Курсовая работа: Статистический пакет STATISTIKA
Направление связи определяется знаками ±: близость к +1 означает, что возрастанию одного набора значений соответствует возрастание другого набора, близость к -1 означает обратное.
Для наглядности измерения всех связей в случае множественной корреляции целесообразно использовать корреляционную матрицу – матрицу из попарных коэффициентов корреляции.
Регрессионный анализ
Регрессионный анализ – вид статистического анализа, который состоит в представлении зависимости одних факторов от других в виде некоторой функции (уравнения регрессии ) с помощью которой осуществляется прогнозирование и поиск ответа на вопросы «Что будет через какое-то время?» или «Что будет, если…?».
В случае парной регрессии уравнение определяется подвум наборам данных, один из которых представляет значения зависимой переменной y , а другой – независимой переменной х . В случае множественной регрессии уравнение определяется по нескольким наборам данных, один из которых представляет значения зависимой переменной y , а другие независимыми переменными х1 , х2 ,…, xm .
Получение уравнения регрессии происходит в два этапа: подбор вида функции и вычисление параметров функции.
Выбор функции, в большинстве случаев, производятся среди линейной, квадратичной, степенной и др. видов функций (табл. 2). К функции предъявляются следующие требования: она должна быть достаточно простой для использования ее в дальнейших вычислениях и график этой функции должен проходить вблизи экспериментальных точек так, чтобы сумма квадратов отклонений y -координаты всех экспериментальных точек от y -координат графика функции была ба минимальной (метод наименьших квадратов).
Таблица 2 – Виды функций, применяемых в регрессионных моделях
| Парная (простая) регрессия | Множественная регрессия |
| Линейная регрессия | |
| y=ax+b, | y = а0 + a1 x1 + … +am xm |
| Квадратичная (параболическая) | |
| y=ax2 +bx+c | y= а0 + a1 x1 2 + … +am xm 2 |
| Степенная | |
| y=axb | y = а0 x1 a1 x2 a2 … xm am |
| Логарифмическая y=alnx+b, | Гиперболическая y = а0 + a1 (1/x1 ) + … +am (1/xm ) |
| Экспоненциальная y=aebx | |
| где a, b, c – коэффициенты парной регрессии. | где а0 , a1 ,a2 ,…,am – коэффициенты множественной регрессии, n – объем совокупности, m – количество факторных признаков. |
? Какой вид регрессионного анализа (парный или множественный) в большей степени отвечает реальным условиям?
? Можно ли учесть все факторы х1 , х2 ,… , xm , … в случае множественной корреляции?
Для количественной оценки точности построения уравнения регрессии предназначен коэффициент детерминации R2 , равный квадрату коэффициента корреляции и указывающий, какой процент изменения функции у объясняется воздействием факторов хk . Чем его значение ближе к 1, тем уравнение точнее описывает исследуемую зависимость.
Значимое уравнение (с R2 близким к 1) используется, как правило, для прогнозирования изучаемого явления. Прогноз – это вероятностное суждение о будущем, полученное путем использования совокупности научных методов. Например, прогнозирование финансового состояния выполняется для того, чтобы получить ответы на два вопроса: «как это может быть (какими могут стать финансовые показатели, если не будут приняты меры по их изменению)» и «как это должно быть (какими должны стать финансовые показатели фирмы для того, чтобы ее финансовое состояние обеспечивало высокий уровень конкурентоспособности)». Прогнозирование с целью получения ответа на первый вопрос принято называть исследовательским, на второй – нормативным.
Существует два способа прогнозов по уравнению регрессии: в пределах экспериментальных значений (интерполяция) иза пределами (экстраполяция ). Применимость всякой регрессионной модели ограничена, особенно за пределами экспериментальной области, т.к. характер зависимости может существенно измениться. Поэтому достоверность исследовательского прогноза может быть невысокой. Однако его выполнение полностью обосновано.
1.2 Статистический пакет STATISTICA
Так как статистические методы находят широкое применение во всех сферах производства, то рынок компьютерных технологий предлагает большое количество прикладных программ, которые позволяют проводить такой анализ. Обилие систем, создатели которых утверждают, что их программа является наилучшей для обработки данных, а также отсутствие у большинства специалистов достаточного времени для освоения нескольких пакетов приводит к усложнению процесса выбора. Однако, по данным statsoft.ru, лидером статистических пакетов является STATISTICA.
История развития, области применения
STATISTICA (американской компании StatSoft, http://www.statsoft.com, StatSoft RUSSIA – российское представительство StatSoft) – система, реализующая известные методы статистической обработки и визуализации данных, управления базами данных и разработки пользовательских приложений при помощи встроенного языка программирования Statistica Basic.
Пакет разработан в 1984 г., и первоначально он был представлен в виде модуля для самой популярной в то время электронной таблицы Lotus. Как самостоятеный продукт Statistica впервые заявила о себе в 1991 г. и с тех пор постоянно занимает лидирующее место среди специализированных пакетов по статистике.
Благодаря широкому набор процедур анализа STATISTICA применяется в научных исследованиях, технике, бизнесе. Также система хорошо зарекомендовала себя в страховании (например, в страховой компании РОСНО). STATISTICA широко используется в учебном процессе (в Московском государственном университете, например, на механико-математическом и экономическом факультетах, в Московском институте электроники и математики на экономическом факультете и факультете прикладной математики, в Московском экономико-статистическом институте и др.). Помимо общих статистических и графических средств в системе имеются специализированные модули, например, для проведения социологических или биомедицинских исследований, решения технических и, что очень важно, промышленных задач: Карты контроля качества, Анализ процессов и Планирование эксперимента. Модуль Карта контроля позволяет автоматизировать процесс контроля за качеством производимой продукции, анализировать причины появления отклонений от плановых спецификаций. Statistica осуществляет анализ пригодности (пригодности процессов/механизмов), как одной из важнейших характеристик производственного процесса. Вычисление показателей (или индексов) пригодности позволяет дать ответ на важный вопрос: какое количество изделий попадает в заданные границы инженерного допуска?
Таким образом, STATISTICA является одной из наиболее простых для неподготовленного пользователя систем, с наименьшим периодом овладевания ее возможностями и удачным набор графических возможностей.
Интерфейс, основные возможности
Наборы файлов данных системы STATISTICA (расширение *.sta) можно рассматривать как “рабочие книги” файлов, поскольку они содержат и автоматически сохраняют информацию обо всех дополнительных файлах (например, графиках, отчетах и программах), которые используются с текущим набором данных.
STATISTICA использует стандартный интерфейс электронных таблиц. Текущий файл данных всегда отображается в виде электронной таблицы. Данные организованы в виде наблюдений и переменных. Наблюдения можно рассматривать как эквивалент столбцов электронной таблицы. Каждое наблюдение состоит из набора значений переменной.
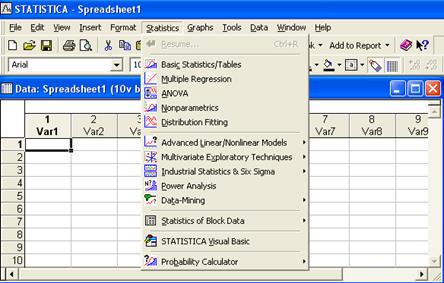
Рис. 1
Система состоит из ряда модулей, работающих независимо. Каждый модуль включает определенный класс процедур. Почти все процедуры являются интерактивными, т.е. для запуска обработки необходимо выбрать из меню переменные и ответить на ряд вопросов системы. Это очень удобно для начинающего пользователя, однако резко замедляет деятельность опытного и не позволяет эффективно повторять одну и ту же процедуру несколько раз.
Модули и процедуры
Описательные статистики
Анализ многомерных таблиц
Подгонка распределений