Реферат: Інтелектуальний аналіз даних
Алгоритми пошуку асоціативних правил призначені для знаходження всіх правил X У, причому підтримка і достовірність цих правил повинна бути вищою за деякі наперед певні пороги, звані відповідно мінімальною підтримкою (minsupport) і мінімальною достовірністю (minconfidence).
Задача знаходження асоціативних правил розбивається на дві підзадачі:
а) знаходження всіх наборів елементів, які задовольняють порогу minsupport. Такі набори елементів називаються тими, що часто зустрічаються;
б) генерація правил з наборів елементів, знайдених згідно п. a) з достовірністю, що задовольняє порогу minconfidence.
Один з перших алгоритмів, ефективно вирішальних подібний клас задач, – це алгоритм APriori. Окрім цього алгоритму останнім часом був розроблений ряд інших алгоритмів: DHP, Partition, DIC і інші.
Значення для параметрів мінімальна підтримка і мінімальна достовірність вибираються так, щоб обмежити кількість знайдених правил. Якщо підтримка має велике значення, то алгоритми будуть знаходити правила, добре відомі аналітикам або настільки очевидні, що немає ніякого значення проводити такий аналіз. З другого боку, низьке значення підтримки веде до генерації величезної кількості правил, що, звичайно, вимагає істотних обчислювальних ресурсів. Проте, більшість цікавих правил знаходиться саме при низькому значенні порогу підтримки. Хоча дуже низьке значення підтримки веде до генерації статистично необґрунтованих правил.
Пошук асоціативних правил зовсім не тривіальна задача, як може здатися на перший погляд. Одна з проблем – алгоритмічна складність при знаходженні наборів елементів, які часто зустрічаються, оскільки із зростанням числа елементів експоненційно росте число потенційних наборів елементів.
2.1 Узагальнені асоціативні правила (Generalized Association Rules)
При пошуку асоціативних правил, ми припускали, що всі аналізовані елементи однорідні. Повертаючись до аналізу ринкової корзини, це товари, абсолютно однакові атрибути, що мають, за винятком назви. Проте не складе великих труднощів доповнити транзакцію інформацією про те, до якої товарної групи входить товар і побудувати ієрархію товарів.
Наприклад, якщо Покупець купив товар з групи "Безалкогольні напої", то він купить і товар з групи "Молочні продукти" або "Сік". Ці правила носять назву узагальнених асоціативних правил.
Визначення 2. Узагальненим асоціативним правилом називається імплікація X![]() Y, де X
Y, де X![]() I, Y
I, Y![]() I і X
I і X![]() Y=
Y=![]() і де жоден з елементів, що входять в набір У, не є предком жодного елемента, що входить в X. Підтримка і достовірність підраховуються так само, як і у разі асоціативних правил (див. Визначення 1).
і де жоден з елементів, що входять в набір У, не є предком жодного елемента, що входить в X. Підтримка і достовірність підраховуються так само, як і у разі асоціативних правил (див. Визначення 1).
Введення додаткової інформації про угрупування елементів у вигляді ієрархії дасть наступні переваги:
а) це допомагає встановити асоціативні правила не тільки між окремими елементами, але і між різними рівнями ієрархії (групами);
б) окремі елементи можуть мати недостатню підтримку, але в цілому група може задовольняти порогу minsupport;
в) для знаходження таких правил можна використовувати будь-який з вищеназваних алгоритмів.
Групувати елементи можна не тільки по входженню в певну товарну групу, але і по інших характеристиках, наприклад за ціною (дешево, дорого), бренду і т.д.
Алгоритм пошуку асоціативних правил, заснований на аналізі частих наукових наборів. Спочатку в базі даних транзакцій шукаються усі частини наукових наборів, а потім генеруються асоціативні правила на основі тих з них, які задовольняють заданому рівню підтримки і достовірності.
При цьому для скорочення простору пошуку асоціативних правил використовується властивість апріорності. Воно затверджує, що якщо науковий набір Z не є частим, то додавання будь – якого нового предмету А до набору Z не робить його таким. Іншими словами, якщо набір Z не є частим, то і Z + A – теж.
2.2 Властивість анти–монотонності
Виявлення наборів елементів, що часто зустрічаються, – операція, що вимагає багато обчислювальних ресурсів і, відповідно, часу. Примітивний підхід до рішення даної задачі – простий перебір всіх можливих наборів елементів. Це потребує O(2|I| ) операцій, де |I| – кількість елементів. Apriori використовує одну з властивостей підтримки, що свідчить: підтримка будь-якого набору елементів не може перевищувати мінімальної підтримки будь-якої з його підмножин. Наприклад, підтримка 3–елементного набору {Хліб, Масло, Молоко} буде завжди менше або рівно підтримці 2–елементних наборів {Хліб, Масло}, {Хліб, Молоко}![]() {Масло, Молоко}. Річ у тому, що будь-яка транзакція, що містить {Хліб, Масло, Молоко}, також повинна містити {Хліб, Масло}, {Хліб, Молоко}, {Масло, Молоко}, причому зворотне не вірно.
{Масло, Молоко}. Річ у тому, що будь-яка транзакція, що містить {Хліб, Масло, Молоко}, також повинна містити {Хліб, Масло}, {Хліб, Молоко}, {Масло, Молоко}, причому зворотне не вірно.
Ця властивість носить назву анти–монотонності і служить для зниження розмірності простору пошуку. Не май ми в наявності такої властивості, знаходження багатоелементних наборів було б практично нездійсненною задачею у зв'язку з експоненціальним зростанням обчислень.
Властивості анти–монотонності можна дати і інше формулювання: із зростанням розміру набору елементів підтримка зменшується, або залишається такою ж. Зі всього, що було сказано раніше витікає, що будь–який k–елементний набір буде часто зустрічатися тоді і тільки тоді, коли всі його (k–1)–елементні підмножини будуть часто зустрічатись. Всі можливі набори елементів з I можна представити у вигляді грат, що починаються з порожньої множини, потім на 1 рівні 1–елементні набори, на 2–м – 2–елементні і т.д. На k рівні представлені k–елементні набори, пов'язані зі всіма своїми (k – 1) – елементними підмножинами.
Розглянемо малюнок, ілюструючи набір елементів I – {А, B, З, D}. Припустимо, що набір з елементів {А, B} має підтримку нижче заданого порогу і, відповідно, не є тим, що часто зустрічається. Тоді, згідно властивості анти–монотонності, всі його супермножини також не є тими, що часто зустрічаються і відкидаються. Вся ця гілка, починаючи з {А, B}, виділена фоном. Використовування цієї евристики дозволяє істотно скоротити простір пошуку.
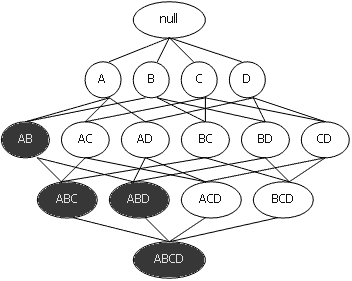
Рисунок 2.1 – Набір елементів I
2.3 Алгоритм Apriori
Для того, щоб було можливе застосувати алгоритм, необхідно провести предобработку даних: по-перше, привести всі дані до бінарного вигляду; по-друге, змінити структуру даних[9]. Вигляд транзакційної бази даних представлен в таблиці 2.1 і таблиці 2.2.
Таблиця 2.1 – Звичайний вигляд
|
Номер транзакції |
Назва елемента |
Кількість |
|
1001 |
К-во Просмотров: 580
Бесплатно скачать Реферат: Інтелектуальний аналіз даних
|