Курсовая работа: Алгоритмы сжатия данных
BWT не сжимает данные, но преобразует блок данных в формат, исключительно подходящий для компрессии. Рассмотрим его работу на упрощенном примере. Пусть имеется словарь V из N символов. Циклически переставляя символы в словаре влево, можно получить N различных строк длиной N каждая. В нашем примере словарь-это слово V="БАРАБАН" и N=7. Отсортируем эти строки лексикографически и запишем одну под другой:
FL
АБАНБАР
АНБАРАБ
АРАБАНБ
БАНБАРА
БАРАБАН
НБАРАБА
РАБАНБА
Далее нас будут интересовать только первый столбец F и последний столбец L. Оба они содержат все те же символы, что и исходная строка (словарь). Причем, в столбце F они отсортированы, а каждый символ из L является префиксом для соответствующего символа из F.
Фактический "выход" преобразования состоит из строки L="РББАНАА" и первичного индекса I, показывающего, какой символ из L является действительным первым символом словаря V (в нашем случае I=2). Зная L и I можно восстановить строку V.
Кодирование Хаффмана
Этот алгоритм кодирования информации был предложен Д.А. Хаффманом в 1952 году. Идея алгоритма состоит в следующем: зная вероятности вхождения символов в сообщение, можно описать процедуру построения кодов переменной длины, состоящих из целого количества битов. Символам с большей вероятностью присваиваются более короткие коды. Коды Хаффмана имеют уникальный префикс, что и позволяет однозначно их декодировать, несмотря на их переменную длину.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево). Алгоритм построения Н-дерева прост и элегантен.
1. Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
2. Выбираются два свободных узла дерева с наименьшими весами.
3. Создается их родитель с весом, равным их суммарному весу.
4. Родитель добавляется в список свободных узлов, а двое его детей удаляются из этого списка.
5. Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой - бит 0.
6. Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Допустим, у нас есть следующая таблица частот:
| 15 | 7 | 6 | 6 | 5 |
| А | Б | В | Г | Д |
На первом шаге из листьев дерева выбираются два с наименьшими весами — Г и Д. Они присоединяются к новому узлу-родителю, вес которого устанавливается в 5+6 = 11. Затем узлы Г и Д удаляются из списка свободных. Узел Г соответствует ветви 0 родителя, узел Д — ветви 1.
На следующем шаге то же происходит с узлами Б и В, так как теперь эта пара имеет самый меньший вес в дереве. Создается новый узел с весом 13, а узлы Б и В удаляются из списка свободных. После всего этого дерево кодирования выглядит так, как показано на рис. 2.
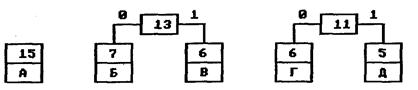
Рис. 2. Дерево кодирования Хаффмана после второго шага
На следующем шаге «наилегчайшей» парой оказываются узлы Б/В и Г/Д. Для них еще раз создается родитель, теперь уже с весом 24. Узел Б/В соответствует ветви 0 родителя, Г/Д—ветви 1.
На последнем шаге в списке свободных осталось только два узла — это А и узел (Б/В)/(Г/Д). В очередной раз создается родитель с весом 39 и бывшие свободными узлы присоединяются к разным его ветвям.
Поскольку свободным остался только один узел, то алгоритм построения дерева кодирования Хаффмана завершается. Н-дерево представлено на рис. 3.
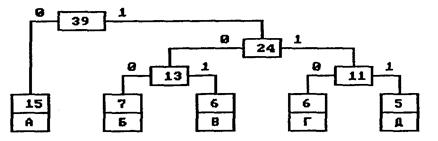
Рис. 3. Окончательное дерево кодирования Хаффмана