Курсовая работа: Разработка и отладка формального языка
1. Выделяет лексические единицы.
2. Классифицирует лексические единицы.
3. Определяет лексические ошибки;
4. Создает некоторые внутренние формы представления – таблицы стандартных символов (ТСС).
Построим обобщенный автомат для всего сканера (схема сканера). Для этого объединим начальные символы описания всех лексем в стартовую вершину. Схема сканера приведена нa Рис. 12.
В данном сканере использованы следующие сокращения:
A – входная цепочка;
NA – количество символов входной цепочки;
TL – текущая литера;
NTL – номер текущей литеры;
KTL – класс текущей литеры;
TLE – тип лексической единицы;
LE – лексическая единица;
MDLE – максимальная длина лексической единицы;
NLE – текущая длинна LE;
ALE – компонента записи ТСС, которая определяет адрес лексической единицы в соответствующей таблице.
На рис. 12 изображена схема сканера
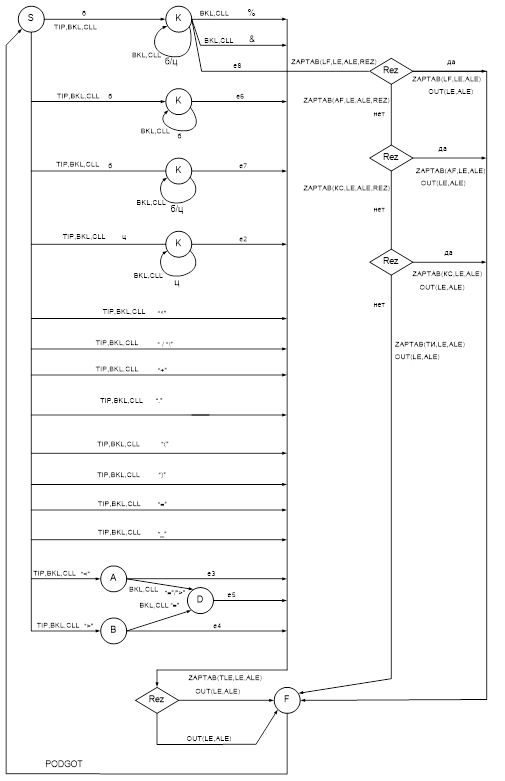
Рис. 12. Схема сканера
Семантические подпрограммы сканера
Конечный автомат необходимо доопределить семантическими подпрограммами для того, чтобы он был преобразован в сканер.
В основе работы семантических подпрограмм лежат простейшие действия по преобразованию строк:
1) выделение текущей литеры;
2) объединение строк;
3) выполнение арифметических операций.
В данном сканере задействованы следующие подпрограммы:
Подпрограмма PODGOT (подготовка):
NTL = 0;
NLE = 0;