Курсовая работа: Кэш-память
Концепция кэш-памяти возникла раньше чем архитектура IBM/360, и сегодня кэш-память имеется практически в любом классе компьютеров, а в некоторых компьютерах - во множественном числе.
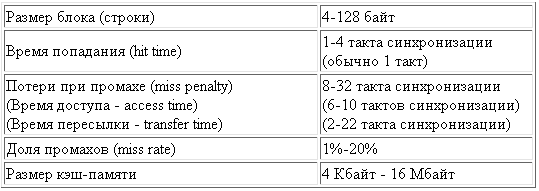
Рис. 2. Типовые значения ключевых параметров для кэш-памяти рабочих станций и серверов
Все термины, которые были определены раньше могут быть использованы и для кэш-памяти, хотя слово "строка" (line) часто употребляется вместо слова "блок" (block).
На рисунке 2 представлен типичный набор параметров, который используется для описания кэш-памяти.
Рассмотрим организацию кэш-памяти более детально, отвечая на четыре вопроса об иерархии памяти.
1. Где может размещаться блок в кэш-памяти?
Принципы размещения блоков в кэш-памяти определяют три основных типа их организации:
Если каждый блок основной памяти имеет только одно фиксированное место, на котором он может появиться в кэш-памяти, то такая кэш-память называется кэшем с прямым отображением (directmapped). Это наиболее простая организация кэш-памяти, при которой для отображение адресов блоков основной памяти на адреса кэш-памяти просто используются младшие разряды адреса блока. Таким образом, все блоки основной памяти, имеющие одинаковые младшие разряды в своем адресе, попадают в один блок кэш-памяти, т.е.
(адрес блока кэш-памяти) =
(адрес блока основной памяти) mod (число блоков в кэш-памяти)
Если некоторый блок основной памяти может располагаться на любом месте кэш-памяти, то кэш называется полностью ассоциативным (fullyassociative).
Если некоторый блок основной памяти может располагаться на ограниченном множестве мест в кэш-памяти, то кэш называется множественно-ассоциативным (setassociative). Обычно множество представляет собой группу из двух или большего числа блоков в кэше. Если множество состоит из n блоков, то такое размещение называется множественно-ассоциативным с n каналами (n-waysetassociative). Для размещения блока прежде всего необходимо определить множество. Множество определяется младшими разрядами адреса блока памяти (индексом):
(адрес множества кэш-памяти) =
(адрес блока основной памяти) mod (число множеств в кэш-памяти)
Далее, блок может размещаться на любом месте данного множества.
Диапазон возможных организаций кэш-памяти очень широк: кэш-память с прямым отображением есть просто одноканальная множественно-ассоциативная кэш-память, а полностью ассоциативная кэш-память с m блоками может быть названа m-канальной множественно-ассоциативной. В современных процессорах как правило используется либо кэш-память с прямым отображением, либо двух- (четырех-) канальная множественно-ассоциативная кэш-память.
2. Как найти блок, находящийся в кэш-памяти?
У каждого блока в кэш-памяти имеется адресный тег, указывающий, какой блок в основной памяти данный блок кэш-памяти представляет. Эти теги обычно одновременно сравниваются с выработанным процессором адресом блока памяти.
Кроме того, необходим способ определения того, что блок кэш-памяти содержит достоверную или пригодную для использования информацию. Наиболее общим способом решения этой проблемы является добавление к тегу так называемого бита достоверности (validbit).
Адресация множественно-ассоциативной кэш-памяти осуществляется путем деления адреса, поступающего из процессора, на три части: поле смещения используется для выбора байта внутри блока кэш-памяти, поле индекса определяет номер множества, а поле тега используется для сравнения. Если общий размер кэш-памяти зафиксировать, то увеличение степени ассоциативности приводит к увеличению количества блоков в множестве, при этом уменьшается размер индекса и увеличивается размер тега.
3. Какой блок кэш-памяти должен быть замещен при промахе?
При возникновении промаха, контроллер кэш-памяти должен выбрать подлежащий замещению блок. Польза от использования организации с прямым отображением заключается в том, что аппаратные решения здесь наиболее простые. Выбирать просто нечего: на попадание проверяется только один блок и только этот блок может быть замещен. При полностью ассоциативной или множественно-ассоциативной организации кэш-памяти имеются несколько блоков, из которых надо выбрать кандидата в случае промаха. Как правило для замещения блоков применяются две основных стратегии: случайная и LRU.
В первом случае, чтобы иметь равномерное распределение, блоки-кандидаты выбираются случайно. В некоторых системах, чтобы получить воспроизводимое поведение, которое особенно полезно во время отладки аппаратуры, используют псевдослучайный алгоритм замещения.
Во втором случае, чтобы уменьшить вероятность выбрасывания информации, которая скоро может потребоваться, все обращения к блокам фиксируются. Заменяется тот блок, который не использовался дольше всех (LRU - Least-RecentlyUsed).
Достоинство случайного способа заключается в том, что его проще реализовать в аппаратуре. Когда количество блоков для поддержания трассы увеличивается, алгоритм LRU становится все более дорогим и часто только приближенным. На рисунке 3 показаны различия в долях промахов при использовании алгоритма замещения LRU и случайного алгоритма.

Рис. 3. Сравнение долей промахов для алгоритма LRU и случайного алгоритма замещения
при нескольких размерах кэша и раз?