Реферат: Стратегия поиска в автоматизированных информационных системах
Прямой поиск
Ниже представлена простейшая его версия знакома многим.
char* strstr(char *big, | ПРЯМОЙ ПОИСК ТЕКСТА. |
Несмотря на кажущуюся простоту, последние 30 лет прямой поиск интенсивно развивается. Было выдвинуто немалое число идей, сокращающих время поиска в разы. При этом надо учесть, что новые алгоритмы и их улучшенные варианты появляются постоянно.
Хотя прямой просмотр всех текстов – довольно медленное занятие, не следует думать, что алгоритмы прямого поиска не применяются в интернете. Норвежская поисковая система Fast (www.fastsearch.com) использовала чип, реализующий логику прямого поиска упрощенных регулярных выражений, и разместила 256 таких чипов на одной плате. Это позволяло Fast-у обслуживать довольно большое количество запросов в единицу времени.
Кроме того, есть масса программ, комбинирующих индексный поиск для нахождения блока текста с дальнейшим прямым поиском внутри блока. Например, весьма популярный, в том числе и в Рунете, glimpse.
У прямых алгоритмов есть положительные черты. Например, неограниченные возможности по приближенному и нечеткому поиску. Ведь любое индексирование всегда сопряжено с упрощением и нормализацией терминов, а, следовательно, с потерей информации. Прямой же поиск работает непосредственно по оригинальным документам безо всяких искажений.
Инвертированный файл
Эта простейшая структура данных. Первая категория людей знает, что это такое, по «конкордансам» - алфавитно упорядоченным исчерпывающим спискам слов из одного текста или принадлежащих одному автору (например «Конкорданс к стихам А. С. Пушкина», «Словарь-конкорданс публицистики Ф. М. Достоевского»). Вторые имеют дело с той или иной формой инвертированного списка всякий раз, когда строят или используют «индекс БД по ключевому полю».
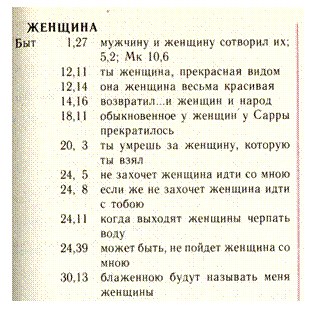 Проиллюстрируем эту структуру при помощи замечательного русского конкорданса - «Симфонии», выпущенной московской патриархией по тексту синодального перевода Библии [симфония].
Проиллюстрируем эту структуру при помощи замечательного русского конкорданса - «Симфонии», выпущенной московской патриархией по тексту синодального перевода Библии [симфония].
Рис. 1
Перед нами упорядоченный по алфавиту список слов. Для каждого слова перечислены все «позиции», в которых это слово встретилось. Поисковый алгоритм состоит в отыскании нужного слова и загрузке в память уже развернутого списка позиций.
Чтобы сэкономить на дисковом пространстве и ускорить поиск, обычно прибегают к двум приемам. Во-первых, подробность самой позиции. Чем подробнее задана такая позиции, например, в случае с «Симофонией» это «книга+глава+стих», тем больше места потребуется для хранения инвертированного файла.
В наиподробнейшем варианте в инвертированном файле можно хранить и номер слова, и смещение в байтах от начала текста, и цвет и размер шрифта, да много чего еще. Чаще же просто указывают только номер документа, скажем, книгу Библии, и число употреблений этого слова в нем. Именно такая упрощенная структура считается основной в классической теории информационного поиска – Information Retrieval (IR).
Второй (никак не связанный с первым) способ сжатия: упорядочить позиции для каждого слова по возрастанию адресов и для каждой позиции хранить не полный ее адрес, а разницу от предыдущего. Вот как будет выглядеть такой список для нашей странички в предположении, что мы запоминаем позицию вплоть до номера главы:
ЖЕНЩИНА: [Быт.1],[+11],[0],[+2],[+4],[+2],[+4],..
Дополнительно на разностный способ хранения адресов накладывают какой-нибудь способ упаковки: зачем отводить небольшому целому числу фиксированное «огромное» количество байт, ведь можно отвести ему почти столько байт, сколько оно заслуживает. Здесь уместно упомянуть коды Голомба или встроенную функцию популярного языка Perl: pack(“w”).
В литературе встречается и более тяжелая система упаковочных алгоритмов самого широкого спектра: арифметический, Хафман, LZW, и т.д. Прогресс в этой области идет непрерывно. На практике в поисковых системах они используются редко: выигрыш невелик, а мощности процессора расходуются неэффективно.
В результате всех описанных ухищрений размер инвертированного файла, как правило, составляет от 7 до 30 процентов от размера исходного текста, в зависимости от подробности адресации.
занесены в «Красную книгу»
Неоднократно предлагались другие, отличные от инвертированного и прямого поиска алгоритмы и структуры данных. Это, прежде всего, суффиксные деревья, а также сигнатуры.
Первый из них функционировал и в интернете, будучи запатентованным алгоритмом поисковой ситемы OpenText.
Мне доводилось встречать суффиксные индексы в отечественных поисковых системах.
Второй - метод сигнатур - представляет собой преобразование документа к поблочным таблицам хеш-значений его слов - "сигнатуре" и последовательному просмотру "сигнатур" во время поиска.
Широкого распространения эти два метода не получили.
МАТЕМАТИЧЕСКИЕ МОДЕЛИ