Реферат: Интерактивное исследование неколичественных данных: методика и инструментарий
Е.Б. Белова
В этой статье рассматривается методика интерактивного исследования неколичественных данных, извлекаемых из исторических источников. Предлагаемый подход предполагает активное участие исследователя на каждом шаге компьютерного анализа. Необходимость такого подхода может быть обоснована следующими двумя утверждениями, касающимися характера исторических данных и процесса их анализа.
Во-первых, неколичественные данные по своему происхождению - это, вообще говоря, данные, извлекаемые из текстовых документов, а следовательно, семантически плохо определенные; их структура не обязательно является регулярной. На формальном уровне единицей анализа является поименованная сущность (объект данных), описываемая произвольным набором элементарных свойств (качеств). Другими словами, сущность определяется как подмножество во множестве свойств/качеств. Свойство, в свою очередь, определяет, посредством своей встречаемости, группу сущностей, и следовательно, может рассматриваться как подмножество во множестве сущностей. Таким образом, мы имеем симметрию, позволяющую обрабатывать сущность и ее свойства схожим образом: рассматривая набор данных как два множества, описываемых зависимостью "многие-ко-многим". Однако, надо отметить, что хотя такая симметрия не всегда осмыслена на уровне интерпретации, она всегда присутствует с формальной точки зрения. Поэтому предлагаемый способ анализа существенным образом опирается на этот факт. На практике набор данных существует как последовательность записей, каждая из которых описывает один объект (определяет его имя и набор качеств). Качества могут принадлежать к различным группам. Эти группы могут служить аналогами переменных ("полей" - в терминах баз данных), а качества, им принадлежащие - значениям переменных. Но группы, с одной стороны, могут иметь более одного значения для каждой записи, а с другой стороны, их существование в общем случае необязятельно. Более того, группы качеств могут существовать динамически и приобретать различный смысл в процессе анализа.
Во-вторых, на практике очень сложно, а иногда даже невозможно выбрать a priori верный алгоритм анализа сложных данных. Поэтому предлагаемый в данной статье программный инструмент QualiDatE [1] поддерживает гибкий механизм для создания пользовательских стратегий анализа.
Основной операцией QualiDatE является кластеризация (классификация). Однако, здесь смысл этой процедуры является более широким, чем в традиционном анализе данных: контролируемый пользователем процесс кластеризации позволяет изучать характеристики набора данных с различных точек зрения и в различных измерениях поскольку и объекты данных, и их свойства могут быть классифицированы. Каждый отдельный акт классификации определяется следующим образом:
указываются эталонные объекты, задающие центры искомых классов;
путем введения порога близости (сходства) определяется насколько другие объекты из исследуемого набора должны быть близки к эталонам;
указывается тип классификации. QualiDatE поддерживает два основных типа близости: симметричную и асимметричную:
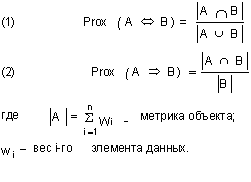
На первый взгляд, асимметричная близость может выглядеть странно, поскольку мы привыкли рассматривать сходство как симметричное отношение. Смысл ее использования состоит в том, что у нас должна быть возможность поставить такие задачи как, например, "найти кластер, в котором бы свойства данного объекта доминировали" или "определить, до какой степени данный объект похож на другие объекты из набора данных" - другими словами, оценить эффект "личности" и "толпы" соответственно. В указанных случаях использование асимметричной меры близости более адекватно.
Симметричная близость (1) в случае объектов данных есть ни что иное, как доля общих свойств среди общего набора свойств двух обектов. Асимметричная близость (2) есть число общих свойств относительно числа всех свойств какого-либо объекта. Оба выражения верны, когда веса веса всех свойств равны. Однако, в QualiDatE заложены механизмы манипулирования весами. Если какое-либо свойство с точки зрения исследователя является более важным в сравнении с другими, то ему может быть присвоен более высокий вес. Вследствие этого близость становится условной мерой, отражающей неодинаковую значимость свойств объектов. Несмотря на отсутствие ограничений на значение веса, оба типа мер близости всегда принимают значения в диапазоне от нуля до единицы.
В то всемя как близость между объектами довольно естественно интерпретируется как количественная похожесть (например, похожесть социальных характеристик двух персон), близость свойств может интерпретироваться как корреляционная мера. Например, асимметричная мера близости свойства "грамотный" и "крестьянин" в некотором воображаемом наборе данных, содержащем персональную информацию (в случае равных весов) определяет долю грамотных людей среди крестьян. Или, в вероятностных терминах - это эмпирическая условная вероятность свойства "грамотый" при условии наличия свойства "крестьянин", которая равна отношению частоты встречаемости свойств "грамотный" и "крестьянин" к частоте встречаемости свойства "крестьянин". Однако, в случае неравных весов, когда, например, некоторые лица не могут быть определенно названы грамотными, близость теряет свой очевидный смысл. Однако, она сохраняет функцию корреляционной меры, т.е. отражает степень согласованности проявления свойств.
Стоит отметить, что в нашем методе не имеет значения, обладают ли сравниваемые объекты данных одинаковым числом свойств, или нет[2].
Рассмотрим теперь уже упоминавшиеся выше типы классификации, поддерживаемые программой QualiDatE.
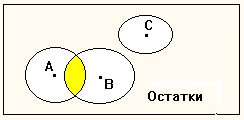
Рис. 1а Разбиение типа покрытие.
Покрытие. В результате этого типа классификации все объекты, расположенные внутри указанных границ, включаются в один кластер. При этом кластеры могут пересекаться, а объекты, не попавшие ни в один из кластеров, образуют так называемый класс остатков (рис. 1а).
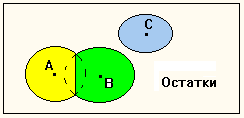
Рис. 1б Разбиение с ограничением.
Разбиение с ограничением отличается от покрытия тем, что области пересечения разбиваются в соответствии с максимальной мерой близости (рис. 1б).
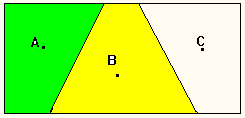
Рис 1в Полное разбиение.
Полное разбиение ведет к тому, что каждый элемент данных обязательно попадает в какой-либо класс[3] (рис. 1в), т.е. от предыдущего оно отличается невозможностью появления класса остатков.
В случае покрытия и разбиения с ограничением используется пара чисел (верхний и нижний пороги), изменяющихся в диапазоне от 0 до 1, и определяющих область кластера. Объект будет включен в класс, если его близость до эталона попадает в заданную порогами область. Если верхний порог равен единице, то будет генерироваться класс похожих объектов. В этом случае нижний порог играет роль критического уровня этой похожести. Однако, в общем случае, исследователь может управлять парой пороговых значений и получать кластеры, имеющие самый разный смысл, вплоть до кластера максимально непохожих на эталон объектов. И конечно, всегда остается возможность установить пару порогов на граничные значения (нижний - на ноль, верхний - на единицу), в результате чего все объекты набора данных будут включены в один класс. Выбор порогов до некоторой степени эквивалентен выбору уровня значимости в статистике, поскольку он так же базируется на соображениях здравого смысла и интуиции эксперта.
Полученные в результате классификации группы объектов могут быть "вырезаны" в отдельные наборы данных и обработаны независимо.
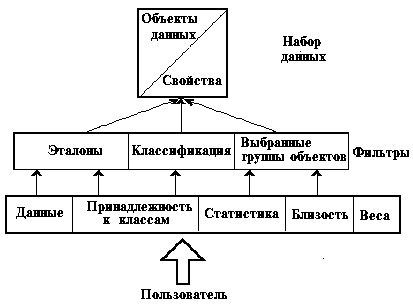
Рис. 2 Концептуальный дизайн программного интерфейса
Интерфейс программы QualiDatE нацелен прежде всего на поддержку интерактивного анализа данных. Концептуальный дизайн программного интерфейса показан на рисунке 2.
Набор данных, который может быть обработан параллельно в двух измерениях (как набор сущностей, и как набор качеств/свойств), предстает перед пользователем в различных видах. Это могут быть исходные данные, близости, веса, статистика, меры принадлежности. Смысл первых трех видов (представлений) достаточно очевиден: статистика представляет числовую информацию о наборе данных (как то: метрики объектов, частоты их встречаемости и т.д.); представление мер принадлежностей играет роль своего рода теста, который может производиться до начала собственно классификации, обнаруживая "ближайшего соседа" для каждой сущности.
--> ЧИТАТЬ ПОЛНОСТЬЮ <--