 1970 г. сотрудник фирмы IBM Эдгар Кодд. Данная модель позволяет выполнять все необходимые операции по запоминанию и поиску данных и обеспечивает целостность данных.
Модель основана на математическом понятии отношения, расширенном за счет значительного добавления специальной терминологии и развития соответствующей теории. В такой модели общая структура данных (отношений) может быть представлена в виде таблицы, в которой каждая строка значений (кортеж) соответствуют логической записи, а заголовки столбцов являются названиями полей (элементов) записи. Процедуры запоминания и поиска осуществляются с применением операций на множествах (объединение, пересечение, разность, произведение) и реляционных операций (выбрать, спроецировать, соединить, разделить). Отметим, что хотя реляционная модель и выглядит как совокупность связанных таблиц, но на физическом уровне данные хранятся в файлах, содержащих последовательности записей.
В реляционной модели каждому объекту предметной области соответствует одно или более отношений. При необходимости связь между объектами можно указать в явном виде. В такой связи (отношении) в качестве атрибутов указываются идентификаторы взаимосвязанных объектов. В реляционной модели объекты предметной области и связи между ними представляются одинаковыми конструкциями, что существенно упрощает модель.
Суть реляционной модели можно пояснить на следующем примере. Пусть в базе данных строительного предприятия имеются два файла: а) справочник железобетонных изделий; б) отчет о поставках изделий (рис. 3). Каждый из этих файлов содержит определенное число записей, состоящих из фиксированного числа полей (соответственно 4 и 4).
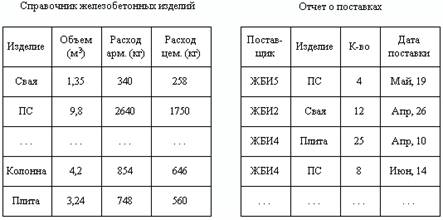
Рис. 3. Фрагмент реляционной модели базы данных
В данном фрагменте базы данных определены два отношения (файла), имеющие общий элемент значения поля Изделие. Операции реляционной алгебры могут объединить два типа записей по этому общему элементу. Например, в результате соединения запись ПС может представиться в следующем виде:
ПС <Объем (м3)><Расход арм. (кг)><Расход цем. (кг)>
<ЖБИ5><К-во><Дата поставки>….
Иначе говоря, к сведениям о изделии добавляются сведения о всех его поставках, имеющиеся в реляционной базе данных. Связь между записями допускается по нескольким полям, позволяя выполнять достаточно сложные манипуляции с данными. Поля данных, связывающих вместе две записи, могут быть уникальными для данной пары, но могут дублироваться и во многих других записях. Они могут повторяться неоднократно, связывая между собой записи. Аналогичным образом можно проиллюстрировать выполнение в реляционной модели операций проекции и селекции.
Чтобы не допустить потерь или искажения информации в реляционной базе данных необходим соответствующий контроль всех взаимосвязей записей. Этот контроль выполняется СУБД, которые в процессе работы постоянно пересчитывают число связей для каждой записи базы данных в прямом и обратном направлениях. При больших объемах баз данных осуществление такого контроля может потребовать существенных затрат машинного времени.
2. Практическое задание
В данной задаче для формирования базы данных используются следующие показатели:
• Ф.И.О.;
• Табельный номер;
• Код подразделения;
• Наименование подразделения;
• Дата рождения;
• Образование;
• Должность;
• Разряд;
• Адрес
• Кол-во детей;