Реферат: Основы экономного кодирования
Прием и декодирование неравномерных кодов - процедура гораздо более сложная, нежели для равномерных. При этом усложняется аппаратура декодирования и синхронизации, поскольку поступление элементов сообщения (букв) становится нерегулярным. Так, к примеру, приняв первый 0, декодер должен посмотреть в кодовую таблицу и выяснить, какой букве соответствует принятая последовательность. Поскольку такой буквы нет, он должен ждать прихода следующего символа. Если следующим символом будет 1, тогда декодирование первой буквы завершится – это будет Б, если же вторым принятым символом снова будет 0, придется ждать третьего символа и т.д.
Зачем же используются неравномерные коды, если они столь неудобны?
Рассмотрим пример кодирования сообщений l i из алфавита объемом K = 8 с помощью произвольного n -разрядного двоичного кода.
Пусть источник сообщения выдает некоторый текст с алфавитом от А до З и одинаковой вероятностью букв Р( l i ) = 1/8.
Кодирующее устройство кодирует эти буквы равномерным трехразрядным кодом (см. табл. 1).
Определим основные информационные характеристики источника с таким алфавитом:
- энтропия источника 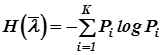 ,
, ![]() ;
;
- избыточность источника 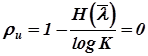 ;
;
- среднее число символов в коде 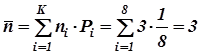 ;
;
- избыточность кода 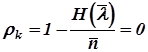 .
.
Таким образом, при кодировании сообщений с равновероятными буквами избыточность выбранного (равномерного) кода оказалась равной нулю.
Пусть теперь вероятности появления в тексте различных букв будут разными (табл. 2).
Таблица 2
|
А |
Б |
В |
Г |
Д |
Е |
Ж |
З |
|
Ра =0.6 |
Рб =0.2 |
Рв =0.1 |
Рг =0.04 |
Рд =0.025 |
Ре =0.015 |
Рж =0.01 |
Рз =0.01 |