Курсовая работа: Сжатие данных методами Хафмана и Шеннона-Фано
Введение
Думая о данных, обычно мы представляем себе ни что иное, как передаваемую этими данными информацию: список клиентов, мелодию на аудио компакт-диске, письмо и тому подобное. Как правило, мы не слишком задумываемся о физическом представлении данных. Заботу об этом - отображении списка клиентов, воспроизведении компакт-диска, печати письма - берет на себя программа, манипулирующая данными.
1. Представление данных
Рассмотрим двойственность природы данных: с одной стороны, содержимое информации, а с другой - ее физическое представление. В 1950 году Клод Шеннон (Claude Shannon) заложил основы теории информации, в том числе идею о том, что данные могут быть представлены определенным минимальным количеством битов. Эта величина получила название энтропии данных (термин был заимствован из термодинамики). Шеннон установил также, что обычно количество бит в физическом представлении данных превышает значение, определяемое их энтропией.
В качестве простого примера рассмотрим исследование понятия вероятности с помощью монеты. Можно было бы подбросить монету множество раз, построить большую таблицу результатов, а затем выполнить определенный статистический анализ этого большого набора данных с целью формулирования или доказательства какой-то теоремы. Для построения набора данных, результаты подбрасывания монеты можно было бы записывать несколькими различными способами: можно было бы записывать слова "орел" или "решка"; можно было бы записывать буквы "О" или "Р"; или же можно было бы записывать единственный бит (например "да" или "нет", в зависимости от того, на какую сторону падает монета). Согласно теории информации, результат каждого подбрасывания монеты можно закодировать единственным битом, поэтому последний приведенный вариант был бы наиболее эффективным с точки зрения объема памяти, необходимого для кодирования результатов. С этой точки зрения первый вариант является наиболее расточительным, поскольку для записи результата единственного подбрасывания монеты требовалось бы четыре или пять символов.
Однако посмотрим на это под другим углом: во всех приведенных примерах записи данных мы сохраняем одни и те же результаты - одну и ту же информацию - используя все меньший и меньший объем памяти. Другими словами, мы выполняем сжатие данных.
1.1.Сжатие данных
Сжатие данных (data compression) - это алгоритм эффективного кодирования информации, при котором она занимает меньший объем памяти, нежели ранее. Мы избавляемся от избыточности (redundancy), т.е. удаляем из физического представления данных те биты, которые в действительности не требуются, оставляя только то количество битов, которое необходимо для представления информации в соответствии со значением энтропии. Существует показатель эффективности сжатия данных: коэффициент сжатия (compression ratio). Он вычисляется путем вычитания из единицы частного от деления размера сжатых данных на размер исходных данных и обычно выражается в процентах. Например, если размер сжатых данных равен 1000 бит, а несжатых - 4000 бит, коэффициент сжатия составит 75%, т.е. мы избавились от трех четвертей исходного количества битов.
Конечно, сжатые данные могут быть записаны в форме недоступной для непосредственного считывания и понимания человеком. Люди нуждаются в определенной избыточности представления данных, способствующей их эффективному распознаванию и пониманию. Применительно к эксперименту с подбрасыванием монеты последовательности символов "О" и "Р" обладают большей наглядностью, чем 8-битовые значения байтов. (Возможно, что для большей наглядности пришлось бы разбить последовательности символов "О" и "Р" на группы, скажем, по 10 символов в каждой.) Иначе говоря, возможность выполнения сжатия данных бесполезна, если отсутствует возможность их последующего восстановления. Эту обратную операцию называют декодированием (decoding).
1.2 Типы сжатия
Существует два основных типа сжатия данных: с потерями (lossy) и без потерь (lossless). Сжатие без потерь проще для понимания. Это метод сжатия данных, когда при восстановлении данных возвращается точная копия исходных данных. Такой тип сжатия используется программой PKZIB®1 : распаковка упакованного файла приводит к созданию файла, который имеет в точности то же содержимое, что и оригинал перед его сжатием. И напротив, сжатие с потерями не позволяет при восстановлении получить те же исходные данные. Это кажется недостатком, но для определенных типов данных, таких как данные изображений и звука, различие между восстановленными и исходными данными не имеет особого значения: наши зрение и слух не в состоянии уловить образовавшиеся различия. В общем случае алгоритмы сжатия с потерями обеспечивают более эффективное сжатие, чем алгоритмы сжатия без потерь (в противном случае их не стоило бы использовать вообще). Для примера можно сравнить предназначенный для хранения изображений формат с потерями JPEG с форматом без потерь GIF. Множество форматов потокового аудио и видео, используемых в Internet для загрузки мультимедиа-материалов, являются алгоритмами сжатия с потерями.
В случае экспериментов с подбрасыванием монеты было очень легко определить наилучший способ хранения набора данных. Но для других данных эта задача становится более сложной. При этом можно применить несколько алгоритмических подходов. Два класса сжатия, которые будут рассмотрены в этой главе, представляют собой алгоритмы сжатия без потерь и называются кодированием с минимальной избыточностью (minimum redundancy coding) и сжатием с применением словаря (dictionary compression).
Кодирование с минимальной избыточностью - это метод кодирования байтов (или, более строго, символов), при котором чаще встречающиеся байты кодируются меньшим количеством битов, чем те, которые встречаются реже. Например, в тексте на английском языке буквы Е, Т и А встречаются чаще, нежели буквы Q, X и Z. Поэтому, если бы удалось закодировать буквы Е, Т и А меньшим количеством битов, чем 8 (как должно быть в соответствии со стандартом ASCII), а буквы Q, X и Z - большим, текст на английском языке удалось бы сохранить с использованием меньшего количества битов, чем при соблюдении стандарта ASCII.
При использовании сжатия с применением словаря данные разбиваются на большие фрагменты (называемые лексемами), чем символы. Затем применяется алгоритм кодирования лексем определенным минимальным количеством битов. Например, слова "the", "and" и "to" будут встречаться чаще, чем такие слова, как "electric", "ambiguous" и "irresistible", поэтому их нужно закодировать меньшим количеством битов, чем требовалось бы при кодировании в соответствии со стандартом ASCII.
2. Сжатие с минимальной избыточностью
Теперь, когда в нашем распоряжении имеется класс потока битов, им можно воспользоваться при рассмотрении алгоритмов сжатия и восстановления данных. Мы начнем с исследования алгоритмов кодирования с минимальной избыточностью, а затем рассмотрим более сложное сжатие с применением словаря.
Мы приведем подробное описание трех алгоритмов кодирования с минимальной избыточностью: кодирование Шеннона-Фано (Shannon-Fano), кодирование Хаффмана (Haffman) и сжатие с применением скошенного дерева (splay tree compression), однако рассмотрим реализации только последних двух алгоритмов (алгоритм кодирования Хаффмана ни в чем не уступает, а кое в чем даже превосходит алгоритм кодирования Шеннона Фано). При использовании каждого из этих алгоритмов входные данные анализируются как поток байтов, и различным значениям байтов тем или иным способом присваиваются различные последовательности битов.
2.1.Кодирование Шеннона-Фано
Первый алгоритм сжатия, который мы рассмотрим - кодирование Шеннона-Фано, названное так по имени двух исследователей, которые одновременно и независимо друг от друга разработали этот алгоритм: Клода Шеннона (Claude Shannon) и Р. М. Фано (R. М. Fano). Алгоритм анализирует входные данные и на их основе строит бинарное дерево минимального кодирования. Используя это дерево, затем можно выполнить повторное считывание входных данных и закодировать их.
Чтобы проиллюстрировать работу алгоритма, выполним сжатие предложения "How much wood could a woodchuck chuck?" ("Сколько дров мог бы заготовить дровосек?") Прежде всего, предложение необходимо проанализировать. Просмотрим данные и вычислим, сколько раз в предложении встречается каждый символ. Занесем результаты в таблицу (см. таблицу 1.1).

Теперь разделим таблицу на две части, чтобы общее число появлений символов в верхней половине таблицы приблизительно равнялось общему числу появлений в нижней половине. Предложение содержит 38 символов, следовательно, верхняя половина таблицы должна отражать приблизительно 19 появлений символов. Это просто: достаточно поместить разделительную линию между строкой o и строкой u. В результате этого верхняя половина таблицы будет отражать появление 18 символов, а нижняя - 20. Таким образом, мы получаем таблицу 1.2.

Теперь проделаем то же с каждой из частей таблицы: вставим линию между строками так, чтобы разделить каждую из частей. Продолжим этот процесс, пока все буквы не окажутся разделенными одна от другой. Результирующее дерево Шеннона-Фано представлено в таблице 1.3.

Я намеренно изобразил разделительные линии различными по длине, чтобы разделительная линия 1 была самой длинной, разделительная линия 2 немного короче и так далее, вплоть до самой короткой разделительной линии 6. Этот подход обусловлен тем, что разделительные линии образуют повернутое на 90° бинарное дерево (чтобы убедиться в этом, поверните таблицу на 90° против часовой стрелки). Разделительная линия 1 является корневым узлом дерева, разделительные линии 2 - двумя его дочерними узлами и т.д. Символы образуют листья дерева. Результирующее дерево в обычной ориентации показано на рис.1.1
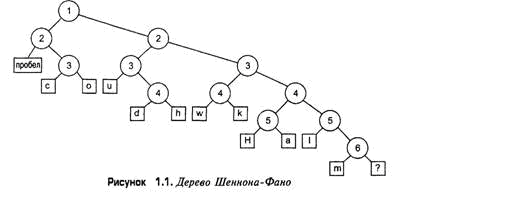
Все это очень хорошо, но как оно помогает решить задачу кодирования каждого символа и выполнения сжатия? Что ж, чтобы добраться до символа пробела, мы начинаем с коневого узла, перемещаемся влево, а затем снова влево. Чтобы добраться до символа c, мы смещаемся влево из корневого узла, затем вправо, а затем влево. Для перемещения к символу o потребуется сместиться влево, а затем два раза вправо. Если принять, что перемещение влево эквивалентно нулевому биту, а вправо - единичному, можно создать таблицу кодирования, приведенную в таблице 11.4.

Cодержит всего 131 бит. Если мы предполагаем, что исходная фраза закодирована кодом ASCII, т.е. один байт на символ, то оригинальная фраза заняла бы 256 байт, т.е. мы получаем коэффициент сжатия 54%.
Для декодирования сжатого потока битов мы строим то же дерево, которое было построено на этапе сжатия. Мы начинаем с корневого узла и выбираем из сжатого потока битов по одному биту. Если бит является нулевым, мы перемещаемся влево, если единичным - вправо. Мы продолжаем этот процесс до тех пор, пока не достигнем листа, т.е. символа, после чего выводим символ в поток восстановленных данных. Затем мы снова начинаем процесс с корневого узла дерева с целью извлечения следующего бита. Обратите внимание, что поскольку символы расположены только в листьях дерева, код одного символа не образует первую часть кода другого символа. Благодаря этому, неправильное декодирование сжатых данных невозможно. (Бинарное дерево, в котором данные размещены только в листьях, называется префиксным деревом (prefix tree).)
Однако при этом возникает небольшая проблема: как распознать конец потока битов? В конце концов, внутри класса мы будем объединять восемь битов в байт, после чего выполнять запись байта. Маловероятно, чтобы поток битов содержал количество битов строго кратное 8. Существует два возможных решения этой дилеммы. Первое - закодировать специальный символ, отсутствующий в исходных данных, и назвать его символом конца файла. Второе - записать в сжатый поток длину несжатых данных перед тем, как приступить к сжатию самих данных. Первое решение вынуждает нас найти отсутствующий в исходных данных символ и использовать его (это предполагает передачу этого символа в составе сжатых данных программе восстановления, чтобы она знала, что следует искать). Или же можно было бы принять, что хотя символы данных имеют размер, равный размеру одного байта, символ конца файла имеет длину, равную длину слова (и заданное значение, например 256). Однако мы будем использовать второе решение. Перед сжатыми данными мы будем сохранять длину несжатых данных, и таким образом во время восстановления будет в точности известно, сколько символов нужно декодировать.
Еще одна проблема применения кодирования Шеннона-Фано, на которую до сих пор мы не обращали внимания, связана с деревом. Обычно сжатие данных выполняется в целях экономии объема памяти или уменьшения времени передачи данных. Как правило, сжатие и восстановление данных разнесено во времени и пространстве. Однако алгоритм восстановления требует использования дерева. В противном случае невозможно декодировать закодированный поток. Нам доступны две возможности. Первая - сделать дерево статическим. Иначе говоря, одно и то же дерево будет использоваться для сжатия всех данных. Для некоторых данных результирующее сжатие будет достаточно оптимальным, для других весьма далеким от приемлемого. Вторая возможность состоит в том, чтобы тем или иным способом присоединить само дерево к сжатому потоку битов. Конечно, присоединение дерева к сжатым данным ведет к снижению коэффициента сжатия, но с этим ничего нельзя поделать.
Листинг программы осуществляющей сжатие данных методом Шеннона приведён в приложении 1.
2.2.Кодирование Хаффмана
--> ЧИТАТЬ ПОЛНОСТЬЮ <--