Лабораторная работа: Статистические методы обработки данных
Цель : Научиться основным методам обработки данных, представленных выборкой. Изучить графические представления данных. Овладеть навыками расчета с помощью ЭВМ основных числовых характеристик выборки.
Основным объектом исследования в эконометрике является выборка. Выборкой объема n называются числа х1 .х2 ….хn получаемые на практике при n – кратком повторении эксперимента в неизменных условиях. На практике выборку чаще всего представляют статистическим рядом. Для этого вся числовая ось, на которой лежат значения выборки, разбивается на k интервалов ( это число выбирается произвольно от 5 до 10), которые обычно равны, вычисляются середины интервалов zn и считается число элементов выборки, попадающих в каждый интервал n1 . статистическим рядом называется последовательность пар (z1 .n1 ). Рассмотрим решение задачи на ЭВМ и ППП EXCEL на следующей примере.
ПРИМЕР . Дана выборка чисел выручки магазина за 30 дней:
| 72 | 74 | 69 | 71 | 73 | 68 | 73 | 77 | 76 | 77 | 76 | 76 | 76 | 64 | 65 |
| 75 | 70 | 75 | 71 | 69 | 72 | 69 | 78 | 72 | 67 | 72 | 81 | 75 | 72 | 69 |
Построим статистический ряд, полигон, гистограмму и кумулятивную кривую.
Откроем книгу программы EXCEL. Введем в первый столбец (ячейки А1-А30) исходные данные. Определим область чисел, на какой лежат данные. Для этого найдем максимальный и минимальный элементы выборки. Введем в В1 «Максимум», а в В2 «Минимум», а в соседних ячейках С1 и С2 определим функции «МАХ» и «МIN», в качестве аргументов которых (в графе «число») обведем область данных (ячейки А1-А30). Результатом будут 64 и 81. видно, что все данные укладываются на отрезке [64;81]. Разделим его на 9 (выбирается произвольно от 5 до 10) интервалов:
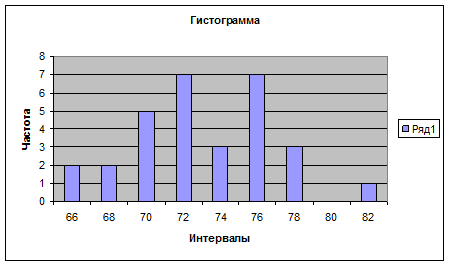
64-66; 66-68: 68-70: 70-72: 72-74, 74-76, 76-78, 78-80, 80-82. в ячейке D1-D10 вводим верхние границы интегралов группировки – числа 66, 68, 70, 72, 74, 76, 78, 80, 82. Для вычисления частот n1 используют функцию ЧАСТОТА, находящуюся в категории «Статистические». Введем ее в ячейку Е1. в строке «Массив данных» введем диапазон выборки (ячейки А1-А30). В строке «Двоичный массив» введем диапазон верхних границ интервалов группировки (ячейки D1-D9). Результат функции является массивом и выводится в ячейках Е1-Е9. для полного выбора (не только первого числа в Е1) нужно выделить ячейки Е1-Е9, обведя их мышью, и нажать F2, а далее одновременно CTRL+SHIFT+ENTER. Результат – частоты интервалов 2,2,5,7,3,7,3,0,1.
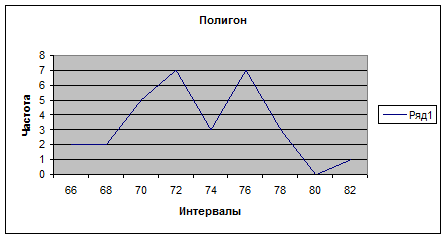
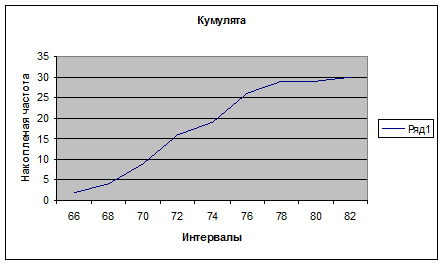
Для построения гистограммы нужно выбрать ВСТАВКА/ДИАГРАММА или нажать на соответствующий значок на основной панели (при этом курсор должен стоять в свободной ячейке) далее выбрать тип: ГИСТОГРАММА, вид по выборке, нажать «ДАЛЕЕ», в строке «ПОДПИСИ ОСИ Х» ввести интервалы ячейках D1-D5, нажать «ДАЛЕЕ» ввести название «ГИСТОГРАММА», подписи осей «ИНТЕВАЛЫ» и «ЧАСТОТА», нажать «ГОТОВО». Для создания полигона сделать то же самое, только вместо типа диаграммы «ГИСТОГРАММА», выбрать «ГРАФИК». Для построения кумулятивной кривой нужно посчитать накопленные частоты. Для этого в ячейку F1 вводим «=Е1», в F2 – вводим «=F1+Е2» и автозаполнением перетаскиваем эту ячейку до F9. далее строим график как и в случае полигона, но в строке «ДИАПАЗОН» вводим накопленные частоты, ссылаясь на F1- F9, а на вкладке «РЯД», в строке «ПОДПИСИ ОСИ Х» вводим интервалы в ячейках D1-D9.
Находим основные числовые характеристики выборки. Для их ввода выделяем два столбца, например G и H, в первом вводим название характеристики, во втором – функцию, в которой в качестве массива данных (строка»ЧИСЛО1»), указать ссылку на А1-А30
| Характеристика | Функция |
| Объем выборки | 30 |
| Выборочное среднее | 72,46666667 |
| Дисперсия | 15,63678161 |
| Стандартное отклонение | 3,954337063 |
| Медиана | 72 |
| Мода | 72 |
| Коэффициент эксцесса | -0,214617804 |
| Коэффициент асимметрии | -0,154098799 |
| Персентиль 40% | 72 |
| Персентиль 80% | 76 |
Существует другой способ вычисления числовых характеристик выборки. Для этого ставим курсор в свободную ячейку (например D11). Затем вызываем в меню «Сервис» подменю «Анализ данных». Если в меню «Сервис» отсутствует этот пункт, то в меню «Сервис» нужно выбрать пункт «Надстройки» м в нем поставить флажок напротив пункта «Пакет анализа». В окне «Анализ данных» нужно выбрать пункт «Описательная статистика». В появившемся окне в поле «Входной интервал» делаем ссылку на выборку А1-А23. Оставляем группирование «По столбцам» в разделе «Параметры вывода» ставим флажок на «Выходной интервал» и в соседнем поле создаем ссылку на верхнюю левую ячейку области вывода (например D11), ставим флажок напротив «Описательная статистика», нажимаем «ОК». результат – основные характеристики выборки (сделайте шире столбцов D, переместив его границу в заголовок).
Лабораторная работа № 2
ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ
Цель : Ознакомиться с методом проверки основных статистических гипотез, используемых в экономике, с помощью ЭВМ.
1. ПРОВЕРКА ГИПОТЕЗЫ О СООТВЕТСТВИИ (КРИТЕРИЙ СОГЛАСИЯ)
Используется для проверки предположения о том, что полученные в результате наблюдений данные соответствуют нормам. Рассматривается гипотеза о том, что отклонения от норм невелики, и ими можно пренебречь. При этом задается доверительная вероятность p которая имеет смысл вероятности не ошибиться при принятии гипотезы. Рассмотрим проверку на примере.
ПРИМЕР : 1. при производстве микросхем процессоров используются кристаллы кварца. Стандартом предусмотрено, чтобы 50% образцов не было обнаружено ни одного дефекта кристаллической структуры, у 15% - один дефект, у 13% - 2 дефекта, у 12% - 3 дефекта, у 10% более 3 дефектов. При анализе выборочной партии оказалось, что из 100 экземпляров распределение по дефектам партии оказалось, что из 1000 экземпляров распределение по дефектам следующего (вариант соответствует ЭВМ): Можно ли с вероятностью 0,99 считать, что партия соответствует стандарту?
Введем в А1 заголовок «НОРМА» и ниже в А2-А6 показатели – числа 500, 150, 130, 120, 100. в ячейку В1 введем заголовок «НАБЛЮДЕНИЯ» и ниже в В2-В6 наблюдаемые показатели 516, 148, 131, 110, 95. в третьем столбце вводятся формулы для критерия: С1 заголовок «КРИТЕРИЙ», в С2 формулу «=(А2-В2)*(А2-В2)/А2». Автозаполнением размножим эту формулу на С3-С6. в ячейку С7 запишем общее значение критерия – сумму столбца С2-С6. для этого поставим курсор в С6 и вызвав функцию в категории «Математический» найдем СУММ и в аргументе «Число 1» укажем ссылку на С2-С6. получиться результат критерия Z= 1,629692308. Для ответа на вопрос, соответствуют ли опытные показатели нормам, Z сравнивают с критическим значением Zkp. Вводим в D1 текст “критическое значение» в Е1 вводим функцию ХИ2ОБР (категория «Статистические») у которой два аргумента: «Вероятность» - вводим уровень значимости α =1-p и «Степени свободы» - вводят число n-1, где n – число норм). Результат 13,27670414. видно, что критическое значение больше критерия, следовательно опытные данные соответствуют стандартным и партия с заданной вероятностью можно отнести как соответствующую стандарту.
| Норма | Наблюдения | Критерий | Критическое значение | 13,27670414 |
| 500 | 516 | 0,512 | ||
| 150 | 148 | 0,026666667 | ||
| 130 | 131 | 0,007692308 | ||
| 120 | 110 | 0,833333333 | ||
| 100 | 95 | 0,25 | ||
| 1000 | 1,629692308 |
2. ПРОВЕРКА ГИПОТЕЗЫ О РАВЕНСТВЕ ДИСПЕРСИЙ
Используется в случае, если нужно проверить различается ли разброс данных (дисперсии) у двух выборов. Это может использоваться при сравнении точностей обработки деталей на двух станках, равномерности продаж товара в течении некоторого периода в двух городах и т.д. Для проверки статистической гипотезы, о равенстве дисперсий служит F – критерий Фишера. Основной характеристикой критерия является уровень значимости α, которой имеет смысла вероятности ошибиться, предполагая, что дисперсии и, следовательно, точность, различаются. Вместо α в задачах так же иногда задают доверительную вероятность p=1- α, имеющую смысл вероятности того, что дисперсии и в самом деле равны. Обычно выбирают критическое значение уровня значимости, например 0,05 или 0,1, и если α больше критического значения, то дисперсии считаются равными, в противном случае, различны. При этом критерий может быть односторонним, когда нужно проверить, что дисперсия конкретной выделенной выборки больше, чем у другой, и двусторонним, когда просто нужно показать, что дисперсии не равны. Существует два способа проверки таких гипотез. Рассмотрим их на примерах.
ПРИМЕР 2. четыре станка в цеху обрабатывают детали. Для проверки точности обработки, взяли выборку размеров деталей у каждого станка. Необходимо сравнить с помощью F-теста попарно точности обработки всех станков (рассмотреть пары 1-2, 1-3, 1-4, 2-3, 2-4, 3-4) и сделать вывод, для каких станков точности обработки (дисперсии) равны, для каких нет. Взять уровень значимости α=0,02.
| 1 станок | 29,1 | 26,2 | 30,7 | 33,8 | 33,6 | 35,2 | 23,4 | 29,3 | 33,3 | 26,7 |
| 2 станок | 29,0 | 28,9 | 34,0 | 29,7 | 39,4 | 28,5 | 35,9 | 32,6 | 37,1 | 28,0 |
| 3 станок | 25,7 | 27,5 | 25,4 | 28,9 | 29,9 | 30,1 | 29,0 | 36,6 | 24,8 | 27,8 |
| 4 станок | 32,1 | 31,0 | 27,2 | 29,3 | 30,4 | 31,7 | 30,4 | 27,3 | 35,7 | 31,5 |
Уровень значимости α=0,02. вводим данные выборок (без подписей) в 4 строчки в ячейки А1-J1 и А2-J2 и т.д. соответственно. Для вычисления ФТЕСТ (массив1;массив2). Вводим А5 подпись А5 «Уровень значимости», а в В5 функцию, ФТЕСТ, аргументами которой должны быть ссылки на ячейку А1-J1 и А2-J2 соответственно. Результат 0,873340161 говорит о том, что вероятность ошибиться, приняв гипотезу о различии дисперсий, около 0,9, что больше критического значения, заданного в условии задачи 0,02. следовательно, можно говорить что опытные данные с большей вероятностью подтверждают предположения о том, что дисперсии одинаковы и точность обработки станков одинакова, такие же результаты показало сравнение остальных пар. Следует отметить, что функции ФТЕСТ выходит уровень значимости двустороннего критерия и если нужно использовать односторонний, то результат необходимо уменьшить вдвое.
| 29,1 | 26,2 | 30,7 | 33,8 | 33,6 | 35,2 | 23,4 | 29,3 | 33,3 | 26,7 |
| 29 | 28,9 | 34 | 29,7 | 39,4 | 28,5 | 35,9 | 32,6 | 37,1 | 28 |
| 25,7 | 27,5 | 25,4 | 28,9 | 29,9 | 30,1 | 29 | 36,6 | 24,8 | 27,8 |
| 32,1 | 31 | 27,2 | 29,3 | 30,4 | 31,7 | 30,4 | 27,3 | 35,7 | 31,5 |
| Уровень значимости | |||||||||
| 1 - 2 | 0,873340161 | ||||||||
| 1 - 3 | 0,688084317 | ||||||||
| 1 - 4 | 0,190932274 | ||||||||
| 2 - 3 | 0,575576041 | ||||||||
| 2 - 4 | 0,144572063 | ||||||||
| 3 - 4 | 0,357739717 |
3. ПРОВЕРКА ГИПОТЕЗЫ О РАВЕНСТВЕ СРЕДНИХ
Используется для проверки предложения о том, что среднее значения двух показателей, представленных выборками, значимо различаются. Существует три разновидности критерия: один – для связанных выборок, и два для несвязных выборок (с одинаковыми и разными дисперсиями). Если выборки не связны, то предварительно нужно проверить гипотезу о равенстве дисперсий, чтобы определить, какой из критериев использовать. Так же как и в случае сравнения дисперсий имеются 2 способа решения задачи, которые рассмотрим на примере.
ПРИМЕР 3. имеются данные о количестве продаж товара в двух городах. Проверить на уровне значимости 0,01 статистическую гипотезу о том, что среднее число продаж товара в городах различно.
| 23 | 25 | 23 | 22 | 23 | 24 | 28 | 16 | 18 | 23 | 29 | 26 | 31 | 19 |
| 22 | 28 | 26 | 26 | 35 | 20 | 27 | 28 | 28 | 26 | 22 | 29 |
Используем пакет «Анализ данных». В зависимости от типа критерия выбирается один из трех: «Парный двухвыборочный t-тест для средних» - для связных выборок, и «Двухвыборочных t-тест с одинаковыми дисперсиями» или «Двухвыборочных t-тест с разными дисперсиями» - для несвязных выборок. Вызовите тест с одинаковыми дисперсиями, в открывшемся окне в полях «Интервал переменной 1» и «Интервал переменной 2» вводят ссылки на данные (А1-N1 и А2-L2, соответственно), если имеются подписи данных, то ставят флажок у надписи «Метки» (у нас их нет, поэтому флажок не ставится). Далее вводят уровень значимости в поле «Альфа» - 0,01. Поле «Гипотетическая средняя разность» оставляют пустыми. В разделе «Параметры вывода» ставят метку около «Выходной интервал» и поместив курсор в появившемся поле напротив надписи, щелкают левой кнопкой в ячейке В7. вывод результата будет осуществляться начиная с этой ячейки. Нажав на «ОК» появляется таблица результата. Сдвиньте границу между столбцами В и С, С и D, D и Е увеличив ширину столбцов В, С и D так, чтобы умещались все надписи. Процедура выводит основные характеристики выборки, t-статистику, критические значения этих статистик и критические уровни значимости «Р(Т<=t) одностороннее» и «Р(Т<=t) двухстороннее». Если по модулю t-статистика меньше критического, то средние показатели с заданной вероятностью равны. В нашем случае│-1,784242592│ < 2,492159469, следовательно, среднее число продаж значимо не отличается. Следует отметить, что если взять уровень значимости α=0,05, то результаты исследования будут совсем иными.
Двухвыборочный t-тест с одинаковыми дисперсиями | ||
| город 1 | город 2 | |
| Среднее | 23,57142857 | 26,41666667 |
| Дисперсия | 17,34065934 | 15,35606061 |
| Наблюдения | 14 | 12 |
| Объединенная дисперсия | 16,43105159 | |
| Гипотетическая разность средних | 0 | |
| df | 24 | |
| t-статистика | -1,784242592 | |
| P(T<=t) одностороннее | 0,043516846 | |
| t критическое одностороннее | 2,492159469 | |
| P(T<=t) двухстороннее | 0,087033692 | |
| t критическое двухстороннее | 2,796939498 | |
Лабораторная работа №3
ПАРНАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ
Цель : Освоить методы построения линейного уравнения парной регрессии с помощью ЭВМ, научиться получать и анализировать основные характеристики регрессионного уравнения.
Рассмотрим методику построения регрессионного уравнения на примере.
ПРИМЕР. Даны выборки факторов х i и у i . По этим выборкам найти уравнение линейной регрессии ỹ = ах + b . Найти коэффициент парной корреляции. Проверить на уровне значимости а = 0,05 регрессионную модель на адекватность.
| Х | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Y | 6,7 | 6,3 | 4,4 | 9,5 | 5,2 | 4,3 | 7,7 | 7,1 | 7,1 | 7,9 |
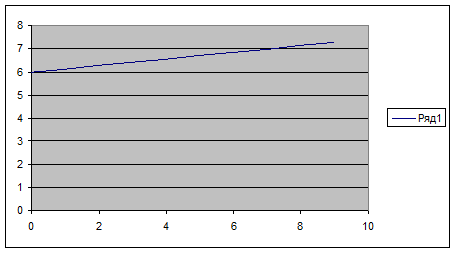
Для нахождения коэффициентов a и b уравнения регрессии служат функции НАКЛОН и ОТРЕЗОК, категории «Статистические». Вводим в А5 подпись «а=» а в соседнюю ячейку В5 вводим функцию НАКЛОН, ставим курсор в поле «Изв_знач_у» задаем ссылку на ячейки В2-K2, обводя их мышью. Результат 0,14303. Найдем теперь коэффициент b. Вводим в А6 подпись «b=», а в В6 функцию ОТРЕЗОК с теми же параметрами, что и функции НАКЛОН. Результат 5,976364. следовательно, уравнение линейной регрессии есть у=0,14303х+5,976364.
Построим график уравнения регрессии. Для этого в третью строчку таблицы введем значения функции в заданных точках Х (первая строка) – у(х1 ). Для получения этих значений используются функция ТЕНДЕНЦИЯ категории «Статистические». Вводим в А3 подпись «Y(X) и, поместив курсор в В3, вызываем функцию ТЕНДЕНЦИЯ. В полях «Изв_знач_у» и «Изв_знач_х» даем ссылку на В2-K2 и В1-K1. в поле «Нов_знач_х» вводим также ссылку на В1-K1. в поле «Константа» вводят 1, если уравнение регрессии имеет вид y = ax + b , и 0, если у=ах . В нашем случае вводим единицу. Функция ТЕНДЕНЦИЯ является массивом, поэтому для вывода всех ее значений выделяем область В3-K3 и нажимаем F2 и Ctrl+Shift+Enter. Результат – значения уравнения регрессии в заданных точках. Строим график. Ставим курсор в любую свободную клетку, вызываем мастер диаграмм, выбираем категорию «Точеная», вид графика – линия без точек (в нижнем правом углу), нажимаем «Далее», в поле «Диагноз» вводим ссылку на В3-K3. переходим на закладку «Ряд» и в поле «Значения Х» вводим ссылку на В1-K1, нажимаем «Готово». Результат – прямая линия регрессии. Посмотрим, как различаются графики опытных данных и уравнения регрессии. Для этого ставим курсор в любую свободную ячейку, вызываем мастер диаграмм, категория «График», вид графика – ломанная линия с точками (вторая сверху левая), нажимаем «Далее», в поле «Диапазон» вводим ссылку на вторую и третью строки В2-K3. переходим на закладку «Ряд» и в поле «Подписи оси Х» вводим ссылку на В1-K1, нажимаем «Готово». Результат – две линии (Синяя – исходные, красная – уравнение регрессии). Видно, что линии мало различаются между собой.
| а= | 0,14303 |
| b= | 5,976364 |
--> ЧИТАТЬ ПОЛНОСТЬЮ <--