Курсовая работа: Антивірусні програми та архівування даних
Наращивается, позволяя поддерживать тысячи пользователей
Простая установка
Рациональная и удобная работа
Имеющиеся отчеты отвечают основным административным нуждам
Поддержка клиента Linux®
Улучшенная защита от шпионского и рекламного ПО
Автоматическая блокировка установки шпионского ПО
Обнаружение и удаление скрытого шпионского ПО
Отображение степени влияния шпионского ПО на основе матрицы рисков Symantec (Risk Impact Matrix)
Улучшенная защита от последствий деятельности шпионского ПО
Средства защиты от вмешательства Symantec предотвращают несанкционированный доступ к антивирусу и атак на него, защищая пользователей от тех вирусов, которые пытаются заблокировать меры безопасности.
Поддерживается Symantec™ Security Response, лучшей в мире организацией по исследованию интернета и технической поддержке.»
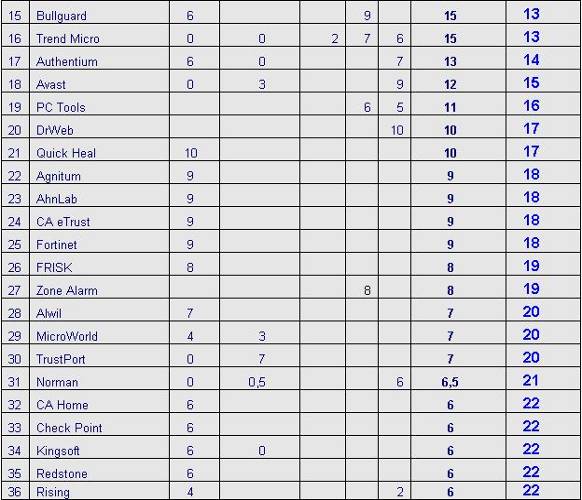

Таблиця 1. Результатами тестування антивірусних програм станом на квітень 2009
2. Архівування файлів
2.1 Деякі відомості про архівацію
Під час роботи на комп'ютері може відбутися втрата інформації, що знаходиться на магнітних дисках у файлах, з різних причин (фізичне псування, випадкове вилучення, руйнування вірусом та н.).
Щоб зменшити можливі втрати інформації, створюють на дискетах архівні копії файлів. Однак копії займають стільки ж місця на дискеті, скільки і вихідні файли. І якщо обсяги файлів, що копіюються, великі, то знадобиться багато дискет. Тому різними фірмами були розроблені спеціальні програми-архіватори. Вони дають змогу заощаджувати місце на архівних дискетах завдяки ущільненню інформації й об'єднують групи файлів в один архівний файл.
Архівний файл — це файл або група файлів, записаних у стисненому вигляді в єдиний файл, з якого їх можна добути у початковому вигляді. Характерною особливістю більшості типів даних є їх надлишковість. Ступінь надлишковості даних залежить від типу даних. Наприклад, для відеоданих ступінь надлишковості в декілька разів більша ніж для графічних даних, а ступінь надлишковості графічних даних, у свою чергу, більша за ступінь надлишковості текстових даних. Іншим фактором, що впливає на ступінь надлишковості є прийнята система кодування. Прикладом систем кодування можуть бути звичайні мови спілкування, які є ні чим іншим, як системами кодування понять та ідей для висловлення думок. Так, встановлено, що кодування текстових даних за допомогою засобів української мови дає в середньому надлишковість на 20-25% більшу ніж кодування аналогічних даних засобами англійської мови.
Для людини надлишковість даних часто пов'язана з якістю інформації, оскільки надлишковість, як правило, покращує зрозумілість та сприйняття інформації. Однак, коли мова йде про зберігання та передачу інформації засобами комп'ютерної техніки, то надлишковість відіграє негативну роль, оскільки вона приводить до зростання вартості зберігання та передачі інформації. Особливо актуальною є ця проблема у випадку необхідності обробки величезних обсягів інформації при незначних об'ємах носіїв даних. У зв'язку з цим постійно виникає проблема позбавлення надлишковості або стиснення даних. Коли методи стиснення даних застосовуються до готових файлів, то часто замість терміну "стиснення даних" вживають термін "архівування даних", стиснений варіант даних називають архівом, а програмні засоби, що реалізують методи стиснення називаються архіваторами.
В залежності від того, в якому об'єкті розміщені дані, що підлягають стисненню розрізняють:
1. Стиснення (архівування) файлів : використовується для зменшення розмірів файлів при підготовці їх до передавання каналами зв'язку або до транспортування на зовнішніх носіях малої ємності;
2. Стиснення (архівування) папок : використовується як засіб зменшення обсягу папок перед довготерміновим зберіганням, наприклад, при резервному копіюванні;
3. Стиснення (ущільнення) дисків : використовується для підвищення ефективності використання дискового простору шляхом стиснення даних при записі їх на носії інформації (як правило, засобами операційної системи).
Існує багато практичних алгоритмів стиснення даних, але всі вони базуються на трьох теоретичних способах зменшення надлишковості даних. Перший спосіб полягає в зміні вмісту даних, другий - у зміні структури даних, а третій - в одночасній зміні як структури, так і вмісту даних.
Якщо при стисненні даних відбувається зміна їх вмісту, то метод стиснення є незворотнім, тобто при відновленні (розархівуванні) даних з архіву не відбувається повне відновлення інформації. Такі методи часто називаються методами стиснення з регульованими втратами інформації. Зрозуміло, що ці методи можна застосовувати тільки для таких типів даних, для яких втрата частини вмісту не приводить до суттєвого спотворення інформації. До таких типів даних відносяться відео - та аудіо дані, а також графічні дані. Методи стиснення з регульованими втратами інформації забезпечують значно більший ступінь стиснення, але їх не можна застосовувати до текстових даних. Прикладами форматів стиснення з втратами інформації можуть бути: JPEG (Joint Photographic Experts Group) для графічних даних; MPG - для для відеоданих; MP3 - для аудіоданих.
Якщо при стисненні даних відбувається тільки зміна структури даних, то метод стиснення є зворотнім. У цьому випадкові з архіву можна відновити інформацію повністю. Зворотні методи стиснення можна застосовувати до будь-яких типів даних, але вони дають менший ступінь стиснення у порівнянні з незворотними методами стиснення. Приклади форматів стиснення без втрати інформації: GIF (Graphics Interchange Format), TIFF (Tagged Image File Format) - для графічних даних; AVI - для відеоданих; ZIP, ARJ, RAR, CAB, LH - для довільних типів даних. Існує багато різних практичних методів стиснення без втрати інформації, які, як правило, мають різну ефективність для різних типів даних та різних обсягів. Однак, в основі цих методів лежать три теоретичних алгоритми:
· алгоритм RLE (Run Length Encoding);
· алгоритми групи KWE(KeyWord Encoding);
· алгоритм Хафмана.
2.2 Алгоритм RLE
В основі алгоритму RLE лежить ідея виявлення послідовностей даних, що повторюються, та заміни цих послідовностей більш простою структурою, в якій вказується код даних та коефіцієнт повторення. Наприклад, нехай задана така послідовність даних, що підлягає стисненню:
1 1 1 1 2 2 3 4 4 4