Реферат: Модели и методы решения проблемы выбора в условиях неопределенности
Наиболее интересным и полезным в плане понимания сущности факторного анализа — метода решения задач в этих ситуациях, является пример использования наблюдений при эксперименте, который ведет природа, Ни о каком планировании здесь не может идти речи — нам приходится довольствоваться пассивным экспериментом.
Удивительно, но и в этих “тяжелых” условиях ТССА предлагает методы выявления таких факторов, отсеивания слабо проявляющих себя, оценки значимости полученных зависимостей показателей работы системы от этих факторов.
Пусть мы провели по n наблюдений за каждым из k измеряемых показателей эффективности некоторой экономической системы и данные этих наблюдений представили в виде матрицы (таблицы).
Матрица исходных данных E[n·k]
| E 11 | E12 | … | E1i | … | E1k |
| E 21 | E22 | … | E2i | … | E2k |
| … | … | … | … | … | … |
| E j1 | Ej2 | … | Eji | … | Ejk |
| … | … | … | … | … | … |
| E n1 | En2 | … | Eni | … | Enk |
Пусть мы предполагаем, что на эффективность системы влияют и другие — ненаблюдаемые, но легко интерпретируемые (объяснимые по смыслу, причине и механизму влияния) величины — факторы.
Сразу же сообразим, что чем больше n и чем меньше таких число факторов m (а может их и нет вообще!), тем больше надежда оценить их влияние на интересующий нас показатель E.
Столь же легко понять необходимость условия m < k, объяснимого на простом примере аналогии — если мы исследуем некоторые предметы с использованием всех 5 человеческих чувств, то наивно надеяться на обнаружение более пяти “новых”, легко объяснимых, но неизмеряемых признаков у таких предметов, даже если мы “испытаем” очень большое их количество.
Вернемся к исходной матрице наблюдений E[n·k] и отметим, что перед нами, по сути дела, совокупности по n наблюдений над каждой из k случайными величинами E1, E2, … E k. Именно эти величины “подозреваются” в связях друг с другом — или во взаимной коррелированности.
Из рассмотренного ранее метода оценок таких связей следует, что мерой разброса случайной величины E i служит ее дисперсия, определяемая суммой квадратов всех зарегистрированных значений этой величины S(Eij)2 и ее средним значением (суммирование ведется по столбцу).
Если мы применим замену переменных в исходной матрице наблюдений, т.е. вместо Ei j будем использовать случайные величины
Xij = 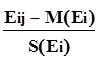 ,
,
то мы преобразуем исходную матрицу в новую
X[n·k]
| X 11 | X12 | … | X1i | … | X1k |
| X 21 | X22 | … | X2i | … | X2k |
| … | … | … | … | … | … |
| X j1 | Xj2 | … | Xji | … | Xjk |
| … | … | … | … | … | … |
| X n1 | Xn2 | … | Xni | … | Xnk |
Отметим, что все элементы новой матрицы X[n·k] окажутся безразмерными, нормированными величинами и, если некоторое значение Xij составит, к примеру, +2, то это будет означать только одно - в строке j наблюдается отклонение от среднего по столбцу i на два среднеквадратичных отклонения (в большую сторону).
Выполним теперь следующие операции.
· Просуммируем квадраты всех значений столбца 1 и разделим результат на (n - 1) — мы получим дисперсию (меру разброса) случайной величины X1 , т.е. D1. Повторяя эту операцию, мы найдем таким же образом дисперсии всех наблюдаемых (но уже нормированных) величин.
· Просуммируем произведения соответствующих строк (от j =1 до j = n) для столбцов 1,2 и также разделим на (n -1). То, что мы теперь получим, называется ковариацией C12 случайных величин X1 , X2 и служит мерой их статистической связи.
· Если мы повторим предыдущую процедуру для всех пар столбцов, то в результате получим еще одну, квадратную матрицу C[k·k], которую принято называть ковариационной.
Эта матрица имеет на главной диагонали дисперсии случайных величин Xi, а в качестве остальных элементов — ковариации этих величин ( i =1…k).
Ковариационная матрица C[k·k]
| D1 | C12 | C13 | … | … | C1k |
| C21 | D2 | C23 | … | … | C2k |
| … | … | … | … | … | … |
| Cj1 | Cj2 | … | Cji | … | Cjk |
| … | … | … | … | … | … |
| Cn1 | Cn2 | … | Cni | … | Dk |
Если вспомнить, что связи случайных величин можно описывать не только ковариациями, но и коэффициентами корреляции, то в соответствие матрице {3-29} можно поставить матрицу парных коэффициентов корреляции или корреляционную матрицу
R [k·k]
| 1 | R12 | R13 | … | … | R1k |
| R21 | 1 | R23 | … | … | R2k |
| … | … | … | … | … | … |
| Rj1 | Rj2 | … | Rji | … | Rjk |
| … | … | … | … | … | … |
| Rn1 | Rn2 | … | Rni | … | 1 |
в которой на диагонали находятся 1, а внедиагональные элементы являются обычными коэффициентами парной корреляции.
Так вот, пусть мы полагали наблюдаемые переменные Ei независящими друг от друга, т.е. ожидали увидеть матрицу R[k·k] диагональной, с единицами в главной диагонали и нулями в остальных местах. Если теперь это не так, то наши догадки о наличии латентных факторов в какой-то мере получили подтверждение.
Но как убедиться в своей правоте, оценить достоверность нашей гипотезы — о наличии хотя бы одного латентного фактора, как оценить степень его влияния на основные (наблюдаемые) переменные? А если, тем более, таких факторов несколько — то как их проранжировать по степени влияния?
Ответы на такие практические вопросы призван давать факторный анализ. В его основе лежит все тот же “вездесущий” метод статистического моделирования (по образному выражению В.В.Налимова — модель вместо теории).
Дальнейший ход анализа при выяснению таких вопросов зависит от того, какой из матриц мы будем пользоваться. Если матрицей ковариаций C[k·k], то мы имеем дело с методом главных компонент, если же мы пользуемся только матрицей R[k·k], то мы используем метод факторного анализа в его “чистом” виде.
Остается разобраться в главном — что позволяют оба эти метода, в чем их различие и как ими пользоваться. Назначение обоих методов одно и то же — установить сам факт наличия латентных переменных (факторов), и если они обнаружены, то получить количественное описание их влияния на основные переменные Ei.
Ход рассуждений при выполнении поиска главных компонент заключается в следующем. Мы предполагаем наличие некоррели-рованных переменных Zj ( j=1…k), каждая из которых представляется нам комбинацией основных переменных (суммирование по i =1…k):