Реферат: Возможности анализа данных медико-биологических экспериментов в программе Statistica
Обобщаемость (внешняя обоснованность) результатов исследования отражает, в какой мере результаты данного исследования применимы к другим группам , например к больным другого пола, другой популяции и т.п.
Достоверность и о6общаемость зависят от правильности проведения исследования на всех этапах, в том числе, от грамотной статистической обработки полученных данных [7].
Широкая доступность вычислительной техники дает возможность обработки больших объемов данных, использования различных методов анализа. Кроме того, программа конкретного метода обработки позволяет многократно повторять вычисления с небольшими изменениями без дополнительных усилий. Для большинства стандартных статистических методов существуют пакеты программ, хотя им порой не хватает гибкости, которую в идеале они должны были бы допускать. Для большинства задач с небольшими объемами данных и с относительно простыми методами обработки вполне достаточно обычного калькулятора. Для данных среднего объема лучше пользоваться пакетами стандартных программ. Однако следует избегать использования сложных методов анализа только потому, что имеются соответствующие программы [6].
На сегодняшний день лидером среди программ статистической обработки данных в среде Windows является пакет программного обеспечения (ППО) STATISTICA, который имеет более 250 тыс. зарегистрированных пользователей во всем мире и является наиболее динамично развивающимся пакетом на рынке статистического программного обеспечения. Разработчиком STATISTICA является фирмаStatSoft, Inc., (США). Первая версия системы STATISTICA для DOS, вышедшая в 1991 году, представляла собой новое направление развития статистического программного обеспечения. В ней реализован так называемый графически-ориентированный подход к анализу данных [5,6].
Однако при использовании ППО STATISTICA, как и при работе с любыми другими пакетами статистических программ, принятие решений остается за исследователем. Программа освобождает исследователя от рутинной вычислительной работы, но интерпретация полученных результатов зависит от его опыта и знаний.
Применение статистики в медицинских и биологических исследованиях не ограничивается анализом результатов. Статистические методы следует использовать также на этапе планирования биологического эксперимента или медицинского исследования. Следует подчеркнуть, что с точки зрения клинической эпидемиологии для получения надежных, научно обоснованных результатов необходимы 2 компонента:
· правильное планирование структуры исследования (обеспечивающей возможность получения ответов на поставленные вопросы)
· грамотный статистический анализ [6].
Статистика в медико-биологическом исследовании
statistica статистика медицинский биологический
Всякое исследование должно удовлетворить следующим требованиям:
1. целеустремленность (конкретность задач). При анализе полученных данных могут быть выявлены и дополнительные результаты, не запланированные в исследовании (вторичные данные), однако обычно они представляют меньшую ценность, чем основные (соответствующие поставленной цели) результаты проводимого эксперимента.
2. эффективность , т. е. полученные выводы должны быть достоверны. Достоверность медико-биологических экспериментов обычно оценивается 5% уровнем значимости, и полученные значения, вероятность ошибки 1 рода для которых менее 5 %, автоматически выделяются в STATISTICA красным цветом шрифта. Однако, величина р может составлять 0,049; такое различие статистически значимо, но настолько близко к пороговой величине (0,05), что практически не отличается от, к примеру, 0,051, т. е. статистически незначимого уровня. Наличие подобной условной черты (0,05) представляет собой одну из проблем при использовании величины р.
3. экономность (минимальная затрата сил и средств, риску подвержено минимальное количество участников (как людей, так и животных)). Экономность может быть достигнута подбором минимальной численности групп, достаточной для получения достоверных результатов [5, 6, 8, 10].
4. Полученная последовательность случайных чисел может использоваться разными способами:
5. — четные числа могут соответствовать одной группе, а нечетные — другой (в случае двух групп);
—при числах в диапазоне от 0 до 99, числа меньшие 50, могут соответствовать одной группе, а большие или равные 50 — другой (в случае двух групп);
В результате простой рандомизации группы могут значительно различаться по числу участников, причем различие оказывается весьма существенным, если выборки невелики по объему. В связи с этим простую рандомизацию рекомендуется использовать лишь в масштабных КИ [7].
| Формулирование целей |
| ↓ |
| Планирование |
| ↓ |
| Выполнение (сбор данных) |
| ↓ |
| Подготовка данных |
| ↓ |
| Анализ данных |
| ↓ |
| Интерпретация результатов |
| ↓ |
| Формулировка выводов |
| ↓ |
| Публикация |
Рис. 1—Этапы научного исследования [7].
ППО STATISTICA не имеет модуля для расчета объема выборок.
При подготовке результатов к анализу ввод может осуществляться как в файлы данных ППО STATISTICA (имеют формат *.stа), так и в таблицы пакета МS Ехсеl с последующим импортом в STATISTICA [7]. Данные следует располагать в строках и столбцах электронной таблицы. В строках располагаются наблюдения (объекты исследования), в столбцах — переменные (признаки). Качественные данные могут быть представлены текстовыми значениями, которые автоматически кодируются числовыми значениями, однако такое представление не рекомендуется из-за возрастания вероятности ошибок [7, 10].
Рекомендовано вносить в качестве исходных данных результаты эксперимента без предварительной обработки с необходимым уровнем точности [6].
Первым шагом, предваряющим статистический анализ данных, является анализ типов данных. Это необходимо делать для определения способа представления и статистического метода обработки данных. Не рекомендовано проведение таких предварительных расчетов как:
1. Предварительная разбивка области значении непрерывного количественного признака на интервалы. При этом во-первых происходит потеря информации, а во-вторых— возможности статистического пакета позволяют автоматически осуществить разбивку областей значений количественных признаков на интервалы.
2. Вычисление различных расчетных индексов (коэффициентов, отношений и т.п.). Эти вычисления с большей точностью также могут быть проведены в STATISTICA.
Ошибки ввода (набора) можно выявить следующим способом—дважды щелкнув по имени столбца в открывшемся диалоговом окне выбрать Values/Stats. Ошибки (выпадающие значение) могут попасть в минимальные или максимальные, а ошибки типа двойной запятой—выносятся в правый столбец.
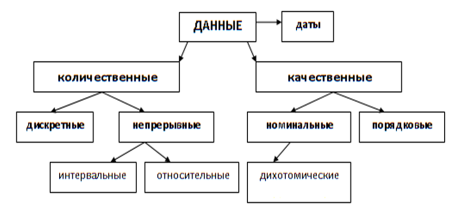
Рис.2—Типы данных [7].
STATISTICA позволяет работать со всеми типами данных. В большинстве модулей анализа ППО ограничивает тип вводимых данных в соответствии с применимостью того или иного метода. Так, при работе в модуле логистической регрессии могут быть использованы только бинарные данные (кодируются 0 и 1).Статистическую обработку данных удобно разбить на следующие четыре этапа.