Реферат: Алгоритм сжатия исторической информации
А.Ф. Оськин, В.И. Шайков
Нынешний этап развития исторической науки, как и науки вообще, характеризуется все возрастающим потоком информации. Обработку больших объемов информации с помощью компьютера нельзя эффективно организовать только путем совершенствования технических средств - увеличивая объемы памяти, сокращая время обращения к внешним носителям и т.д.. Необходимо совершенствовать также и методы организации информации, разрабатывая эффективные алгоритмы ее кодирования.
Что же такое информация? Одно из возможных определений этого понятия рассматривает информацию как "содержание связи между взаимодействующими материальными объектами, проявляющееся в изменении состояния этих объектов"[1].
Интересно отметить, что в теории информации отсутствует строгое определение понятия "информация". Необходимым и достаточным условием построения этой теории оказалось введение понятия количества информации.
Как же определяют количество информации? В классической теории информации игнорируются ценность, срочность и смысловое содержание информации, т.е. не принимаются в расчет качественные характеристики сообщений. Когда же не учитываются качественные характеристики, то имеет смысл говорить не о количестве информации, а о ее объеме. Следует отметить, что с этой точки зрения историческая информация имеет ряд особенностей. Для историка весьма важным является задача создания и сохранения в машиночитаемом архиве наиболее полной электронной копии нарративного источника. Если учесть сложность и неоднородность информации, характерные для исторического источника, а также быстро увеличивающееся число архивов, хранящих информацию в машиночитаемой форме, актуальной становится задача разработки принципов хранения информации. При этом весьма важным представляется поиск путей качественного улучшения методов кодирования и хранения информации.
Рассмотрению одного из таких методов и посвящена настоящая статья. В дальнейшем под информацией мы будем понимать наборы числовых данных, поскольку хранимым образом любого источника может быть число или множество чисел. При этом под количеством информации мы будем подразумевать ее объем, т.е. количество байтов памяти, необходимых для записи элементов числовых множеств.
Большинство используемых в настоящее время методов кодирования основывается на учете статистической информации о кодируемом множестве. В работе В.А. Амелькина[2]приведена одна из возможных классификаций методов кодирования. В соответствии с этой классификацией, выделяются следующие группы методов:
упаковки (код Бодо);
статистические методы;
алгоритмическое и комбинаторное кодирование.
Методы упаковки.
Как показано в той же работе, для кодирования множества A, состоящего из p элементов, при использовании равномерного двоичного кода, длина S кодовых сообщений равна:
S =[ log (p) ] + 1 (1)
При кодировании информации по методу Бодо в исходной матрице X= отыскивается максимальный элемент, для которого в соответствии с формулой (1)
So = [ log (max(xi,j ))] + 1 (2)
рассчитывается требуемое для его хранения число двоичных разрядов. При этом, для хранения каждого элемента таблицы xi,j отводится So двоичных разрядов. Для хранения всей таблицы необходимо (n*m*So) двоичных единиц. (Здесь n- число строк, а m- число столбцов исходной матрицы).
Существуют модификации этого метода, позволяющего повысить степень упаковки. К недостаткам метода следует отнести то, что он эффективен лишь на матрицах специального вида с незначительными различиями по абсолютному значению внутри строки и значительному - внутри столбцов (или наоборот).
Статистические методы.
В эту группу входят методы, основанные на учете статистических данных о кодируемом множестве. Исторически первым в этой группе был код Морзе.
В 1948-49 г.г. сразу двумя исследователями Шенноном и Фано независимо друг от друга был предложен метод кодирования, основанный на учете условных вероятностей появления сообщений. При этом сообщениям, имеющим большую вероятность ставились в соответствие более короткие кодовые сообщения, чем соообщениям, имеющим меньшую вероятность.
Идеи статистического кодирования получили свое дальнейшее развитие в работах Хаффмена. Код Хаффмена более эффективен чем Шеннона-Фано и в настоящее время широко используется при построении разнообразных программупаковщиков.
Алгоритмическое и комбинаторное кодирование.
Основная идея комбинаторного кодирования заключается в задании множества кодируемых сообщений не посредством перечисления всех элементов множества, а путем определения процедуры вычисления номера для некоторого сообщения.
Описываемые ниже методы нумерующего кодирования относятся именно к этой группе.
В основе предлагаемого нами метода кодирования лежит метод полиадических чисел, описанный в книге В.И. Амелькина[3]. Метод полиадических чисел использует полиадическую систему счисления, т.е. такую позиционную систему счисления, в которой в качестве основания приняты не постоянные числа p, а набор некоторых целых чисел l1 , l2 , ..., lm , на разность которых не накладывается никаких ограничений, т. е. li - lj при i = j может быть больше нуля, равно нулю или меньше нуля[4].
В такой системе счисления число L1 , a2 , ..., am можно представить в виде:
L = a1 *l2 *l3 * ... *lm + a2 *l3 *l4 * ... *lm + am -1*lm + am (3)
При этом каждая цифра ai < li, а каждый i-ый разряд имеет весовой коэффициент:
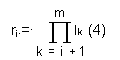
В работе В.И. Амелькина[5] сформулирована теорема существования и единственности такого разложения.
Использование полиадической системы счисления позволяет построить следующий алгоритм упаковки. Пусть задана целочисленная матрица A=ai,j , i=1,..,m, j=1,..,n.
--> ЧИТАТЬ ПОЛНОСТЬЮ <--