Реферат: Интерактивное исследование неколичественных данных: методика и инструментарий
Таким образом, исследуемом наборе данных присутствует некоторое число виртуальных уровней информации. Упоминавшиеся ранее стратегии анализа реализуются пользователем (исследователем) как последовательные шаги с одного уровня на другой или их комбинации. При этом возможны различные сценарии. Некоторые из них, которые кажутся наиболее типичными будут разобраны ниже с формальной точки зрения.
Три сценария анализа.
Первый сценарий (см. рис. 3) предполагает, что исследователь имеет представление о том, какие объекты в наборе данных являются типичными - эталонными в терминах решаемой задачи. Другими словами, исследователь знает какого рода классификацию надо применить к данным. Тогда формально задача формулируется следующим образом: найти группы объектов, представляющие искомые классы. Первым шагом в решении такой задачи будет указание известных специфичных объектов - назначение их эталонами. В простейшем случае может быть использовано полное, жесткое разбиение. Вторым и поледним шагом будет сохранение статистической информации для найденных классов. Если же задача выглядит более сложной, например, предполагается существование объектов, выпадающих из общей схемы, или накладываются жесткие требования на однородность искомых классов, то на втором шаге предлагается использовать просмотр значений принадлежности к классам или близостей. Эти возможности нацелены на то, чтобы выбрать разумный для исследуемого набора данных порог похожести, затем применить разбиение с ограничением или покрытие. Статистическое представление результатов в этом случае может быть финалом, а может и служить базой для последующего пересмотра параметров классификации.
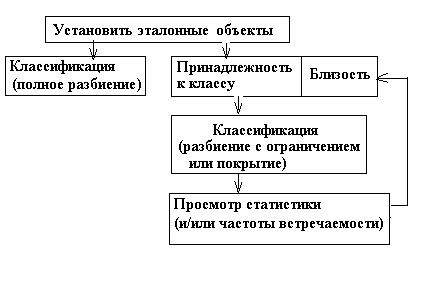
Рис. 3. Схема исследования в соответствии с первым сценарием анализа.
Второй сценарий описывает случай, когда существует некая внешняя (априорная) классификация, определяемая относительно узким набором свойств (см. рис 4).
Тогда задачу можно сформулировать следующим образом: классифицировать объекты по всем другим свойствам в целом и сравнить априорную и апостериорную схемы. Следовательно, мы должны начать с указания свойств, определяющих внешнюю классификацию в качестве эталонных и классифицировать весь набор свойств. В результате этого шага выявляются группы свойств, коррелирующих с эталонными. Теперь в нашем распоряжении имеются группы основных свойств, которые могут подсказать нам, каким образом следует выбрать эталоны среди объектов. На этом шаге разумно установить нулевые веса эталонным свойствам с тем, чтобы они игнорировались при классификации объектов, и повысить веса основных свойств, отличных от эталонных. Теперь классификация даст нам набор эталонных объектов и работа может быть продолжена в соответствии с первым сценарием.
Исследование свойств полученных групп и сравнительная групповая статистика помогает оценить качество классификации. В результате может быть принято решение изменить параметры классификации. Или, если классификация представляется неудовлетворительной, найденные классы и/или объекты, которые не попали ни в один класс, могут быть выделены в новые наборы данных, и для каждого из них всю процедуру можно повторить с самого начала.

Рис. 4. Схема исследования в соответствии со вторым сценарием анализа.
Третий сценарий анализа применим в ситуации, когда ничего определенного об исследуемом наборе данных не известно. В таком случае задача не может быть сформулирована более конкретно, чем "изучить набор данных" (см. рис 5а).
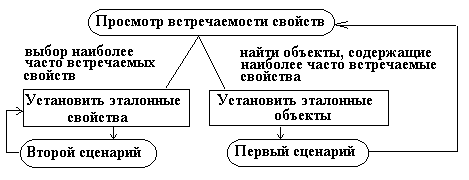
Рис. 5а. Схема исследования в соответствии с третьим сценарием анализа.
Сеанс работы можно начать с просмотра частот свойств. Основываясь на них, пользователь может выбрать несколько наиболее часто встречающихся свойств и принять их за эталонные. Дальнейшая последовательность работы примерно совпадает со вторым сценарием. Альтернативное решение состоит в выборе объектов, содержащих наиболее часто встречаемые свойства, определение их в качестве эталонных и переходе к работе по первому сценарию.

Рис. 5б. Схема исследования в соответствии с третьим сценарием анализа.
В качестве еще одного подхода (см. рис 5б) можно предложить начать сеанс работы с выбора одного объекта в качестве эталона случайным образом. Затем просмотреть близости до него с тем чтобы найти самые непохожие на него объекты, которые потенциально могут служить дополнительными (альтернативными) эталонами. Такого рода предварительный анализ можно продолжать до тех пор, пока не сформируется разумный набор эталонов. После этого снова вступает в действие первый сценарий.
Набор возможных стратегий исследования не ограничивается тремя вышеописанными сценариями. Следует указать по крайней мере еще на три важных применения QualiDatE.
Близость к эталону можно рассматривать как меру принадлежности в смысле теории нечетких множеств. Если исследователь достаточно хорошо знаком с понятиями этой теории, то он может оперировать непосредственно со значениями близости и создавать нечеткие классификации, не используя классификационных функций программы. Кстати говоря, классификация типа покрытие, как она реализована в программе, имеет своим результатом то, что в теории нечетких множеств называется альфа-сечением нечеткого множества.
QualiDatE может использоваться в качестве инструмента для построения кросс-табуляций. Ее отличие от традиционных процедур кросс-табуляции заключается в том, что благодаря определенной взаимозаменяемости понятий группы и сущности, QualiDatE позволяет производить кросс-табуляцию для составных свойств - иначе говоря, для любых комбинаций признаков.
QualiDatE может использоваться как своего рода нечеткая база данных. Выбор объектов на основе близости до эталона может рассматриваться как нечеткий запрос - что-то вроде "найти все, что похоже на это до такой-то степени". Сама эта степень задается установлением весов и порогов. В частном случае нечеткость запроса может быть сведена к нулю, так что его результатом будет являться выборка, основанная на точном совпадении некоторых определенных значений.
* * *
Перейдем к примеру исследования, реализующего то, что выше было описано как второй сценарий.
Предлагаемый к рассмотрению набор данных содержит сведения о членах 1-ой Государственной Думы 1906-ого года. Все данные в нем являются качественными и были извлечены из текстовых источников, таких как биографии, справочники и т.п. Набор данных содержит сведения о фракционной принадлежности каждого депутата и некоторые его социальные характеристики[4].
Рассматриваемые данные используются для выяснения того, существовало ли какое-либо соответсвие между принадлежностъю к фракции и социальным профилем депутата. В центре исследования стоят две наиболее крупные фракции 1-ой Государственной Думы - трудовики и кадеты.
Соответствующая формальная гипотеза, которая должна быть верифицирована, формулируется следующим образом:
cуществуют относительно однородные (в терминах социальных характеристик) группы лиц;
cуществует соответствие между этими группами и принадлежностью к фракции. Т.е. существуют "типичный трудовик" и "типичный кадет", которые представляют ядра своих фракций.
Формальная задача разбивается на следующие четыре шага:
найти типичные характеристики для каждой фракции;
найти эталонных депутатов;