Курсовая работа: Проектирование компилятора
Блок-схема метода простого рехэширования представлена на рисунке 1.1.
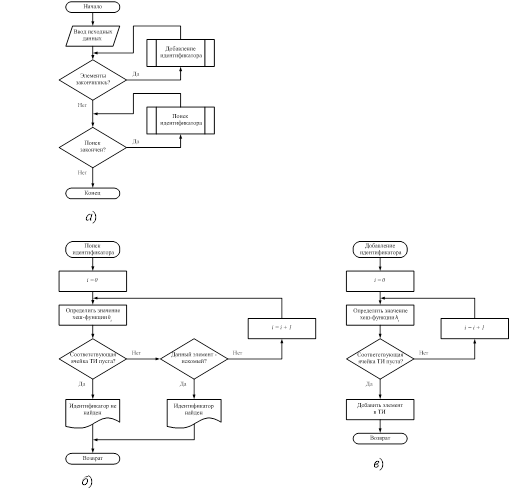
Рис. 1.1 – Блок-схема метода простого рехэширования с помощью произведения
а ) – Блок-схема алгоритма простого рехэширования с помощью произведения; б ) – Блок-схема функции поиска идентификатора;
в ) – Блок-схема функции добавления идентификатора
2 Проектирование лексического анализатора
2.1 Назначение лексического анализатора
Лексический анализатор (или сканер) – это часть-компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора.
Лексема (лексическая единица языка) – это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка. Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и т. п. Состав возможных лексем каждого конкретного языка программирования определяется синтаксисом этого языка.
С теоретической точки зрения лексический анализатор не является обязательной, необходимой частью компилятора. Его функции могут выполняться на этапе синтаксического анализа. Однако существует несколько причин, исходя из которых в состав практически всех компиляторов включают лексический анализ.
Это следующие причины:
- упрощается работа с текстом исходной программы на этапе синтаксического разбора и сокращается объем обрабатываемой информации, так как лексический анализатор структурирует поступающий на вход исходный текст программы и удаляет всю незначащую информацию;
- для выделения в тексте и разбора лексем возможно применять простую, эффективную и хорошо проработанную теоретически технику анализа, в то время как на этапе синтаксического анализа конструкций исходного языка используются достаточно сложные алгоритмы разбора;
- лексический анализатор отделяет сложный по конструкции синтаксический анализатор от работы непосредственно с текстом исходной программы, структура которого может варьироваться в зависимости от версии входного языка - при такой конструкции компилятора при переходе от одной версии языка к другой достаточно только перестроить относительно простой лексический анализатор.
Функции, выполняемые лексическим анализатором, и состав лексем, которые он выделяет в тексте исходной программы, могут меняться в зависимости от версии компилятора. В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев и незначащих пробелов, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, знаков операций, разделителей и ключевых (служебных) слов входного языка.
В большинстве компиляторов лексический и синтаксический анализаторы - это взаимосвязанные части. Где провести границу между лексическим и синтаксическим анализом, какие конструкции анализировать сканером, а какие – синтаксическим распознавателем, решает разработчик компилятора. Как правило, любой анализ стремятся выполнить на этапе лексического разбора входной программы, если он может быть там выполнен. Возможности лексического анализатора ограничены по сравнению с синтаксическим анализатором, так как в его основе лежат более простые механизмы.
2.2 Таблица лексем и содержащаяся в ней информация
Результатом работы лексического анализатора является перечень всех найденных в тексте исходной программы лексем с учетом характеристик каждой лексемы. Этот перечень лексем можно представить в виде таблицы, называемой таблицей лексем. Каждой лексеме в таблице лексем соответствует некий уникальный условный код, зависящий от типа лексемы, и дополнительная служебная информация. Таблица лексем в каждой строке должна содержать информацию о виде лексемы, ее типе и, возможно, значении. Обычно структуры данных, служащие для организации такой таблицы, имеют два поля: первое - тип лексемы, второе - указатель на информацию о лексеме.
Кроме того, информация о некоторых типах лексем, найденных в исходной программе, должна помешаться в таблицу идентификаторов (или в одну из таблиц идентификаторов, если компилятор предусматривает различные таблицы идентификаторов для различных типов лексем).
Не следует путать таблицу лексем и таблицу идентификаторов - это две принципиально разные таблицы, обрабатываемые лексическим анализатором.
Таблица лексем фактически содержит весь текст исходной программы, обработанный лексическим анализатором. В нее входят все возможные типы лексем, кроме того, любая лексема может встречаться в ней любое количество раз. Таблица идентификаторов содержит только определенные типы лексем – идентификаторы и константы. В нее не попадают такие лексемы, как ключевые (служебные) слова входного языка, знаки операций и разделители. Кроме того, каждая лексема (идентификатор или константа) может встречаться в таблице идентификаторов только один раз. Также можно отметить, что лексемы в таблице лексем обязательно располагаются в том же порядке, что и в исходной программе (порядок лексем в ней не меняется), а в таблице идентификаторов лексемы располагаются в любом порядке так, чтобы обеспечить удобство поиска.
2.3 Построение лексических анализаторов (сканеров)
Лексический анализатор имеет дело с такими объектами, как различного рода константы и идентификаторы (к последним относятся и ключевые слова). Язык описания констант и идентификаторов в большинстве случаев является регулярным, то есть может быть описан с помощью регулярных грамматик. Распознавателями для регулярных языков являются конечные автоматы (КА). Существуют правила, с помощью которых для любой регулярной грамматики может быть построен КА, распознающий цепочки языка, заданного этой грамматикой.
Любой КА может быть задан с помощью пяти параметров: M(Q,∑,δ,qo,F),
где:
Q - конечное множество состояний автомата;
∑ - конечное множество допустимых входных символов (входной алфавит КА);
δ - заданное отображение множества Q*∑ во множество подмножеств P(Q)δ: Q*∑→ P(Q) (иногда δ называют функцией переходов автомата);
q0 Q - начальное состояние автомата;
F Q. - множество заключительных состояний автомата.
Другим способом описания КА является граф переходов – графическое представление множества состояний и функции переходов КА. Граф переходов КА – это нагруженный однонаправленный граф, в котором вершины представляют состояния КА, дуги отображают переходы из одного состояния в другое, а символы нагрузки (пометки) дуг соответствуют функции перехода КА. Если функция перехода КА предусматривает переход из состояния q в q' по нескольким символам, то между ними строится одна дуга, которая помечается всеми символами, по которым происходит переход из q в q'.
Недетерминированный КА неудобен для анализа цепочек, так как в нем могут встречаться состояния, допускающие неоднозначность, то есть такие, из которых выходит две или более дуги, помеченные одним и тем же символом. Очевидно, что программирование работы такого КА - нетривиальная задача. Для простого программирования функционирования КА M(Q,∑,δ,qo,F) он должен быть детерминированным - в каждом из возможных состояний этого КА для любого входного символа функция перехода должна содержать не более одного состояния.
Доказано, что любой недетерминированный КА может быть преобразован в детерминированный КА так, чтобы их языки совпадали (говорят, что эти КА эквивалентны).
Кроме преобразования в детерминированный КА любой КА может быть минимизирован - для него может быть построен эквивалентный ему детерминированный КА с минимально возможным количеством состояний.
Можно написать функцию, отражающую функционирование любого детерминированного КА. Чтобы запрограммировать такую функцию, достаточно иметь переменную, которая бы отображала текущее состояние КА, а переходы из одного состояния в другое на основе символов входной цепочки могут быть построены с помощью операторов выбора. Работа функции должна продолжаться до тех пор, пока не будет достигнут конец входной цепочки. Для вычисления результата функции необходимо по ее завершении проанализировать состояние КА. Если это одно из конечных состояний, то функция выполнена успешно и входная цепочка принимается, если нет, то входная цепочка не принадлежит заданному языку.