Статья: PageRank: начала анализа
Как известно, количество информации в сети Интернет растет очень быстро, чего нельзя сказать о ее качестве. Пользователь в поисках нужной информации может провести всю жизнь, если только случайно не наткнется на искомый материал; единственный выход для него - воспользоваться поисковиками, которые хранят информацию об адресах и содержимом веб-страниц. Поисковые машины, которые помогают пользователю, пытаются решить проблему - как среди сотен однотипных документов выбрать лучший?
В настоящее время используются текстовые и ссылочные критерии ранжирования страниц при поиске. Первые определяют уместность ("релевантность") документа исходя из наличия слов запроса в тексте и заголовках страницы. Однако, наличие большого количества документов может обесценить изощренные механизмы расчета релевантности, основанные только на содержимом страницы. Это и произошло, когда люди поняли, какую выгоду они получают от целевых посетителей, которых бесплатно предоставляют поисковики. Качество поиска испортилось, количество документов возросло - "релевантный" документ стало очень легко создать.
В целях улучшения качества поиска часть работы по определению "хороших", "важных" документов косвенно возложили на вебмастеров сети. Размещая ссылку на внешний сайт, создатель как бы рекомендует его посетителям своего сайта - именно эту особенность интернета решили использовать для улучшения качества поиска. Повышенная значимость документа определяется, таким образом, с учетом ссылок извне на сайт, содержащий этот документ.
Ссылочные критерии ранжирования помогли несколько исправить положение. Такой критерий достаточно трудно подделать - на это требуется добрая воля других вебмастеров, которые заботятся о качестве своих ресурсов и не будут "продвигать" недостойные сайты. Таким образом, ставка была сделана на саморегуляцию интернета, но новичков такой порядок не устраивал - их просто так никто не пускал в "клуб известных сайтов". И когда новые правила игры были осознаны, поисковики постепенно начали проигрывать.
Однако, как учесть цитируемость ресурса? Ссылки ведь тоже бывают разные. Количество внешних ссылок на сайт не годится для представления цитируемости - с появлением бесплатных хостингов количество ссылок очень легко увеличить. Но важность таких ссылок ничтожна по сравнению со ссылками с известных ресурсов. PageRank и есть такой параметр важности, он выражает цитируемость страницы.
Что такое PageRank и зачем он нужен?
Слово PageRank буквально можно перевести как "ранг страницы". Само название определяет алгоритм расчета цитируемости, разработанный и используемый by Sergey Brin & Larry Page, разработчиками поисковой системы Google. Русские аналоги - Взвешенный Индекс Цитирования (ВИЦ у Яндекса), есть аналог и у Апорта, Рамблер планирует ввести учет цитируемости осенью 2002 года. В дальнейшем будем употреблять обозначения цитируемость и PR наравне с PageRank.
Цитируемость -это число, которое рассчитывается для каждой веб-страницы отдельно, и определяется цитируемостью ссылающихся на нее страниц. Своего рода замкнутый круг.
В чем основная идея? Нужно найти жизненный критерий, выражающий важность страницы. В качестве такого критерия была выбрана теоретическая посещаемость страницы. Была построена модель путешествия пользователя по сети путем перехода по ссылкам. При этом есть вероятность того, что посетителю сайт надоест и он закроет броузер и начнет со случайной страницы (допустим, вероятность этого равна 0.15 на каждом шаге). Соответственно, с вероятностью 0.85 он продолжит путешествие, кликнув на одну из доступных на странице ссылок (все ссылки при этом равноправны). Продолжая путешествие до бесконечности, он побывает на цитируемых страницах много раз, а на нецитируемых - меньше.
Таким образом, PageRank веб-страницы был определен как вероятность нахождения пользователя на этой веб-странице; при этом, конечно, сумма вероятностей по всем веб-страницам сети равна единице - где-то он должен обязательно быть!
Из модели следуют три вывода. Во-первых, PageRank нормируется по всем документам сети. Правда, сами величины, в общем-то, относительны, поэтому при расчетах часто нормируют не на единицу по сумме всех страниц, а на единичный усредненный PR (т.е. суммарный по N страницам PageRank равен N, а в среднем - единица). Пугаться этого не следует, просто PR выражен уже не в единицах вероятности, а в относительных единицах.
Во-вторых, PR передается не полностью, есть "затухание". Поэтому длинные цепочки ссылок на сайте малополезны. С человеческой точки зрения то же самое выражает известное правило "трех кликов".
В-третьих, каждая страница изначально имеет ненулевой PR, но очень маленький.
Относитесь с осторожностью к расчетам PageRank, если-
PR рассчитывается для совокупности страниц без учета "внешнего" PR. PageRank - величина, которая не имеет физического смысла в отрыве от Глобальной сети. Точнее, такой PR - это совсем новый PR.
Выявляются закономерности о "сохранении среднего PR" или проводятся нормировки по ограниченному набору страниц. PageRank определен и действует в глобальном масштабе.
Аналогия
Представьте себе озеро (сайт), в которое впадают ручьи и речки (потоки посетителей, пусть "теоретических"). Количество потоков может быть любым, но река приносит много воды, а ручей мало. Поэтому в свое озеро нужно направлять мощные потоки. Какая-то часть воды "уходит в песок", остальное вытекает из вашего озера и впадает в другие озёра. Часть воды испаряется.
В этом смысле рассмотрение распределения PageRank по страницам сайта в отрыве от внешних источников PageRank аналогично переливанию из пустого в порожнее. По внешнему виду сухого русла сложно представить силу потока в реке. Дождь дает очень мало воды - это и есть PageRank сайта, на который никто не ссылается.
Замечания
PageRank - не единственный ссылочный критерий ранжирования. Он учитывает только наличие ссылки, но не учитывает текст в ссылке, и текст ссылающегося документа.
Алгоритм "выдавливает" наверх в поиске те документы, которые и без поисковика наиболее популярны. Однако введение такого алгоритма при поиске существенно ужесточает конкуренцию, если это поисковик масштаба Google.
Расчет PageRank
Итак, будем рассматривать PageRank страницы как вероятность попадания пользователя на страницу, выраженную в относительных единицах.
PageRank (Pi) страницы i выражается как 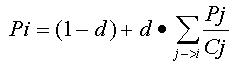 {1}
{1}
где: d -т.н. "damping factor", параметр затухания. Принимается равным 0.85-0.9. Выражает вероятность того, что пользователь, зашедший на страницу, будет продолжать путешествие и переходить по ссылкам. Pi - PageRank интересующей нас страницы i j - обозначение страниц, на которых есть ссылки на i-ю Pj - PageRank страницы j, ссылающейся на i-ю. Сj - Число ссылок на странице j. 1/Сj - Вероятность того, что пользователь, находящийся на странице j, из Сj доступных ему ссылок выберет именно ссылку на нашу страницу i. d*Pj/Сj - поток "теоретической посещаемости", который дойдет до страницы i со страницы j. Суммирование идет по всем страницам, ссылающимся на i-ю. (1-d) - минимальный PageRank страницы. Он не равен нулю за счет того, что пользователь регулярно выбирает новый сайт в качестве стартовой точки.
Однако, на PageRank наложено ограничение: 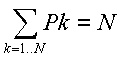
где N - общее количество веб-страниц в Интернет.
Т.е., средний PageRank равен единице. Ограничение это следует из нормировки вероятности пребывания пользователя по всей сети - сумма вероятностей по всем страницам равна единице. Таким образом, Вероятностьi=PageRanki/число страниц в сети
Отметим, что значение PageRank, равное единице, только кажется большим. Количество страниц в сети (N) очень велико, и вероятность 1/N - чрезвычайно мала.
Решая систему уравнений, можно найти PageRank всех страниц в Интернет. Расчет можно вести разными методами:
--> ЧИТАТЬ ПОЛНОСТЬЮ <--