Курсовая работа: Основы распараллеливания программ, их динамический анализ
Задача анализатора в рамках системы автоматизации распараллеливания состоит в получении из программы необходимой для распараллеливания информации. В данной работе не рассматриваются вопросы, связанные с распараллеливанием программ для распределенной памяти.
Поэтому самая главная задача анализатора – собрать информацию о зависимостях по данным, присутствующим в программе. Эта информация необходима для того, чтобы выделить параллельные циклы, а также циклы с регулярными зависимостями, которые тоже, возможно, удастся распараллелить. Информация о зависимостях по данным нужна как при распараллеливании в модели общей памяти, так и в модели распределенной памяти.
3. Динамический анализ
3.1 Схема работы динамического анализатора
Общая схема работы динамического анализатора показана на Рисунке 1. На первом этапе в исходный текст программы вставляются вызовы трассировочных функций, позволяющих анализатору получать информацию о ходе выполнения программы. Набор трассировочных функций может меняться в зависимости от целей и используемого алгоритма анализа. Но как минимум трассировочные вызовы вставляются на все доступы к памяти, входы и выходы циклов, изменения индексных переменных в циклах.
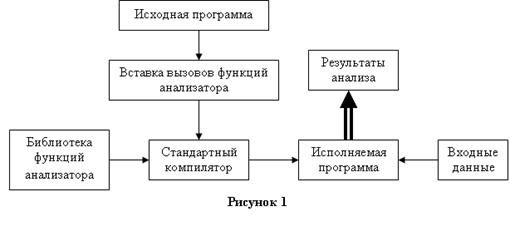
Далее полученная программа поступает на вход стандартного компилятора и затем запускается на различных наборах входных данных. По полученной трассировочной информации анализатор определяет зависимости между операторами в исходной программе.
Возможен вариант, когда инструментируется не вся программа, а некоторый фрагмент. В этом случае в качестве результатов будут получены только зависимости между операторами, попавшими в инструментированную часть программы. Это может быть полезно, если динамический анализ используется для уточнения результатов, полученных, например, с помощью статического анализатора.
Далее рассматриваются два возможных алгоритма динамического анализа.
3.2 Динамический анализ с использованием дерева контекстов
Эта схема анализа описана в работе [4] и в несколько измененном виде приводится здесь.
Введем следующую терминологию.
Дерево контекстов (context tree) CV(p) программы p — дерево, состоящее из вершин следующих типов: функция, цикл, оператор вызова функции или доступа к памяти, условный оператор, и другие типы операторов, присутствующие в языке. Между двумя вершинами есть ребро, если одна из них непосредственно вызывает другую. Корень дерева – функция main(), основное тело программы или другое аналогичное понятие из используемого языка программирования.
Контекст — это путь от корня до любой вершины дерева контекстов.
Пусть вершина S(a) соответствует оператору доступа к памяти a. Контекст CV(a) оператора a — путь от корня дерева контекстов к вершине S(a).
Контекст функции (цикла) — путь от корня дерева контекстов к вершине, соответствующей этой функции (циклу).
Рассмотрим пример.
int A[10], B[10];
void main() {
for (int i=0; i<10; i++)/* f1 */
proc(i);/* st1 */
}
void proc(int i) {
for (int m=0; m<10; m++) {/* f2 */
if (i%2 == 0)/* if1 */
A[m] = ...;/* st2 */
else
... = A[m];/* st3 */