Реферат: Інформаційне відображення лікувально-діагностичного процесу в ендокринологічній клініці
Публікації. За матеріалами дисертації опубліковано 48 наукових праць (2 монографії, 26 статей та 20 тез); отримано авторське свідоцтво. У виданнях, що входять до переліку, затвердженого ВАК України опубліковано 23 статті.
Обсяг та структура роботи. Дисертаційна робота складається з вступу, огляду літератури, опису матеріалів та методів, 6 розділів власних досліджень, обговорення результатів, висновків, практичних рекомендацій та переліку літератури, який включає 233 джерела (98 вітчизняних та 135 іноземних). Робота викладена на 262 сторінках (основний текст подано на 249 сторінках) і має 38 таблиць та 30 рисунків.
ОСНОВНИЙ ЗМІСТ РОБОТИ
Вирішення проблеми створення єдиного інформаційного простору передбачається на шляху розробки “більш абстрактних моделей з невеликою кількістю, але високою виразністю абстрактних об’єктів. Модель даних щодо пацієнта слід зробити простішою та яснішою, для чого необхідно знайти уніфікований та коректний рівень абстракції” [McDonald C.J., Schadow G., Barnes M. et al., 2003]. Саме в цьому напрямку було проведено науковий пошук та на основі власного досвіду запропоновано оригінальний концептуальний підхід.
Моделі інформаційного відображення лікувально-діагностичного процесу. На рис. 1 наведено розподіл напрямків стандартизації МІС, які вже мають свої рішення у вигляді стандартів, що широко впроваджуються.
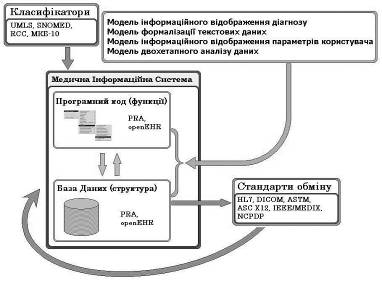
Рис. 1. Напрямки стандартизації МІС
Деякі напрямки стандартизації стосуються безпосередньо структури та функцій МІС (PRA, openEHR), проте цей шлях не може забезпечити достатнього рівня абстракції. Стандарти обміну медичною інформацією фактично повністю складаються з переліку параметрів, завдяки уніфікованості яких досягається можливість зв’язку та передачі пакетів між різними МІС та медичними пристроями. Зрозуміло, що за таких обставин відбувається постійне відновлення стандартів, чому сприяє постійний розвиток як медичної техніки, так і медичної науки.
Але є декілька типових проблем, які безпосередньо не стосуються ні рубрик класифікацій, ні стандартів обміну даними. До них належать: обробка текстових даних, обробка параметрів користувача, інформаційне відображення діагнозу, а також аналіз медичних даних.
Модель інформаційного відображення параметрів користувача. Універсальний підхід вимагає незмінними визначати тільки ті графи, які є загальними для всіх пацієнтів (П.І.Б., дата народження, адреса, діагноз тощо). Вся додаткова інформація повинна мати механізми додавання, корекції та аналізу в залежності від інформаційних потреб тієї чи іншої медичної установи. Нами запропонований механізм так званих "номінацій"(рис. 2), що призначені для збереження й обробки будь-яких параметрів користувача.
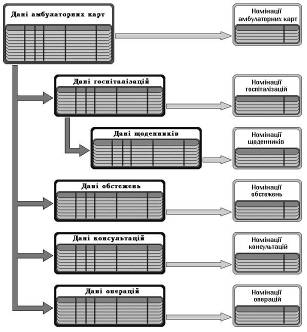
Рис. 2. Модель інформаційного відображення параметрів користувача
Запропонована модель інформаційного відображення параметрів користувача містить шість типів номінацій, що обслуговують (кожна свою) таблицю даних. Саме такий (розподілений) підхід є принциповою особливістю моделі та створює підґрунтя універсальності інформаційного відображення клінічних процесів. Спроби пов’язувати всі параметри користувача з будь-якою однією таблицею не дозволять відбивати ті чи інші дані в коректній залежності. В запропонованій моделі зникають проблеми з інтерпретацією різних даних чи дублюванням інформації, бо зберігається виключно рубрика номінації та число.
Треба зауважити, що саме такий перелік таблиць даних, до яких прив’язуються номінації, не є випадковим, а розкриває суть моделі. Саме представлена у такому вигляді медична інформація може бути ефективно доповнена відповідними номінаціями. Так, наприклад, таблиця обстежень за своїм інформаційним змістом використовується для всіх тих методів обстежень, що мають текстовий протокол та висновок (ультразвукове дослідження, комп’ютерна томографія, рентгенографія, електрокардіографія тощо). Саме наявність текстових даних є однією з головних передумов додавання таблиці номінацій, де можна зберігати рубриковану інформацію та числові значення. В той же час, відсутня в переліку таблиця аналізів не вимагає створення таблиці номінацій, бо за своїм призначенням вона використовується лише для тих аналізів (обстежень), результатом яких є одне число. В такому вигляді медична інформація вже є достатньо дискретною і може бути використана для універсального аналізу без додаткових зусиль.
Незважаючи на зручність рубрикації інформації, особливо для наступного аналізу, деяка первинна медична інформація може бути збережена тільки у вигляді тексту. До такої інформації відносяться, зокрема, протоколи операцій та обстежень, патогістологічні висновки тощо. З технічної сторони, існує стандартна проблема, пов’язана з обробкою текстової інформації, вирішення якої запропоновано в моделі формалізації текстових даних. Що ж до параметрів користувача, то залишається складність з інформацією, яку необхідно зберігати (крім текстового вигляду) у вигляді номінацій, тобто її потрібно вводити двічі. При активному використанні номінацій дублювання даних стає серйозним недоліком, віднімає додатковий час та є ще одним джерелом помилок. Розроблений механізм автоматичного додавання номінацій дозволяє практично не відчувати "незручностей" та уникнути подвійного введення інформації. Принцип його роботи полягає в тому, що зміст текстової графи контролюється на предмет наявності в ній визначених користувачем текстових фрагментів. Зрозуміло, що перелік цих ключових слів та/чи фраз не обмежено по кількості та змісту. Кожного разу при зміні текстової графи розміщення номінацій, поставлених у відповідність ключам, відбувається автоматично. Таким чином, за допомогою розробленої моделі можна забезпечити збереження та аналіз практично необмеженого кола параметрів від організаційних до наукових.
Модель формалізації текстових даних (рис. 3). Для заповнення текстових граф було розроблено механізм текстових шаблонів. Проте вставка фрагментів тексту в більшості випадків не може задовольнити лікаря. Медичні дані відрізняються надзвичайним різноманіттям і не можуть бути вкладені в шаблони.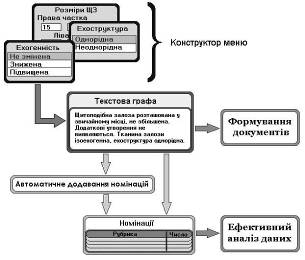
Рис. 3. Модель формалізації текстових даних
Для забезпечення зручності введення текстової інформації пропонується конструктор меню, який являє собою оригінальну розробку автора. За його допомогою можна створити будь-яку послідовність списків для вибору (меню) і вікон введення цифрових і текстових даних, забезпечивши при цьому формування необхідного тексту в тій чи іншій графі, зокрема, протоколу обстеження. Фактично цей механізм забезпечує можливість налаштування “під користувача” вільної послідовності дій, тобто виступає альтернативою багаточисельним вузькоспеціалізованим програмам та підпрограмам для великих інформаційних комплексів. За наявності згаданого конструктора користувач має можливість працювати в єдиному інформаційному просторі клініки без постійного вдосконалення системи розробником. Слід відзначити, що можливість конструювання меню передбачена в системі для переважної більшості текстових граф (доповнення діагнозу, щоденники, протоколи обстеження і операції тощо). Такий підхід дозволяє забезпечити значну ефективність введення великих масивів інформації.
Іншою стороною проблеми є аналіз текстових даних. Як відомо, він є доволі обмеженим: можна лише шукати точне співпадання тієї чи іншої послідовності символів. Однак, якщо прийняти до уваги наявність зазначених засобів формалізації введення, то пошук того чи іншого словосполучення в графі, яка заповнена автоматичним шляхом (з використанням конструктора меню чи шаблонів), стає набагато ефективнішим. Що стосується великої трудомісткості пошуку тих, чи інших текстових фрагментів та аналізу цифрової інформації, що знаходиться всередині тексту, то для подолання цих незручностей розроблено та апробовано метод автоматичної розстановки номінацій. Він дозволяє повністю автоматизувати цей процес і взагалі вести його у фоновому (не помітному для користувача) режимі. Крім того, передбачена можливість одразу розставити номінації за всіма раніше заповненими текстовими графами.
Таким чином, наведені механізми, складені разом, являють собою повноцінну модель формалізації текстових даних, при використанні якої користувач має можливість працювати в максимально зручному режимі при заповненні граф. Аналіз інформації виявляється доступним в найбільш ефективному руслі, яким є використання рубрик номінацій та їх числових значень. На рис. 3 наведено всі принципові складові моделі формалізації та шляхи її використання для вирішення двох головних задач: створення медичних документів та виконання ефективного аналізу даних.
Модель інформаційного відображення діагнозу (рис. 4). Зрозуміло, що тільки уніфікація діагнозів відкриває можливість їх ефективної автоматизованої обробки. Але, в той же час, діагноз неможливо повністю формалізувати, що зазвичай і створює складності в процесі інформатизації. Відображення діагнозу в запропонованій моделі реалізовано шляхом створення окремої підлеглої таблиці. Такий підхід дозволяє зберігати й обробляти будь-яку кількість рубрик діагнозів для кожного пацієнта. Крім того, до кожного діагнозу, що вибирається лікарем з довідника, вводиться так зване "доповнення", яке, належачи до граф нефіксованої довжини, дозволяє викласти всі необхідні особливості, що відсутні в якості самостійних інформаційних одиниць. Перелік припустимих рубрик, як головних складових діагнозу, визначається кваліфікованими фахівцями у відповідному напрямку медицини, наприклад, щодо захворювань щитоподібної залози, - ендокринологами. Така організація даних дозволяє лікарю формувати будь-які медичні документи і відображати навіть казуїстичні нюанси, залишаючи базу даних уніфікованою за всіма, визначеними як рубрики, діагнозами. Всі внесені доповнення (до кожної рубрики діагнозу) також зберігаються та завжди доступні. Їхній автоматизований аналіз можливо забезпечити за допомогою розглянутої вище моделі формалізації текстових граф.
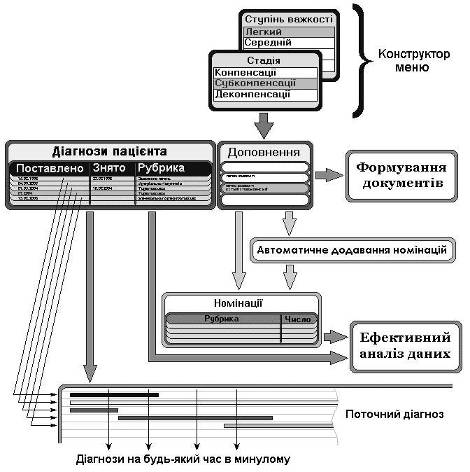
Рис. 4. Модель інформаційного відображення діагнозу пацієнта
На етапі ведення медичної документації лише в стаціонарі ця структура (рубрика + доповнення) була ефективним та закінченим вирішенням проблеми. Перехід до інформаційної системи амбулаторних карт привів до необхідності подальшого пошуку, тому що в такому масштабі діагноз не може зберігатися у вигляді складової частини даних про конкретну госпіталізацію, а є динамічним параметром пов’язаним з людиною. Кожен пацієнт може бути неодноразово консультованим, обстеженим та госпіталізованим. При цьому незмінний діагноз не повинен багаторазово дублюватися, що, крім іншого, порушує вимоги нормалізації бази даних. У той же час необхідно коректно відслідковувати всю динаміку змін діагнозу в результаті обстеження та лікування.
Для вирішення проблеми нами запропоновано введення графи “Дата зняття діагнозу”, що на теперішній час відсутня в затверджених медичних формах. В такому випадку з’являється можливість в рамках автоматизованої системи одержувати як послідовну історію захворювань, так і поточний діагноз на будь-яку, в тому числі поточну, мить. Треба зазначити, що діагноз, як відображення деякого стану, повинен мати "час життя", що може закінчитися або одужанням, або зміною в результаті діагностики, впливу лікування чи самого патологічного процесу. Проте, практичне впровадження такої структури піднімає принципові питання, якими, зазвичай, лікарі не задаються. Використання паперових носіїв інформації не змушує упорядковувати структуру всіх діагнозів, встановлених пацієнтам, а при оформленні кожної конкретної консультації найчастіше залишаються лише поточні та профільні нозологічні одиниці. В рамках дисертаційної роботи запропоновано підходи до відображення хірургічної патології ендокринних органів, зокрема, визначення адекватного часу зняття діагнозу доброякісної вогнищевої патології ЩЗ, використання рубрик, що відповідають стану після операційного втручання тощо.
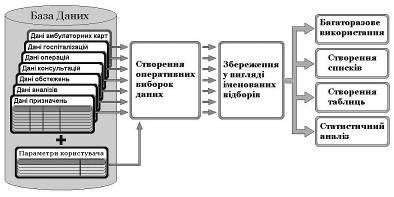
Принцип двохетапного аналізу даних. На відміну від розрахунку стандартних статистичних параметрів діяльності клініки (що також реалізовано в розробленій МІС), оригінальний принцип двохетапного аналізу даних передбачає розмежування етапів створення оперативних вибірок та їх збереження у вигляді іменованих відборів (рис. 5). Запропонований принцип дозволяє створити будь-яку групу за будь-якими з наявних в базі даних параметрами, в тому числі користувача (номінаціями). Створення вибірок та відборів можливо як за пацієнтами (амбулаторними картами), так і за госпіталізаціями, операціями, обстеженнями, консультаціями та аналізами. Зрозуміло, що один і той же запит (наприклад: всі, оперовані в поточному місяці) може дати різну кількість людей, госпіталізацій, операцій та т. і. В системі реалізовано алгоритм виконання запиту, який враховує залежності, закладені в структуру бази даних, для здійснення коректної інтерпретації вказаних умов вибірки.
Після отримання вибірки стає можливим її збереження, що дозволяє не тільки звертатись до неї у наступному та з інших утиліт, а й створювати на її основі списки і таблиці. Реалізований механізм дозволяє значні налаштування не тільки за кількістю, обсягом та чергою граф, а також і різних форм, зокрема з повним виведенням змісту текстових граф. Головною, безумовно, є можливість автоматичного створення таблиць за вказаними користувачем графами в рядках та колонках.
Розроблена двохетапна процедура аналізу даних в МІС дозволяє в реальних клінічних умовах формувати звіти по відділенню та клініці, а також проводити повноцінні наукові дослідження з отриманням кінцевих таблиць зі статистичною вірогідністю.