Курсовая работа: Сжатие речи на основе алгоритма векторного квантования
а)
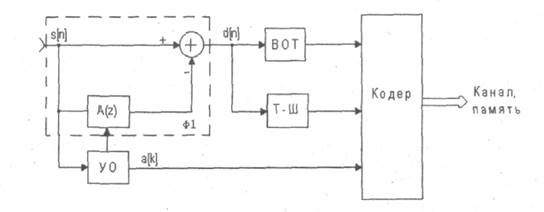 |
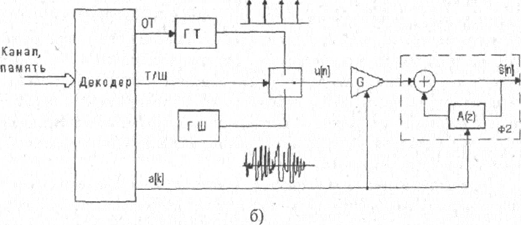
Рисунок 2.1 - Сжатие речевых сигналов в схеме без обратных связей
Для повышения натуральности речи используется схема анализа-синтеза с обратной связью (рисунок 2.2). В этой схеме возбуждающая последовательность формируется путем минимизации ошибки восстановления речевого сигнала, т.е. разности между исходным речевым сигналом s [ n ] и восстановленным сигналом S [ n ]. Восстановленный речевой сигнал формируется с помощью фильтров Ф1 и Ф2, на вход которых подается сигнал с выхода генератора функции возбуждения (ФВ). Фильтр Ф1 учитывает квазипериодические свойства вокализованных участков речи, а фильтр Ф2 моделирует формантную структуру речи. Инверсный фильтр, соответствующий фильтру Ф1, является фильтром долговременного предсказания, а инверсный фильтр, соответствующий фильтру Ф2, называется фильтром кратковременного предсказания.
Фильтр долговременного предсказания описывается передаточной функцией
PL (z) = 1- AL (z), (2.1)
где AL ( z )- az ^- t и t - задержка, соответствующая периоду основного тона, равная 20-150 интервалам дискретизации. Если на вход фильтра долговременного предсказания подать сигнал ошибки кратковременного предсказания dK [ n ], то в соответствии с (2.1) ошибка долговременного предсказания d Д{ [ n ] будет равна:
dД [n] = dK [n] - adK [n-T] (2.2)
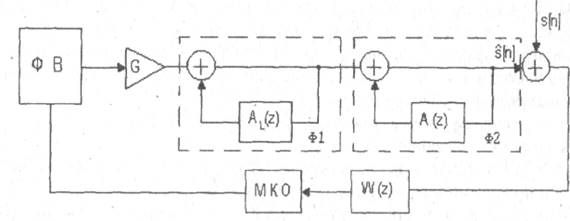
Рисунок 2.2 - Сжатие речевых сигналов в схеме анализ-синтез
Данная ошибка по своим свойствам близка к белому шуму с нормальным законом распределения. Это упрощает формирование сигнала возбуждения, так как при синтезе последовательности S [ n ] ошибка долговременного предсказания выступает в роли сигнала возбуждения.
Фильтр с передаточной функцией W(z) (рисунок 2.2) позволяет учесть особенности слухового восприятия человека. Для человека шум наименее заметен в частотных полосах сигнала с большими значениями спектральной плотности. Этот эффект называют маскировкой. Фильтр W(z) учитывает эффект маскировки и придает ошибке восстановления различный вес в разных частотных диапазонах. Вес выбирается так, чтобы ошибка восстановления маскировалась в полосах речевого сигнала с высокой энергией.
Принцип работы схемы, изображенной на рисунке 2.2, состоит в выборе функции возбуждения (ФВ), минимизирующей квадрат ошибки (МКО) восстановления.
Существует несколько различных способов формирования функции возбуждения: многоимпульсное, регулярно-импульсное и векторное (кодовое) возбуждение. Соответствующие алгоритмы представляют много-импульсное (MLPC), регулярно-импульсное (RPE-LPC) и линейное предсказание с кодовым возбуждением (codeexcitedlinearprediction - CELP). MLPC использует функцию возбуждения, состоящую из множества нерегулярных импульсов, положение и амплитуда которых выбирается так, чтобы минимизировать ошибку восстановления. Алгоритм RPE-LPC является разновидностью MLPC, когда импульсы имеют регулярную расстановку. В этом случае оптимизируется амплитуда и относительное положение всей последовательности импульсов в пределах сегмента речи. CELP представляет способ, который основывается на векторном квантований. В соответствии с этим способом из кодовой книги возбуждающих последовательностей выбирается квазислучайный вектор, который минимизирует квадрат ошибки восстановления. Кодовая книга используется как на этапе сжатия речевого сигнала, так и на этапе его восстановления. Для восстановления сегмента речевого сигнала необходимо знать номер соответствующего вектора возбуждения в кодовой книге, параметры фильтров A \.( z ) и A ( z ), коэффициент усиления СУ. Восстановление речевого сигнала по указанным параметрам выполняется в декодере только с помощью элементов, входящих в верхнюю часть схемы, изображенной на рисунке 2.2.
В настоящее время применяется несколько стандартов, основывающихся на рассмотренной схеме сжатия:
1) RPE-LPC со скоростью передачи 13 Кбит/с используется в качестве стандарта мобильной связи в Европейских странах;
2)CELP со скоростью передачи 4,8 Кбит/с. Одобрен в США федеральным стандартом FS-1016. Используется в системах скрытой телефоннойсвязи;
3)VCELPсо скоростью передачи 7,95 Кбит/с (vectorsumexcitedlinearprediction). Используется в цифровых сотовых системах в Северной Америке. VCELP со скоростью передачи 6,7 Кбит/с принят в качестве стандарта в сотовых сетях Японии;
4)LD-CELP (low-delayCELP) одобрен стандартом МККТТ G.728. Вданном стандарте достигается небольшая задержка примерно 0,625 мс(обычно методы CELP имеют задержку 40-60 мс), используются короткие векторы возбуждения и не применяется фильтр долговременного предсказания с передаточной функцией АL(z).
Необходимо отметить, что рассмотренные методы сжатия речи, использующие линейное предсказание с кодовым возбуждением, хорошо приспособлены для работы с речевыми сигналами в среде без шумов. В случае шумового воздействия на речевые сигналы синтезированная речь имеет плохое качество. Поэтому в настоящее время разрабатывается ряд методов линейного предсказания с кодовым возбуждением для использования в шумовой обстановке (ACELP, CS-CELP).
На рисунке 2.3,а изображена обобщенная схема сжатия речевого сигнала с помощью алгоритмов векторного квантования.
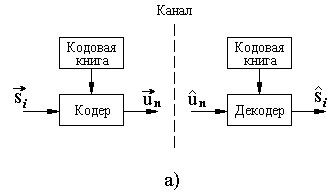 | 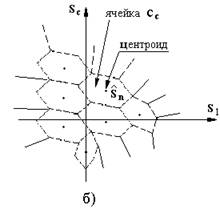 |
Рисунок 2.3 – Векторное квантование
Входной вектор si представляет собой вектор признаков речевого сигнала (например, спектральных),
![]() .
.
Кодер отображает входной вектор ![]() в выходной символ un , n = 1, 2, …, L с помощью кодовой книги. Кодовая книга содержит L векторов
в выходной символ un , n = 1, 2, …, L с помощью кодовой книги. Кодовая книга содержит L векторов
![]() , n = 1, 2, …, L .
, n = 1, 2, …, L .
Предположим, что канал не имеет шумов, т.е. ![]() .
.
Векторный квантователь функционирует следующим образом. Входной вектор ![]() сравнивается с каждым вектором из кодовой книги. В результате из кодовой книги выбирается вектор
сравнивается с каждым вектором из кодовой книги. В результате из кодовой книги выбирается вектор ![]() , ближайший к вектору
, ближайший к вектору ![]() , и в канал передается символ un , представляющий адрес найденного кодового вектора. На приемной стороне с помощью полученного адреса un восстанавливается вектор признаков речевого сигнала
, и в канал передается символ un , представляющий адрес найденного кодового вектора. На приемной стороне с помощью полученного адреса un восстанавливается вектор признаков речевого сигнала ![]() , на основе которого синтезируется речевой процесс. В такой интерпретации векторное квантование, по сути, является распознаванием образов, где вектор
, на основе которого синтезируется речевой процесс. В такой интерпретации векторное квантование, по сути, является распознаванием образов, где вектор ![]() представляет собой входной образ, кодовая книга соответствует базе эталонов.
представляет собой входной образ, кодовая книга соответствует базе эталонов.
В качестве меры расстояния между входными векторами и векторами из кодовой книги обычно используется сумма квадратов отклонений si (k ) и ![]() :
:
 (2.3)
(2.3)