Реферат: Кодирование информации 2
Последовательностью битов можно закодировать текст, изображение, звук или какую-либо другую информацию.
Такой метод представления информации называется двоичным кодированием .
Таким образом, двоичный код является универсальным средством кодирования информации.
Кодирование текстовой информации
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Для хранения двоичного кода одного символа выделен 1 байт = 8 бит.
Учитывая, что каждый бит принимает значение 0 или 1, количество их возможных сочетаний в байте равно ![]()
![]()
 Значит, с помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов.
Значит, с помощью 1 байта можно получить 256 разных двоичных кодовых комбинаций и отобразить с их помощью 256 различных символов.
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и заглавные буквы русского и латинского алфавита, цифры, знаки, графические символы и т.д.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111.
Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Важно, что присвоение символу конкретного кода - это вопрос соглашения, которое фиксируется в кодовой таблице.
Кодирование текстовой информации с помощью байтов опирается на несколько различных стандартов, но первоосновой для всех стал стандарт ASCII (American Standart Code for Information Interchange), разработанный в США в Национальном институте ANSI (American National Standarts Institute).
В системе ASCII закреплены две таблицы кодирования - базовая и расширенная.
Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 33 кода (с 0 до 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и т. д.).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, т.е. в национальных кодировках одному и тому же коду соответствуют различные символы.
Например, ASCII коды букв латинского алфавита:
Таблица 1
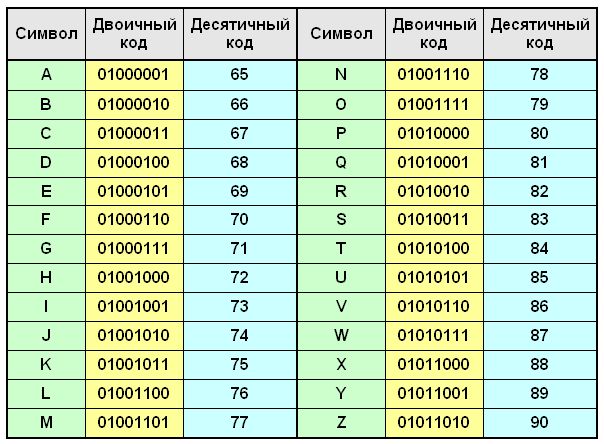
Тогда слово COMPUTER с помощью ASCII таблицы кодируется следующим образом:
| C | O | M | P | U | T | E | R |
| 67 | 79 | 77 | 80 | 85 | 84 | 69 | 82 |
| 01000011 | 01001111 | 01001101 | 01010000 | 01010101 | 01010100 | 01000101 | 01010010 |
С распространением современных информационных технологий в мире возникла необходимость кодировать символы алфавитов других языков: японского, корейского, арабского, хинди, а также других специальных символов.
На смену старой системе пришла новая универсальная – UNICODE, в которой один символ кодируется не одним, а двумя байтами.
В настоящее время существует много различных кодовых таблиц (DOS, ISO, WINDOWS, KOI8-R, KOI8-U, UNICODE и др.), поэтому тексты, созданные в одной кодировке, могут не правильно отображаться в другой.
Кодирование графической информации
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые, в свою очередь, содержат определенное количество точек. 
Рисунок 2
Давайте посмотрим на экран компьютера через увелечительное стекло.
В зависимости от марки и модели техники мы увидим либо множество разноцветных прямоугольничков, либо множество разноцветных кружочков.