Шпаргалка: Лекции по количественной оценке информации
Кроме общего понятия избыточности существуют частные виды избыточности.
Избыточность, обусловленная неравновероятным распределением символов в сообщении,
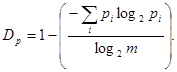 (46)
(46)
Избыточность, вызванная статистической связью между символами сообщения,
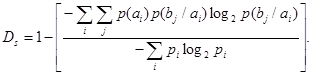 (47)
(47)
Полная информационная избыточность
![]() (48)
(48)
Избыточность, которая заложена в природе данного кода, получается в результате неравномерного распределения в сообщениях качественных признаков этого кода и не может быть задана одной цифрой на основании статистических испытаний.
Так при передаче десятичных цифр двоичным кодом максимально загруженными бывают только те символы вторичного алфавита, которые передают значения, являющиеся целочисленными степенями двойки. В остальных случаях тем же количеством символов может быть передано большее количество цифр (сообщений). Например, тремя двоичными разрядами мы можем передать и цифру 5, и цифру 8, т. е. на передачу пяти сообщений тратится столько же символов, сколько тратится и на восемь сообщений.
Фактически для передачи сообщения достаточно иметь длину кодовой комбинации
![]() ,
,
где N - общее количество передаваемых сообщений.
L можно представить и как
![]() ,
,
где![]() и
и ![]() —соответственно качественные признаки первичного и вторичного алфавитов. Поэтому для цифры 5 в двоичном коде можно записать
—соответственно качественные признаки первичного и вторичного алфавитов. Поэтому для цифры 5 в двоичном коде можно записать
![]()
Однако эту цифру необходимо округлить до ближайшего целого числа, так как длина кода не может быть выражена дробным числом. Округление, естественно, производится в большую сторону. В общем случае, избыточность от округления
![]()
где ![]() — округленное до ближайшего целого числа значение
— округленное до ближайшего целого числа значение ![]() . Для нашего примера
. Для нашего примера
![]()
Избыточность — не всегда нежелательное явление. Для повышения помехоустойчивости кодов избыточность необходима и ее вводят искусственно в виде добавочных ![]()
![]() символов (см. тему 6). Если в коде всего п разрядов и
символов (см. тему 6). Если в коде всего п разрядов и ![]() из них несут информационную нагрузку, то
из них несут информационную нагрузку, то ![]() =
=![]()
![]() характеризует абсолютную корректирующую избыточность, а величина
характеризует абсолютную корректирующую избыточность, а величина ![]() характеризует относительную корректирующую избыточность.
характеризует относительную корректирующую избыточность.
Информационная избыточность - обычно явление естественное, заложена она в первичном алфавите. Корректирующая избыточность - явление искусственное, заложена онав кодах, представленных во вторичном алфавите.
Наиболее эффективным способом уменьшения избыточности сообщения является построение оптимальных кодов.
Оптимальные коды[5] - коды с практически нулевой избыточностью. Оптимальные коды имеют минимальную среднюю длину кодовых слов - L. Верхняя и нижняя границыL определяютсяиз неравенства
![]() (49)
(49)
где Н - энтропия первичного алфавита, т - число качественных признаков вторичного алфавита.
В случае поблочного кодирования, где каждый из блоков состоит из М независимых букв ![]() , минимальная средняя длина кодового блока лежит в пределах
, минимальная средняя длина кодового блока лежит в пределах
![]() (50)
(50)
Общее выражение среднего числа элементарных символов на букву сообщения при блочном кодировании
![]() (51)
(51)
С точки зрения информационной нагрузки на символ сообщения поблочное кодирование всегда выгоднее, чем побуквенное.
Суть блочного кодирования можно уяснить на примере представления десятичных цифр в двоичном коде. Так, при передаче цифры 9 в двоичном коде необходимо затратить 4 символа, т. е. 1001. Для передачи цифры 99 при побуквенном кодировании - 8, при поблочном - 7, так как 7 двоичных знаков достаточно для передачи любой цифры от 0 до 123; при передаче цифры 999 соотношение будет 12 - 10, при передаче цифры 9999 соотношение будет 16 - 13 и т. д. В общем случае «выгода» блочного кодирования получается и за счет того, что в блоках происходит выравнивание вероятностей отдельных символов, что ведет к повышению информационной нагрузки на символ.
При построении оптимальных кодов наибольшее распространение нашли методики Шеннона—Фано и Хаффмена.
Согласно методике Шеннона - Фано построение оптимального кода ансамбля из сообщений сводится к следующему:
1-й шаг. Множество из сообщений располагается в порядке убывания вероятностей.
2-й шаг. Первоначальный ансамбль кодируемых сигналов разбивается на две группы таким образом, чтобы суммарные вероятности сообщений обеих групп были по возможности равны. Если равной вероятности в подгруппах нельзя достичь, то их делят так, чтобы в верхней части (верхней подгруппе) оставались символы, суммарная вероятность которых меньше суммарной вероятности символов в нижней части (в нижней подгруппе).
3-й шаг. Первой группе присваивается символ 0, второй группе символ 1.
4-й шаг. Каждую из образованных подгрупп делят на две части таким образом, чтобы суммарные вероятности вновь образованных подгрупп были по возможности равны.
5-й шаг. Первым группам каждой из подгрупп вновь присваивается 0, а вторым - 1. Таким образом, мы получаем вторые цифры кода. Затем каждая из четырех групп вновь делится на равные (с точки зрения суммарной вероятности) части до тех пор, пока в каждой из подгрупп не останется по одной букве.
Согласно методике Хаффмена, для построения оптимального кода N символы первичного алфавита выписываются в порядке убывания вероятностей. Последние ![]() символов, где
символов, где ![]() [6] и
[6] и ![]() - целое число, объединяют в некоторый новый символ с вероятностью, равной сумме вероятностей объединенных символов Последние символы с учетом образованного символа вновь объединяют, получают новый, вспомогательный символ, опять выписывают символы в порядке убывания вероятностей с учетом вспомогательного символа и т. д. до тех пор, пока сумма вероятностей т оставшихся символов после
- целое число, объединяют в некоторый новый символ с вероятностью, равной сумме вероятностей объединенных символов Последние символы с учетом образованного символа вновь объединяют, получают новый, вспомогательный символ, опять выписывают символы в порядке убывания вероятностей с учетом вспомогательного символа и т. д. до тех пор, пока сумма вероятностей т оставшихся символов после ![]() -го выписывания в порядке убывания вероятностей не даст в сумме вероятность, равную 1. На практике обычно, не производят многократного выписывания вероятностей символов с учетом вероятности вспомогательного символа, а обходятся элементарными геометрическими построениями, суть которых сводится к тому, что символы кодируемого алфавита попарно объединяются в новые символы, начиная с символов, имеющих наименьшую вероятность. Затем с учетом вновь образованных символов, которым присваивается значение суммарной вероятности двух предыдущих, строят кодовое дерево, в вершине которого стоит символ с вероятностью 1. При этом отпадает необходимость в упорядочивании символов кодируемого алфавита в порядке убывания вероятностей.
-го выписывания в порядке убывания вероятностей не даст в сумме вероятность, равную 1. На практике обычно, не производят многократного выписывания вероятностей символов с учетом вероятности вспомогательного символа, а обходятся элементарными геометрическими построениями, суть которых сводится к тому, что символы кодируемого алфавита попарно объединяются в новые символы, начиная с символов, имеющих наименьшую вероятность. Затем с учетом вновь образованных символов, которым присваивается значение суммарной вероятности двух предыдущих, строят кодовое дерево, в вершине которого стоит символ с вероятностью 1. При этом отпадает необходимость в упорядочивании символов кодируемого алфавита в порядке убывания вероятностей.