Реферат: Інтелектуальний аналіз даних
Генерація кандидатів також складатиметься з двох кроків.
Крок 1. Об'єднання. Кожний кандидат Cк формуватиметься шляхом
розширення набору розміру (k–1), що часто зустрічається, додаванням елемента з іншого (k–1)–елементного набору.
Приведемо алгоритм цієї функції Apriorigen у вигляді невеликого SQL –подібного запиту.
insert into Ck
select p.item1 , p.item2 ., p.itemk-1 , q.itemk-1
From Fk-1 p, Fk-1 q
where p.item1 = q.item1 , p.item2 = q.item2 ., p.itemk-2 = q.itemk-2 , p.itemk-1 < q.itemk-1
Крок 2. Видалення надмірних правил. На підставі властивості анти–монотонності, слід видалити всі набори с ![]() Ck якщо хоча б одна з його (k–1) підмножин не є тим, що часто зустрічається.
Ck якщо хоча б одна з його (k–1) підмножин не є тим, що часто зустрічається.
Після генерації кандидатів наступною задачею є підрахунок підтримки для кожного кандидата. Очевидно, що кількість кандидатів може бути дуже великою і потрібен ефективний спосіб підрахунку. Найтривіальніший спосіб – порівняти кожну транзакцію з кожним кандидатом. Але це далеко не краще рішення. Набагато швидше і ефективно використовувати підхід, заснований на зберіганні кандидатів в хеш–дереві. Внутрішні вузли дерева містять хеш–таблиці з покажчиками на нащадків, а листя – на кандидатів. Це дерево нам стане в нагоді для швидкого підрахунку підтримки для кандидатів.
Хеш–дерево будується кожного разу, коли формуються кандидати. Спочатку дерево складається тільки з кореня, який є листом, і не містить ніяких кандидатів – наборів. Кожного разу коли формується новий кандидат, він заноситься в корінь дерева і так до тих пір, поки кількість кандидатів в корені – листі не перевищить якогось порогу. Як тільки кількість кандидатів стає більше порогу, корінь перетвориться в хеш–таблицю, тобто стає внутрішнім вузлом, і для нього створюються нащадки – листя. І всі приклади розподіляються по вузлах – нащадкам згідно з хеш–значеннями елементів, що входять в набір, і т.п. Кожний новий кандидат хеширується на внутрішніх вузлах, поки він не досягне першого вузла–листа, де він і зберігатиметься, поки кількість наборів знову ж таки не перевищить порогу.
Хеш–дерево з кандидатами–наборами побудовано, зараз, використовуючи хеш–дерево, легко підрахувати підтримку для кожного кандидата. Для цього потрібно "пропустити" кожну транзакцію через дерево і збільшити лічильники для тих кандидатів, чиї елементи також містяться і в транзакції, тобто Ck ![]() Ti = Ck . На кореневому рівні хеш–функція застосовується до кожного елемента з транзакції. Далі, на другому рівні, хеш–функція застосовується до других елементів і т.д. На k–рівні хеширується k–елемент. І так до тих пір, поки не досягнемо листа. Якщо кандидат, що зберігається в листі, є підмножиною даної транзакції, тоді збільшуємо лічильник підтримки цього кандидата на одиницю.
Ti = Ck . На кореневому рівні хеш–функція застосовується до кожного елемента з транзакції. Далі, на другому рівні, хеш–функція застосовується до других елементів і т.д. На k–рівні хеширується k–елемент. І так до тих пір, поки не досягнемо листа. Якщо кандидат, що зберігається в листі, є підмножиною даної транзакції, тоді збільшуємо лічильник підтримки цього кандидата на одиницю.
Після того, як кожна транзакція з початкового набору даних "пропущена" через дерево, можна перевірити чи задовольняють значення підтримки кандидатів мінімальному порогу. Кандидати, для яких ця умова виконується, переносяться в розряд часто зустрічаємих. Крім того, слід запам'ятати і підтримку набору, вона нам стане в нагоді при витяганні правил. Ці ж дії застосовуються для знаходження (k+1)–елементних наборів і т.д.
Після того, як знайдені всі часто зустрічаємі набори елементів можна приступити безпосередньо до генерації правил.
Витягання правил – менш трудомістка задача. По–перше, для підрахунку достовірності правила достатньо знати підтримку самого набору і множини, що лежить в умові правила. Наприклад, є набір {А, B, С}, що часто зустрічається, і потрібно підрахувати достовірність для правила AB![]() С. Підтримка самого набору нам відома, але і його множина {А, B}, що лежить в умові правила, також часто зустрічається через властивість анти–монотонності, і значить, його підтримка нам відома. Тоді ми легко зможемо підрахувати достовірність. Це позбавляє нас від небажаного перегляду бази транзакцій, який був б потрібен в тому випадку, якщо б це підтримка була невідома.
С. Підтримка самого набору нам відома, але і його множина {А, B}, що лежить в умові правила, також часто зустрічається через властивість анти–монотонності, і значить, його підтримка нам відома. Тоді ми легко зможемо підрахувати достовірність. Це позбавляє нас від небажаного перегляду бази транзакцій, який був б потрібен в тому випадку, якщо б це підтримка була невідома.
Щоб витягнути правило із часто зустрічає мого набору F, слід знайти всі його не порожні підмножини. І для кожної підмножини s ми зможемо сформулювати правило s ![]() (F – s), якщо достовірність правила conf(s
(F – s), якщо достовірність правила conf(s ![]() (F – s)) = supp(F)/supp(s) не менше порогу minconf.
(F – s)) = supp(F)/supp(s) не менше порогу minconf.
Помітимо, що чисельник залишається постійним. Тоді достовірність має мінімальне значення, якщо знаменник має максимальне значення, а це відбувається у тому випадку, коли в умові правила є набір, що складається з одного елемента. Все супермножина даної множини має меншу або рівну підтримку і, відповідно, більше значення достовірності. Ця властивість може бути використана при витяганні правил. Якщо ми почнемо витягувати правила, розглядаючи спочатку тільки один елемент в умові правила, і це правило має необхідну підтримку, тоді всі правила, де в умові стоїть супермножина цього елемента, також мають значення достовірності вище заданого порогу. Наприклад, якщо правило А![]() BCDE задовольняє мінімальному порогу достовірності minconf, тоді AB
BCDE задовольняє мінімальному порогу достовірності minconf, тоді AB![]() CDE також задовольняє. Для того, щоб витягнути всі правила використовується рекурсивна процедура. Важливе зауваження: будь-яке правило, складене з набору, що часто зустрічається, повинне містити всі елементи набору. Наприклад, якщо набір складається з елементів {А, B, С}, то правило А
CDE також задовольняє. Для того, щоб витягнути всі правила використовується рекурсивна процедура. Важливе зауваження: будь-яке правило, складене з набору, що часто зустрічається, повинне містити всі елементи набору. Наприклад, якщо набір складається з елементів {А, B, С}, то правило А![]() B не повинне розглядатися.
B не повинне розглядатися.
3 DATA MINING ЯК ЧАСТИНА СИСТЕМИ АНАЛІТИЧНОЇ ОБРОБКИ ІНФОРМАЦІЇ
3.1 Сховища даних
Інформаційні системи сучасних підприємств часто організовані так, щоб мінімізувати час введення і коректування даних, тобто організовані не оптимально з погляду проектування бази даних. Такий підхід ускладнює доступ до історичних (архівним) даних. Зміни структур в базах даних інформаційних систем дуже трудомісткі, а іноді просто неможливі.
В той же час, для успішного ведення сучасного бізнесу необхідна актуальна інформація, що надається в зручному для аналізу вигляді і в реальному масштабі часу. Доступність такої інформації дозволяє, як оцінювати поточне положення справ, так і робити прогнози на майбутнє, отже, ухвалювати більш зважені і обґрунтовані рішення. До того ж, основою для ухвалення рішень повинні бути реальні дані.
Якщо дані зберігаються в базах даних різних інформаційних систем підприємства, при їх аналізі виникає ряд складнощів, зокрема, значно зростає час, необхідний для обробки запитів; можуть виникати проблеми з підтримкою різних форматів даних, а також з їх кодуванням; неможливість аналізу тривалих рядів ретроспективних даних і т.д.
Ця проблема розв'язується шляхом створення сховища даних. Задачею такого сховища є інтеграція, актуалізація і узгодження оперативних даних з різнорідних джерел для формування єдиного несуперечливого погляду на об'єкт управління в цілому. На основі сховищ даних можливо складання всілякої звітності, а також проведення оперативної аналітичної обробки і Data Mining.
Тоді загальна схема інформаційного сховища буде виглядати наступнім чином:
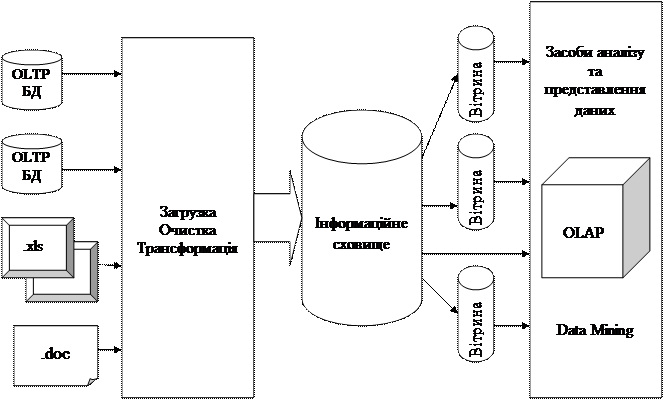
Рисунок 3.1 – Структура інформаційної системи
Біл Інмон (Bill Inmon) визначає сховища даних як "наочно орієнтовані, інтегровані, немінливі, підтримуючі хронологію набори даних, організовані з метою підтримки управління" і покликані виступати в ролі "єдиного і єдиного джерела істини", яке забезпечує менеджерів і аналітиків достовірною інформацією, необхідною для оперативного аналізу і ухвалення рішень[3].
Наочна орієнтація сховища даних означає, що дані з'єднані в категорії і зберігаються відповідно областям, які вони описують, а не застосуванням, що їх використовують.
Інтегрованість означає, що дані задовольняють вимогам всього підприємства, а не однієї функції бізнесу. Цим сховище даних гарантує, що однакові звіти, що згенерували для різних аналітиків, міститимуть однакові результати.
Прив'язка до часу означає, що сховище можна розглядати як сукупність "історичних даних": можливо відновлення даних на будь-який момент часу. Атрибут часу явно присутній в структурах сховища даних.
Незмінність означає, що, потрапивши один раз в сховищі, дані там зберігаються і не змінюються. Дані в сховищі можуть лише додаватися.
Річард Хакаторн, інший основоположник цієї концепції, писав, що мета Сховищ Даних – забезпечити для організації "єдиний образ існуючої реальності"[3].
Іншими словами, сховище даних є своєрідним накопичувачем інформації про діяльність підприємства.