Реферат: Выборки и их представления
г) Построение двумерной гистограммы:
F.7. Three - Dimensional Histogram - Sample 1: x1, Sample 2: y1 - F6 - Поправляем, если необходимо, параметры графика - F6.
Появляется трехмерный график. Выводим его на печать или сохраняем.
3. Выполнение в пакете STATISTICA
Генерация выборки
Сгенерируем, например, выборку объема n =50 с показательным распределением со средним значением 5.
Создадим новый файл:
File - New Data - укажем имя файла в окне File Name : descript (например) - OK. На экране сетка-таблица; в ее заголовке указаны название и размеры : 10v * 10c - ( 10 переменных ( variables ) - столбцов по 10 наблюдений ( cases ) - строк.
Преобразуем таблицу к размерам 1´50:
кнопка Vars (на экране) - Delete; окно Delete Variables: укажем какие переменные- столбцы убрать : From variable : var 2, To variable : var 10 - OK - Кнопка Cases - Add ( добавление ) - окно Add Cases: укажем, сколько строк добавить и куда : Number of Cases to Add : 40, Insert after Case : 1 ( например ) - OK.
Сгенерируем выборку:
выделим столбец - переменную Var1 ( щелчком мыши по ее заглавию) - нажмем правую клавишу - в открывшемся меню выберем Variable specs ( спецификации переменной ) - в появившемся окне Variable 1 введем Name x ( например ) , в нижнем поле Long name вводится выражение, определяющее переменную. Ввод можно сделать набором на клавиатуре или с помощью клавиши Functions , выбирая в меню Kategory и Name требуемую функцию и вставляя клавишей Insert . Для задания закона распределения следует ввести, например,
=rnd(2) для R [0, 2],
=Vnormal(rnd(1); 2; 0.5 ) для N(2, s2 =0.52 ),
=VExpon(rnd(1); 0.2 ) для E(5) со средним 1/0.2=5; (для нашего примера вместо значения параметра l= 0.2 можно набрать выражение 1/5).
Такая форма задания определяется способом генерации: с помощью функции, обратной (буква V ) к функции распределения и генератора случайных чисел R [0, 1] ( rnd(1)) .
Распечатаем выборку командой Print меню File .
Посмотрим выборку графически:
Graphs - Custom Graphs (настраиваемые графики) - 2D graphs - в открывшемся окне все можно оставить по умолчанию - .OK . Наблюдаемый график (рис.2) распечатаем.
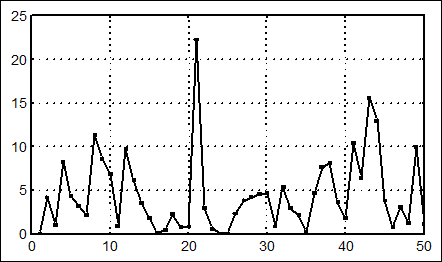
Рис. 2. Наблюдения, распределенные по показательному закону со средним 5 ( n = 50 ).
Построение вариационного ряда
Первый способ:
выделим требуемую переменную (столбец) - нажмем правую клавишу мыши - выберем Quiq Stat s Graphs (быстрые статистики и графики) - Values / Stats of Vars (значения и статистики ) - наблюдаем вариационный ряд и выборочное среднее (mean ) и стандартное отклонение ( SD ).
Второй способ:
войдем в модуль Data Menagement (двойной щелчек левой клавишей мыши на чистом поле и выбор модуля в окне Module Switcher ; если модуль уже загружен, то Alt+Tab до появления модуля) - Analysis Sort - устанавливаем имя переменной, тип сортировки: Ascen (по возрастанию ) или Desc ( по убыванию) - OK .
Функция эмпирического распределения
Первый способ:
Graphs - Stats 2D Graphs - Histogram - в появившемся окне установим: Graph Type : Regular, Cumulative Counts (накопленные частоты), Fit Type (подбираемый тип) : Exponential (для нашего примера) или off (без подбора), Variablles: x, Categories (число интервалов группирования) : 250 - OK .
Наблюдаем график функции эмпирического распределения (рис. 3). График можно отредактировать: изменить линии, точки, фон, шкалы, надписи; для этого необходимо подвести стрелку в нужное иесто и дважды щелкнуть левой клавишей мыши. Выведем его на печать или сохраним.
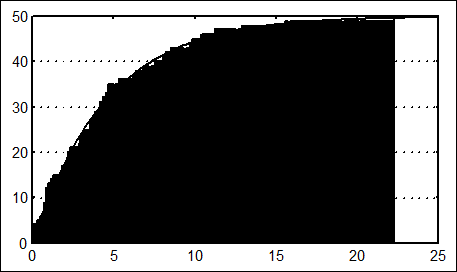
Рис.3. Функция эмпирического распределения