Курсовая работа: Розробка та реалізація компонентів системного програмного забезпечення
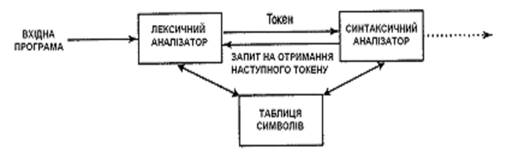
Рис. 2. Взаємодія лексичного і синтаксичного аналізаторів
При виділенні лексеми вона розпізнається та записується у таблицю лексем за допомогою відповідного номера лексеми, що є унікальним для кожної лексеми із усього можливого їх набору. Це дає можливість наступним фазам компіляції звертатись до лексеми не як до послідовності символів, а як до унікального номера лексеми, що значно спрощує роботу синтаксичного аналізатора: легко перевіряти належність лексеми до відповідної синтаксичної конструкції та є можливість легкого перегляду програми, як вгору, так і вниз, від текучої позиції аналізу. Також в таблиці лексем ведуться записи, щодо рядка відповідної лексеми (для локалізації місця помилки) та інша додаткова інформація.
При лексичному аналізі виявляються і відзначаються лексичні помилки (наприклад, недопустимі символи і неправильні ідентифікатори). Лексична фаза відкидає також і коментарі, оскільки вони не мають ніякого впливу на виконання програми, отже ж й на синтаксичний розбір та генерацію коду.
Лексичний аналізатор (сканер) не обов’язково обробляє всю програму до початку всіх інших фаз. Якщо лексичний аналіз не виділяється як окрема фаза компіляції, а є частиною синтаксичного аналізу, то лексична обробка тексту програми виконується по мірі необхідності по запиту синтаксичного аналізатора.
Є ряд причин, по яких фаза аналізу компіляції розділяється на лексичний і синтаксичний аналізи:
1.1 Мабуть, найважливішою причиною є спрощення розробки. Відділення лексичного аналізатора від синтаксичного часто дозволяє спростити одну з фаз аналізу. Наприклад, включення в синтаксичний аналізатор коментарів і пропусків істотно складніше, ніж видалення їх лексичним аналізатором. При створенні нової мови розділення лексичних і синтаксичних правил може привести до більш чіткої і ясної побудови мови.
1.2 Збільшується ефективність компілятора. Окремий лексичний аналізатор дозволяє створити спеціалізований і потенційно більш ефективний процесор для вирішення поставленої задачі. Оскільки на читання початкової програми і розбір її на токени витрачається багато часу, спеціалізовані технології буферизації і обробки токенів можуть істотно підвищити продуктивність компілятора.
1.3 Збільшується переносимість компілятора. Особливості вхідного алфавіту і інші специфічні характеристики пристроїв, що використовуються, можуть обмежувати можливості лексичного аналізатора. Наприклад, таким чином може бути вирішена проблема спеціальних нестандартних символів, таких як Т в Pascal.
Існує ряд спеціалізованих інструментів, призначених для автоматизації побудови лексичних і синтаксичних аналізаторів (у тому випадку, коли вони розділені).
1.3 Синтаксичний аналіз
Синтаксичний аналіз – це процес, в якому досліджується послідовність лексем, яку повернув лексичний аналізатор, і визначається, чи відповідає вона структурним умовам, що сформульовані у визначені синтаксису мови.
Синтаксичний аналізатор – це частина компілятора, яка відповідає за виявлення основних синтаксичних конструкцій вхідної мови. В задачу синтаксичного аналізатора входить: знайти та виділити основні синтаксичні конструкції мови в послідовності лексем програми, встановити тип та правильність побудови кожної синтаксичної конструкції і представити синтаксичні конструкції у вигляді, зручному для подальшої генерації тексту результуючої програми. Крім того, важливою функцією є локалізація синтаксичних помилок. Як правило, синтаксичні конструкції мови програмування можуть бути описані за допомогою контекстно-вільних граматик. Розпізнавач дає відповідь на питання, належить чи ні, ланцюжок вхідних лексем заданій мові. Але задача синтаксичного аналізу не обмежується тільки такою перевіркою. Синтаксичний аналізатор повинен мати деяку результуючу мову, за допомогою якої він передає наступним фазам компіляції інформацію про знайдені і розібрані синтаксичні конструкції, якщо відокремлюється фаза генерації об’єктного коду.
Кожна мова програмування має правила, які визначають синтаксичну структуру коректних програм. В Pascal, наприклад, програма створюється з блоків, блок – з інструкцій, інструкції – з виразів, вирази – з токенів і т.д. Синтаксис конструкцій мови програмування може бути описаний за допомогою контекстно-вільних граматик або нотації БНФ (Backus-Naur Form, форма Бекуса-Наура). Граматики забезпечують значні переваги розробникам мов програмування і авторам компіляторів.
Граматика дає точну і при цьому просту для розуміння синтаксичну специфікацію мови програмування.
Для деяких класів граматик ми можемо автоматично побудувати ефективний синтаксичний аналізатор, який визначає, чи коректна структура початкової програми. Додатковою перевагою автоматичного створення аналізатора є можливість виявлення синтаксичних неоднозначностей та інших складних для розпізнавання конструкцій мови, які інакше могли б залишитися непоміченими на початкових фазах створення мови і його компілятора.
Правильно побудована граматика додає мові програмування структуру, яка сприяє полегшенню трансляції початкової програми в об'єктний код і виявленню помилок. Для перетворення описів трансляції, заснованих на граматиці мови, в робочій програмі є відповідний програмний інструментарій.
З часом мови еволюціонують, збагатившись новими конструкціями і виконуючи нові задачі. Додавання конструкцій в мову виявиться більш простою задачею, якщо існуюча реалізація мови заснована на його граматичному описі.
Є три основні типи синтаксичних аналізаторів граматик. Універсальні методи розбору, такі як алгоритми Кока-Янгера-Касамі або Ерлі, можуть працювати з будь-якою граматикою. Проте ці методи дуже неефективні для використання в промислових компіляторах. Методи, які звичайно використовуються в компіляторах, класифікуються як низхідні (зверху вниз, top-down) або висхідні (з низу до верху, bottom-up). Як видно з назв, низхідні синтаксичні аналізатори будують дерево розбору зверху вниз (до листя), тоді як висхідні починають з листя і йдуть до кореня. В обох випадках вхідний потік синтаксичного аналізатора сканується посимвольний зліва направо. Найефективніші низхідні і висхідні методи працюють тільки з підкласами граматик, проте деякі з цих підкласів, такі як LL- і LR-граматики, достатньо виразні для опису більшості синтаксичних конструкцій мов програмування. Реалізовані вручну синтаксичні аналізатори частіше працюють з LL-граматиками. Синтаксичні аналізатори для дещо більшого класу LR-граматик звичайно створюються за допомогою автоматизованих інструментів. Будемо вважати, що вихід синтаксичного аналізатора є деяким представленням дерева розбору вхідного потоку токенів, виданого лексичним аналізатором. На практиці є безліч задач, які можуть супроводжувати процес розбору, – наприклад, збір інформації про різні токени в таблиці символів, виконання перевірки типів і інших видів семантичного аналізу, а також створення проміжного коду. Всі ці задачі представлені одним блоком «Інші задачі початкової фази компіляції» рис. 3.
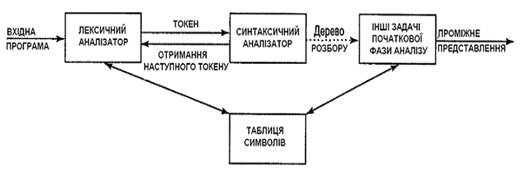
Рис. 3. Місце синтаксичного аналізатора в моделі компілятора
1.3.1 Обробка синтаксичних помилок
Якщо компілятор матиме справу виключно з коректними програмами, його розробка і реалізація істотно спрощуються. Проте дуже часто програмісти пишуть програми з помилками, і добрий компілятор повинен допомогти програмісту знайти їх і локалізувати. Примітно, що хоча помилки – явище надзвичайно поширене, лише в декількох мовах питання обробки помилок розглядалося ще на фазі створення мови. Наша цивілізація істотно відрізнялася б від свого нинішнього стану, якби в природних мовах були такі ж вимоги до синтаксичної точності, як і в мовах програмування.
Більшість специфікацій мов програмування, проте, не визначає реакції компілятора на помилки – це питання віддається на відкуп розробникам компілятора. Проте планування системи обробки помилок з самого початку роботи над компілятором може як спростити його структуру, так і поліпшити його реакцію на помилки.
Ми знаємо, що будь-яка програма потенційно містить безліч помилок самого різного рівня. Наприклад, помилки можуть бути:
• лексичними, такими як невірно записані ідентифікатори, ключові слова або оператори;
• синтаксичними, наприклад, арифметичні вирази з незбалансованими дужками;
• семантичними, такими як оператори, використані до несумісних операндів;
• логічними, наприклад нескінченна рекурсія.
Часто основні дії по виявленню помилок і відновленню після них концентруються у фазі синтаксичного аналізу. Одна з причин цього полягає в тому, що багато помилок за своєю природою є синтаксичними або виявляються, коли потік токенів, що йде від лексичного аналізатора, порушує визначаючі мова програмування граматичні правила. Друга причина полягає в точності сучасних методів розбору; вони дуже ефективно виявляють синтаксичні помилки в програмі. Визначення присутності в програмі семантичних або логічних помилок – задача набагато складніша.