Курсовая работа: Використання функціонального підходу при програмуванні розподілених задач для кластеру на прикладі технології DryadLINQ
dryadoutputdir="file: // \\hnode\Userdata\tmaliarchuk\output " />
</DryadLinqConfig>
Розберемо по частинам:
- hnode - ім’я головного вузла кластера
- XC\output - папка для збереження проміжних даних що створюються роботою Dryad
- file: // \\hnode\Userdata\tmaliarchuk\output - папка виводу результату
Як вже було зазначено локальний файл конфігурації знаходиться в папці проекту, він містить тільки шлях до глобального файлу конфігурації:
<DryadLinqConfig>
<DryadLinqRoot>
C: \Program Files\Microsoft Research DryadLINQ
</DryadLinqRoot>
</DryadLinqConfig>
За замовчуванням це C: \Program Files\Microsoft Research DryadLINQ.
2.3 Представлення колекцій даних
Дані в роботі Dryadнеобхідно представити у вигляді колекції. Для звичайного запитів LinqToObject це тип IEnumerable < T >. Це так би мовити колекція даних типу Т над якою можна виконувати такі операції як сортування, видобуток та інші функції які доступні в бібліотеці System. Linq. Проте після перелічених операції робота Dryad повертає не об’єкт типу IEnumerable < T >, а IQueryable<T>. IQueryable<T> наслідує IEnumerable < T >, протеці два типи колекцій працюють по різному:
IEnumerable<T> - представляється як ітераторпо колекції даних, які знаходяться на комп’ютері. Під час виконання програми об’єкт колекції компілюються локальним.net JIT компілятором, і ітератори використовуються для покращення виконання програми локально.
IQueryable<T> - представляється як запит по колекції даних. Під час виконання програми об’єкт колекції передається провайдеру DryadLINQ що транслює запити в роботу Dryad і повертає вже оброблені дані до програми. Це використовується для розподілених програм на кластері.
Під час виконання роботи Dryadна кластері вхідні дані представляються у вигляді PartitionedTable<T>. PartitionedTable<T> наслідує IQueryable<T>, а отже наслідує і всі методи IQueryable<T>. PartitionedTable<T> представляє дані ніби вони знаходяться на одному вузлі, проте в реальності вони розділені на частини та знаходяться не на одному вузлі.
2.4 Файл метаданих
Як вже було зазначено даний версія DryadLINQ не підтримує автоматичне розбиття даних та копіювання їх на вузли. Це необхідно зробити самостійно, або програмно, написавши додаткові процедури що будуть це виконувати. Отже множина розподілених даних полягає в наступних файлах:
- файл метаданих, який являться текстовим файлом що містить метадані які описують розподілені дані
- множини розподілених даних, вони можуть бути будь якого зручного для вашої програми формату включно бінарний формат.
Файл метеданих може приймати наступний вигляд (у випадку виконання роботи на 4 вузлах):
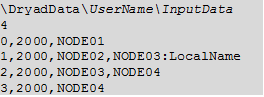
Файл метаданих має формат. pt і містить три розділи:
- папка та ім’я файлу - перша строчка описує стандартну папку з відкритим доступом і стандартне ім’я для часткових даних. Кожен вузол в кластері має папку DryadDataз відповідними правами доступу та кожна частина розподілених даних повинна міститися в цій папці на відповідних вузлах
- кількість частин - друга строчка описує кількість частин розподілених даних. В даному випадку 4
- опис розподілених даних - решта файлу. Одна строка - на одну частину. Кожна лінія містить три або більше елементів розподілених комою: номер частини даних (в десятковому вигляді), розмір частини, ім’я комп’ютерів де знаходяться ці дані.
У файлі метеданих не повинно бути жодних пробілів. Номер частин розподілених починається з 00000000. Розмір частини вказувати не обов’язково, тобто якщо при кожному новому виконанні роботи Dryad її розмір змінюється можна вказати нульовий розмір. Також певна чатина даних може не знаходитися в стандартній папці. У цьому випадку в рядку опису цієї частини після переліку вузлів де знаходиться ця частина необхідно поставити ": " та потім вказати ім’я папки та ім’я частини. Наприклад у випадку використання тільки однієї частини розподілених даних файл метаданих може бути наступним

Тут ми не вказуємо папку та ім’я за замовчуванням.