Реферат: Технические характеристики современных серверов
Разделяемая адресная шина упрощает реализацию наблюдения (snooping) за адресами, которое необходимо для аппаратной поддержки когерентности памяти. Адресные транзакции конвейеризованы, выполняются асинхронно (расщеплено) по отношению к пересылкам данных и требуют относительно небольшой полосы пропускания, гарантируя, что этот ресурс никогда войдет в состояние насыщения.
Организация пересылок данных требует больше внимания, поскольку уровень трафика и время занятости ресурсов физического межсоединения здесь существенно выше, чем это требуется для пересылки адресной информации. Операция пересылки адреса представляет собой одиночную пересылку, в то время как операция пересылки данных должна удовлетворять требованию многобайтной пересылки в соответствии с размером строки кэша ЦП. При реализации отдельных магистралей данных появляется ряд дополнительных возможностей, которые обеспечивают:
- максимальную скорость передачи данных посредством соединений точка-точка на более высоких тактовых частотах;
- параллельную пересылку данных посредством организации выделенного пути для каждого соединения;
- разделение адресных транзакций и транзакций данных. Поэтому архитектуру PowerScale компании Bull можно назвать многопотоковой аппаратной архитектурой (multi-threaded hardware architecture) с возможностями параллельных операций.
На рис. 4.3 показаны основные режимы и операции, выполняемые матричным коммутатором.
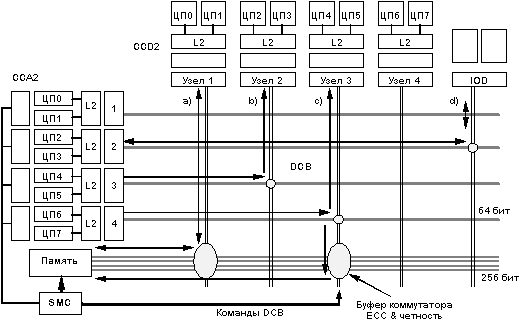
Рис. 4.3. Матричный коммутатор. ССA2 - сдвоенный контроллер адресов кэш-памяти;
CCD2 - сдвоенный контроллер данных кэш-памяти; IOD - дочерняя плата ввода/вывода;
DCB - матричный коммутатор данных; SMC - контроллер системной памяти
Режим обращения к памяти - Memory mode: (a)
Процессорный узел или узел в/в коммутируется с массивом памяти (MA). Такое соединение используется для организации операций чтения памяти или записи в память.
Режим вмешательства (чтение): (b)
Читающий узел коммутируется с другим узлом (вмешивающимся узлом) и шиной данных MA. Этот режим используется тогда, когда при выполнении операции чтения строки от механизма наблюдения за когерентным состоянием памяти поступает ответ, что данная строка находится в кэш-памяти другого узла и модифицирована. В этом случае данные, извлекаемые из строки кэша владельца, подаются читающему узлу и одновременно записываются в MA. Если читающий и вмешивающийся ЦП находятся внутри одного и того же узла, то данные заворачиваются назад на уровне узла и одновременно записываются в память.
Режим вмешательства (чтение с намерением модификации - RWITM):(c)
Процессорный узел или узел в/в (читающий узел) коммутируется с другим процессорным узлом или узлом в/в. Этот режим используется тогда, когда при выполнении операция RWITM от механизма наблюдения поступает ответ, что данная строка находится в кэш-памяти другого узла и модифицирована. В этом случае данные, извлекаемые из строки кэша владельца, подаются только читающему узлу и не записываются в память.
Режим программируемого ввода/вывода (PIO): (d)
Процессорный узел коммутируется с узлом в/в. Это случай операций PIO, при котором данные обмениваются только между процессором и узлом в/в.
Режим в/в с отображением в памяти (memory mapped):
Главный узел коммутируется с узлами в/в (подчиненными узлами), вовлеченными в транзакцию. Это случай операций с памятью.
Параметры производительности
Вслед за установочной фазой транзакции (например, после установки адреса на адресной шине) данные могут пересылаться через коммутатор на полной скорости синхронизации. Это возможно благодаря организации соединению точка-точка, которое создается для каждой отдельной транзакции. Поэтому в дальнейшем какие-либо помехи отсутствуют. Возможно также выполнять параллельно несколько операций, например, множественный доступ к памяти или пересылки между кэшами.
Для того чтобы уменьшить задержку памяти, операции чтения начинаются до выполнения каких-либо действий по обеспечению глобальной когерентности на уровне системы. Ответы когерентности полностью синхронизированы, разрешаются за фиксированное время и поступают всегда прежде, чем будет захвачен разделяемый ресурс - шина памяти. Это помогает избежать ненужных захватов шины. Любые транзакции, которые не разрешаются когерентно за данное фиксированное время, позднее будут повторены системой.
Используемая в системе внутренняя частота синхронизации равна 75 МГц, что позволяет оценить уровень производительности разработанной архитектуры. Интерфейс физической памяти имеет ширину 32 байта и, учитывая арбитраж шины, позволяет пересылать 32 байта каждые 3 такта синхронизации. Это дает скорость передачи данных 800 Мбайт/с, поддерживаемую на уровне интерфейса памяти. Каждый порт ЦП имеет ширину 8 байт и способен передавать по 8 байт за такт, т.е. со скоростью 600 Мбайт/с. Следует отметить, что это скорость, достигаемая как при пересылке ЦП-память, так и при пересылке кэш-кэш. Скорость 800 Мбайт/с для памяти поддерживается с помощью буферов в коммутаторе, которые позволяют конвейеризовать несколько операций.
Поскольку несколько операций могут выполняться через коммутатор на полной скорости параллельно, то для оптимальной смеси операций (две пересылки из ЦП в память, плюс пересылка кэш-кэш), пропускная способность может достигать пикового значения 1400 Мбайт/с. Таким образом, максимальная пропускная способность будет варьироваться в диапазоне от 800 до 1400 Мбайт/с в зависимости от коэффициента попаданий кэш-памяти.
Когерентность кэш-памяти
Известно, что требования, предъявляемые современными процессорами к полосе пропускания памяти, можно существенно сократить путем применения больших многоуровневых кэшей. Проблема когерентности памяти в мультипроцессорной системе возникает из-за того, что значение элемента данных, хранящееся в кэш-памяти разных процессоров, доступно этим процессорам только через их индивидуальные кэши. При этом определенные операции одного из процессоров могут влиять на достоверность данных, хранящихся в кэшах других процессоров. Поэтому в подобных системах жизненно необходим механизм обеспечения когерентного (согласованного) состояния кэшей. С этой целью в архитектуре PowerScale используется стратегия обратной записи, реализованная следующим образом.
Вертикальная когерентность кэшей
Каждый процессор для своей работы использует двухуровневый кэш со свойствами охвата. Это означает, что кроме внутреннего кэша первого уровня (кэша L1), встроенного в каждый процессор PowerPC, имеется связанный с ним кэш второго уровня (кэш L2). При этом каждая строка в кэше L1 имеется также и в кэше L2. В настоящее время объем кэша L2 составляет 1 Мбайт на каждый процессор, а в будущих реализациях предполагается его расширение до 4 Мбайт. Сама по себе кэш-память второго уровня позволяет существенно уменьшить число обращений к памяти и увеличить степень локализации данных. Для повышения быстродействия кэш L2 построен на принципах прямого отображения. Длина строки равна 32 байт (размеру когерентной гранулированности системы). Следует отметить, что, хотя с точки зрения физической реализации процессора PowerPC, 32 байта составляют только половину строки кэша L1, это не меняет протокол когерентности, который управляет операциями кэша L1 и гарантирует что кэш L2 всегда содержит данные кэша L1.
Кэш L2 имеет внешний набор тегов. Таким образом, любая активность механизма наблюдения за когерентным состоянием кэш-памяти может быть связана с кэшем второго уровня, в то время как большинство обращений со стороны процессора могут обрабатываться первичным кэшем. Если механизм наблюдения обнаруживает попадание в кэш второго уровня, то он должен выполнить арбитраж за первичный кэш, чтобы обновить состояние и возможно найти данные, что обычно будет приводить к приостановке процессора. Поэтому глобальная память может работать на уровне тегов кэша L2, что позволяет существенно ограничить количество операций наблюдения, генерируемых системой в направлении данного процессора. Это, в свою очередь, существенно увеличивает производительность системы, поскольку любая операция наблюдения в направлении процессора сама по себе может приводить к приостановке его работы.
Вторичная когерентность кэш-памяти
Вторичная когерентность кэш-памяти требуется для поддержки когерентности кэшей L1&L2 различных процессорных узлов, т.е. для обеспечения когерентного состояния всех имеющихся в мультипроцессорной системе распределенных кэшей (естественно включая поддержку когерентной буферизации ввода/вывода как по чтению, так и по записи).
Вторичная когерентность обеспечивается с помощью проверки каждой транзакции, возникающей на шине MPB_SysBus. Такая проверка позволяет обнаружить, что запрашиваемая по шине строка уже кэширована в процессорном узле, и обеспечивает выполнение необходимых операций. Это делается с помощью тегов кэша L2 и логически поддерживается тем фактом, что L1 является подмножеством L2.
Протокол MESI и функция вмешательства
В рамках архитектуры PowerScale используется протокол MESI, который представляет собой стандартный способ реализации вторичной когерентности кэш-памяти. Одной из основных задач протокола MESI является откладывание на максимально возможный срок операции обратной записи кэшированных данных в глобальную память системы. Это позволяет улучшить производительность системы за счет минимизации ненужного трафика данных между кэшами и основной памятью. Протокол MESI определяет четыре состояния, в которых может находиться каждая строка каждого кэша системы. Эта информация используется для определения соответствующих последующих операций (рис. 4.4).
Состояние строки "Единственная" (Exclusive):