Реферат: Кодирование изображений
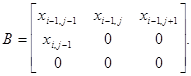
Для простоты рассмотрим одномерный фильтр вида:![]() :
:
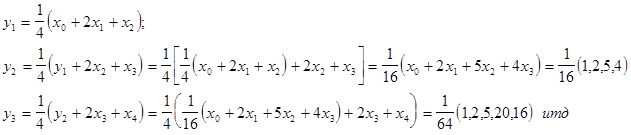 Рассмотрим и другие фильтры:
Рассмотрим и другие фильтры:
Высокочастотные (для подчеркивания резкости изображения):
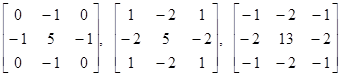
Для подчеркивания ориентации:
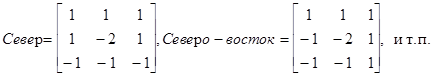
Подчеркивание без учета ориентации (фильтры Лапласа):
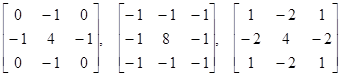 .
.
Корреляционный:
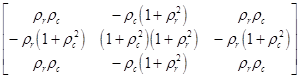 ,где
,где
![]() - коэффициенты корреляции между соседними элементами по строке (столбцу). Если они равны нулю то отфильтрованное изображение будет совпадать с исходным, если они равны единице, то фильтр будет эквивалентен лапласиану. При обработке изображений очень часто используют последовательность фильтров: низкочастотный + Лапласа. Часто используют и нелинейную фильтрацию. Для контрастирования перепадов изображения используют градиентный фильтр:
- коэффициенты корреляции между соседними элементами по строке (столбцу). Если они равны нулю то отфильтрованное изображение будет совпадать с исходным, если они равны единице, то фильтр будет эквивалентен лапласиану. При обработке изображений очень часто используют последовательность фильтров: низкочастотный + Лапласа. Часто используют и нелинейную фильтрацию. Для контрастирования перепадов изображения используют градиентный фильтр:
![]() , или его упрощенный вид:
, или его упрощенный вид:
![]() .
.
Еще один часто используемый нелинейный фильтр - Собела:
A0 ... A7 - входы, yi,j - результат фильтрации.

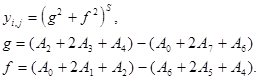
Рекурсивная версия :
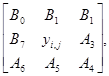 где B0 ... B7 - выход отфильтрованного изображения.
где B0 ... B7 - выход отфильтрованного изображения.
Нелинейная фильтрация - достаточно загадочная область цифровой обработки сигналов, многое еще в ней пока не изучено. Важность же ее не вызывает сомнений, потому, что окружающий нас мир по своей сути не так линеен, как порою хочется его нам интерпретировать.
3.Сжатие.
Изображения, в машинном представлении, - двумерная матрица N на M, где N - его ширина, M - высота. При сканировании обычно используют разрешение от 72 до 2400 dpi (dots per inch - точек на дюйм). Наиболее часто - 300dpi. Если взять лист бумаги 21/29 см с изображениеми отсканировать его в RGB Truecolor, то несжатое изображение будет занимать ~27300000 байтов или 26 Мбайт. Обычно в базах данных применяют изображения порядка от 320x240 до 640x480. Но и они занимают 76 до 900 Кбайт. А что, если таких изображений сотни, тысячи?В данном разделе рассмотрим методы сжатия. Они применительны для любых массивов данных, а не только для изображений. О методах сжатия, характерных только для изображений узнаем немного позже. Будем рассматривать статическое сжатие, то есть массив данных для сжатия целиком сформирован. Методы сжатия статического часто подразделяют на последовательное и энтропийное. Последовательное сжатие использует в работе наличие повторяющихся участков. Энтропийное используется с целью сокращения к минимуму избыточности информации. Последовательное применение этих методов позволяет получить хороший результат.
Последовательное сжатие.
Наиболее часто применяют метод RLE, суть которого рассмотрим на изображении. Почти в любом изображении, особенно в компьютерных рисунках, встречаются последовательности одинаковых байтов. Например, в участке изображения, в котором нарисована часть неба, идут подряд несколько значений голубого цвета. Для участка вида: ККККККККЗЗЗЗСЗССССССССС , где К- красный, З - зеленый, С - синий цвета, будет закодирован как (8,К),(4,З),С,З,(10,С). В скобках - пары количество повторений, значение байта. Вот как данный метод применяется в формате PCX. Декодирование: если код принадлежит множеству [192..255], то вычитаем из него 192 и получаем количество повторений следующего байта. Если же он меньше 192, то помещаем его в декодируемый поток без изменений. Оригинально кодируются единичные байты в диапазоне [192..255] - двумя байтами, например, чтобы закодировать 210 необходимо, представить его как (193, 210). Данный метод дает выигрыш в среднем в 2 раза. Однако для отсканированных изображений, содержащих плавные цветовые переходы (то есть повторяющиеся цепочки почти не встречаются), данный метод может преподнести сюрприз - размер массива с закодированным изображением будет больше исходного.
Наиболее распространены в настоящее времямодификации алгоритма LZ (по имени их авторов - Лемпела и Зива). По сравнению с RLE сделан шаг вперед - будем искать в исходном материале не последовательности одинаковых видов, а повторяющихся цепочек символов. Повторяющие цепочки в кодированном сообщении хранятся как ссылка на первое появление данной цепочки. Например, в цепочке КЗСЗБСКЗСЗБ начиная с 7 символа, идет цепочка КЗСЗ, которую мы можем заменить ссылкой на 1-ый символ. Рассмотрим наиболее распространенные реализации алгоритма LZ:
LZ77 - при работе выдает тройки вида (A, B, C), где A - смещение (адрес предыдущей цепочки B байтов которой совпадают с кодируемой цепочкой), B - длина цепочки, C - первый символ в кодируемом массиве, следующий за цепочкой. Если совпадение не обнаружено то создается тройка вида (0, 0, С), где C - первый символ кодируемой цепочки. Недостаток такого подхода очевиден - при кодировании “редких” байтов мы “сжимаем” один байт в три. Преимущество - простота реализации, большая скорость декодирования.
LZSS - создает при работе вектора вида (флаг, C) и (флаг, A, B). Если битовый флаг=0, то следующий за ним C трактуется, как единичный байт и выдается в декодируемый массив. Иначе, когда флаг=1, то в декодируемый массив выдается цепочка длиною B по смещению A. LZSS кодирует намного более эффективно, по сравнению с LZ77, так как использует битовые флаги и мало проигрывает при кодировании одиночных символов. При кодировании строится словарь встречающихся цепочек в виде двоичного упорядоченного дерева. Скорость и простота алгоритма декодирования массива у LZSS также высока.
LZMX (упрощенный LZM) - данный алгоритм предназначен для скоростного кодирования и по эффективности уступает LZSS, заметно обгоняя его по скорости работы. При работе кодер LZMX формирует несколько векторов вида:
(0, A, несжатый поток) - где 00 -2х битовый флаг признака данного блока, A (7 битов с диапазоном в [1..127]) - длина следующего за ним несжатого потока в байтах..