Дипломная работа: Система стиснення відеоданих на основі аналізу ентропійності
Після узяття похідної рівняння здобуває наступний вид:
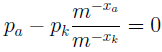 , або
, або![]()
Індекс k може приймати одне з N значень, тобто реально для шкірного фіксованого індексу a є N рівнянь. Просумувавши ці рівняння, одержимо
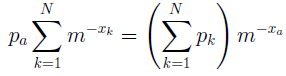
що з урахуванням виконання рівності у вираженні (1.9) рівносильне
![]()
Звідси отримаємо формулу для xa :
| (1.11) |
Таким чином, оптимальний внесок символу, що з'являється з імовірністю p: у довжину результуючого коду становить logm p одиниць інформації в системі подання з підставою m. - анный висновок може бути використаний для обчислення оптимальної довжини коду в рамках тієї або іншої імовірнісної моделі. Одержуючи оцінку ймовірності появи чергового символу на деякому етапі кодування, можна точно визначити оптимальну довжину відповідного інформаційного опису.
1.3 Методи генерації коду
1.3.1 Префіксне кодування
Серед кодів, що задовольняють нерівності Макміллана, особливе місце займають префіксні коди. Система кодів називається префіксною, якщо жоден з кодів, що належить системі, не є качаном (префіксом) іншого коду із цієї ж системи. Очевидне достоїнство префіксного кодування полягає в тім, що одержуваний код може бути легко декодований. Завдяки властивості префікса для того, щоб визначити черговий закодований символ (повідомлення), досить проаналізувати качан відповідної чергової порції коду. При цьому довжина аналізованої порції ніколи не перевищує довжину коду чергового закодованого символу (повідомлення).
Геометрична трактування систем префіксних кодів - m-арные дерева. Властивістьпрефікса гарантує відсутність циклів у графі, ребрам якого зіставлені різні значення інформаційної одиниці. Таким чином, граф є деревом зі ступенем розгалуження, що збігає з підставою системи подання інформації m. Слід зазначити, що нумерація ребер може бути здійснена довільним образом; значення має тільки конкретна структура дерева, а точніше - набір відстаней від кореневого вузла до листових вузлів. Ці відстані відповідають довжинам кодів префіксної системи. Крафт показав, що виконання нерівності (1.7) є гарантією існування кодового дерева зі структурою, що відповідає набору довжин ![]() , що фігурують у нерівності. Інакше кажучи, якщо система довжин задовольняє нерівності (1.7), можна побудувати систему префіксних кодів з відповідними довжинами. Дане твердження дозволяє відмовитися від розгляду систем кодів, відмінних від префіксних. Будь-яка система дешифрованих кодів задовольняє нерівності (1.7), а виходить, вона може бути без шкоди для ефективності замінена системою префіксних кодів. Нерівність (1.7) стосовно до систем префиксних кодів називають також нерівністю Крафта.
, що фігурують у нерівності. Інакше кажучи, якщо система довжин задовольняє нерівності (1.7), можна побудувати систему префіксних кодів з відповідними довжинами. Дане твердження дозволяє відмовитися від розгляду систем кодів, відмінних від префіксних. Будь-яка система дешифрованих кодів задовольняє нерівності (1.7), а виходить, вона може бути без шкоди для ефективності замінена системою префіксних кодів. Нерівність (1.7) стосовно до систем префиксних кодів називають також нерівністю Крафта.
Розглянемо блокове кодування повідомлень довжини n, породжуваних деяким інформаційним джерелом. Як і раніше, позначимо через
![]()
імовірнісний розподіл появи j -ro символу повідомлення (sj - відповідний стан джерела), через pi 1, i2,..., in - імовірність появи повідомлення "i 1 , i 2 ,..., in ". Відповідно до твердження Крафта, можна побудувати систему префіксних кодів із длинами
![]()
(Для доказу досить підставити ці довжини в нерівність Крафта й переконатися в тім, що воно виконується) Оцінимо ефективність кодування з розрахунку на один символ повідомлення:
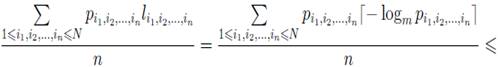
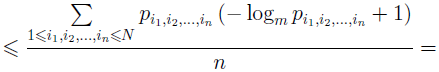
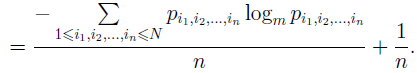
Використовуючи альтернативне вираження для ентропії (1.5), одержуємо
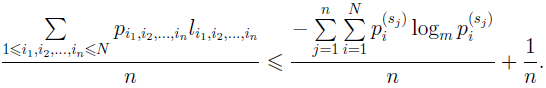
Для випадку стаціонарного джерела з розподілом імовірностей
![]()
маємо:
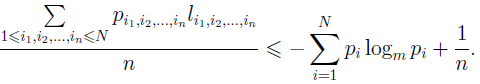
Збільшуючи довжину повідомлення n, можна домогтися ефективності кодування як завгодно близької до ентропії джерела інформації. Таким чином, знаючи апріорі ймовірності появи різних символів на виході джерела в кожен конкретний момент часу, можна організувати кодування даного джерела, наближене до оптимального кодування на кожну наперед задану величину, за умови, що є достатній об'єм інформаційної вибірки.
1.3.2 Алгоритм Шеннона
Алгоритм побудови системи префиксних кодів з довжинами, що залежать від імовірностей по формулі ![]() , був запропонований Шенноном. Алгоритм працює в такий спосіб. Імовірності появи повідомлень p 1 ,p2 ,...,pn розташовуються в порядку убування (тут N - потужність множини повідомлень). Не обмежуючи спільності, можна вважати
, був запропонований Шенноном. Алгоритм працює в такий спосіб. Імовірності появи повідомлень p 1 ,p2 ,...,pn розташовуються в порядку убування (тут N - потужність множини повідомлень). Не обмежуючи спільності, можна вважати
![]() .
.
Як код повідомлення з індексом i беруться перші ![]() m -ичных розрядів числа
m -ичных розрядів числа ![]() так називаної накопиченої ймовірності. Тому що довжини кодів у такій системі не убувають зі зменшенням імовірності й імовірності появи повідомлень із індексами i +1, i +2,...,N відрізняються від імовірності появи повідомлення з індексом i принаймні на
так називаної накопиченої ймовірності. Тому що довжини кодів у такій системі не убувають зі зменшенням імовірності й імовірності появи повідомлень із індексами i +1, i +2,...,N відрізняються від імовірності появи повідомлення з індексом i принаймні на ![]() , код повідомлення з індексом i не є початком кодів повідомлень із індексами i +1, i +2,...,N. Таким чином, система кодів є префіксною. Розглянемо геометричне трактування алгоритму Шеннона. Інтервал [0, 1) може бути розбитий на N підінтервалів
, код повідомлення з індексом i не є початком кодів повідомлень із індексами i +1, i +2,...,N. Таким чином, система кодів є префіксною. Розглянемо геометричне трактування алгоритму Шеннона. Інтервал [0, 1) може бути розбитий на N підінтервалів
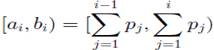 ,
,