Курсовая работа: ЛИСП-реализация основных операций над базами данных
Пример 4.
Из таблицы сотрудники (Таблица 1) необходимо удалить сотрудников Сидоренко и Владимирова.
Решение:
Просматриваем все записи, находим фамилию Сидоренко – удаляем запись, аналогично удаляем Владимирова.
Таблица 6. Результат выполнения операции удаления
| Сотрудники | Зарплата |
| Сергиенко | 6540 |
| Петров | 5700 |
| Иванов | 8200 |
| Сидоров | 16100 |
| Николенко | 7650 |
2 Математические и алгоритмические основы решения задачи
2.1 Выполнение основных операций над базами данных
Опишем, каким образом выполняется запрос пользователя на вставку, удаление и операцию модификации.
В случае операции вставки сначала считываются с файла новые данные для добавления к базе данных. Устанавливается позиция добавления данных. Выполняется операция вставки.
Для выполнения операции удаления данных, нужно сначала найти эти данные, затем удалить.
Операция модификации может рассматриваться как операция удаления, следующая за операцией вставки. Поэтому правила, применяемые для операций удаления и вставки, также применяются и для операции модификации.
2.2 Скорость операций обновления
На уровне логического моделирования мы определяем реляционные отношения и атрибуты этих отношений. На этом уровне мы не можем определять какие-либо физические структуры хранения (индексы, хеширование и т.п.). Единственное, чем мы можем управлять - это распределением атрибутов по различным отношениям. Можно описать мало отношений с большим количеством атрибутов, или много отношений, каждое из которых содержит мало атрибутов. Таким образом, необходимо попытаться ответить на вопрос - влияет ли количество отношений и количество атрибутов в отношениях на скорость выполнения операций обновления данных. Такой вопрос, конечно, не является достаточно корректным, т.к. скорость выполнения операций с базой данных сильно зависит от физической реализации базы данных. Тем не менее, попытаемся качественно оценить это влияние при одинаковых подходах к физическому моделированию.
В базах данных, требующих постоянных изменений (складской учет, системы продаж билетов и т.п.) производительность определяется скоростью выполнения большого количества небольших операций вставки, обновления и удаления.
Рассмотрим операцию вставки записи в таблицу. Вставка записи производится в одну из свободных страниц памяти, выделенной для данной таблицы. Если для таблицы не созданы индексы, то операция вставки выполняется фактически с одинаковой скоростью независимо от размера таблицы и от количества атрибутов в таблице. Если в таблице имеются индексы, то при выполнении операции вставки записи индексы должны быть перестроены. Таким образом, скорость выполнения операции вставки уменьшается при увеличении количества индексов у таблицы и мало зависит от числа строк в таблице.
Рассмотрим операции обновления и удаления записей из таблицы. Прежде, чем обновить или удалить запись, ее необходимо найти. Если таблица не индексирована, то единственным способом поиска является последовательное сканирование таблицы в поиске нужной записи. В этом случае, скорость операций обновления и удаления существенно увеличивается с увеличением количества записей в таблице и не зависит от количества атрибутов. Но на самом деле неиндексированные таблицы практически никогда не используются. Для каждой таблицы обычно объявляется один или несколько индексов, соответствующий потенциальным ключам. При помощи этих индексов поиск записи производится очень быстро и практически не зависит от количества строк и атрибутов в таблице (хотя, конечно, некоторая зависимость имеется). Если для таблицы объявлено несколько индексов, то при выполнении операций обновления и удаления эти индексы должны быть перестроены, на что тратится дополнительное время. Таким образом, скорость выполнения операций обновления и удаления также уменьшается при увеличении количества индексов у таблицы и мало зависит от числа строк в таблице.
Можно предположить, что чем больше атрибутов имеет таблица, тем больше для нее будет объявлено индексов. Эта зависимость, конечно, не прямая, но при одинаковых подходах к физическому моделированию обычно так и происходит. Таким образом, можно принять допущение, что чем больше атрибутов имеют отношения, разработанные в ходе логического моделирования, тем медленнее будут выполняться операции обновления данных, за счет затраты времени на перестройку большего количества индексов.
3 Функциональные модели и блок-схемы решения задачи
Функциональные модели и блок-схемы решения задачи представлены на рисунках 1, 2, 3, 4, 5.
Условные обозначения:
POS – позиция вставки;
LST – список сотрудников;
AT – добавляемый элемент;
FM – фамилия сотрудника;
PAYM – оклад сотрудника.
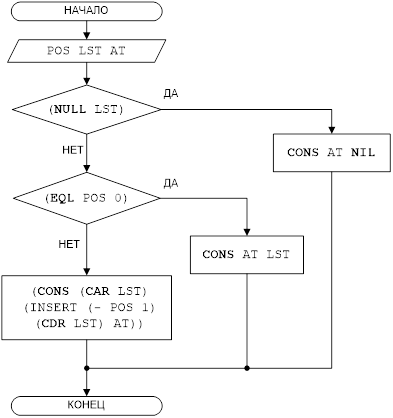
Рисунок 1 – Блок-схема решения задачи для функции INSERT
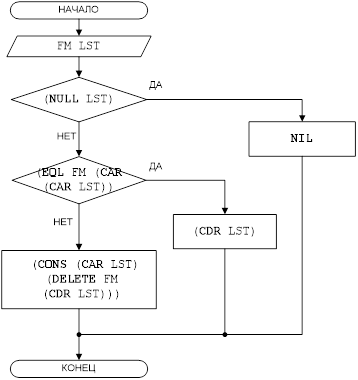
Рисунок 2 – Блок-схема решения задачи для функции DELETE