Курсовая работа: Дисперсионный анализ
С точки зрения техники вычислений для нахождения сумм квадратов Q1 , Q2 , Q3 , Q4 , Q целесообразнее использовать формулы:
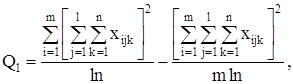
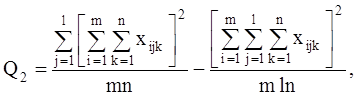
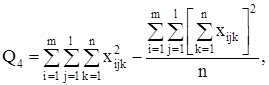
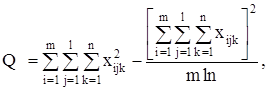
Q3 = Q – Q1 – Q2 – Q4 .
Отклонение от основных предпосылок дисперсионного анализа — нормальности распределения исследуемой переменной и равенства дисперсий в ячейках (если оно не чрезмерное) — не сказывается существенно на результатах дисперсионного анализа при равном числе наблюдений в ячейках, но может быть очень чувствительно при неравном их числе. Кроме того, при неравном числе наблюдений в ячейках резко возрастает сложность аппарата дисперсионного анализа. Поэтому рекомендуется планировать схему с равным числом наблюдений в ячейках, а если встречаются недостающие данные, то возмещать их средними значениями других наблюдений в ячейках. При этом, однако, искусственно введенные недостающие данные не следует учитывать при подсчете числа степеней свободы /1/.
2 Применение дисперсионного анализа в различных процессах и исследованиях
2.1 Использование дисперсионного анализа при изучении миграционных процессов
Миграция - сложное социальное явление, во многом определяющее экономическую и политическую стороны жизни общества. Исследование миграционных процессов связано с выявлением факторов заинтересованности, удовлетворенности условиями труда, и оценкой влияния полученных факторов на межгрупповое движение населения.
λij =ci qij aj ,
где λij – интенсивность переходов из исходной группы i (выхода) в новую j (входа);
ci – возможность и способности покинуть группу i (ci ≥0);
qij – привлекательность новой группы по сравнению с исходной (0≤qij ≤1);
aj – доступность группы j (aj ≥0).
Если считать численность группы i равной ni , то оценкой случайной величины νij - числа переходов из i в j – будет ni ci qij aj :
νij ≈ ni λij =ni ci qij aj . (16)
На практике для отдельного человека вероятность p перехода в другую группу мала, а численность рассматриваемой группы n велика. В этом случае действует закон редких событий, то есть пределом νij является распределение Пуассона с параметром μ=np:
![]() .
.
С ростом μ распределение приближается к нормальному. Преобразованную же величину √νij можно считать нормально распределенной.
Если прологарифмировать выражение (16) и сделать необходимые замены переменных, то можно получить модель дисперсионного анализа:
ln√νij =½lnνij =½(lnni +lnci +lnqij +lnaj )+εij ,
Xi,j =2ln√νij -lnni -lnqij ,
Ci =lnci ,
Aj =lnaj ,
Xi,j =Ci +Aj +ε.
Значения Ci и Aj позволяют получить модель двухфакторного дисперсионного анализа с одним наблюдением в клетке. Обратным преобразованием из Ci и Aj вычисляются коэффициенты ci и aj .
При проведении дисперсионного анализа в качестве значений результативного признака Y следует взять величины:
Yij =Xi,j -X,
Х=(Х1,1 +Х1,2 +:+Хmi,mj )/mimj,
где mimj- оценка математического ожидания Хi,j ;