Реферат: Кластерный анализ в портфельном инвестировании
а) выбранные характеристики допускают в принципе желательное разбиение на кластеры;
б) единицы измерения (масштаб) выбраны правильно.
Выбор масштаба играет большую роль. Как правило, данные нормализуют вычитанием среднего и делением на стандартное отклонение, так что дисперсия оказывается равной единице.
2. Кластерный анализ в портфельном инвестировании
Общеизвестно, что изменение курсовой стоимости и дивидендов различных ценных бумаг не только в России, но и во всем мире зависит от ряда внутренних и международных факторов экономического и неэкономического характера. Эти факторы могут быть взаимосвязаны в различной степени, а тенденции изменения их динамики способны отличаться друг от друга в достаточно сильной степени. Следовательно, изменение стоимости инвестиционного портфеля в результате сложения различных тенденций с большой вероятностью оказывается достаточно сложной и практически непредсказуемой, если использовать обычный регрессионный анализ. Основные факторы воздействия влияют на различные ценные бумаги не только с разной эффективностью, но зачастую и в прямо противоположных направлениях. К примеру, повышение цен на нефть может благоприятно сказаться на ценных бумагах нефтяных корпораций, негативно отразившись на автомобилестроительном секторе.
В свете вышесказанного, перед инвесторами возникают следующие проблемы:
1) Определение с максимальной степенью точности существенных факторов и их влияние на курс ценных бумаг;
2) Составление научно-обоснованного прогноза динамики поведения этих ценных бумаг, основываясь на изучении данных факторов;
3) Составление на основе полученных сведений о фондовом рынке оптимального инвестиционного портфеля, позволяющего максимизировать прибыль от вложений при заданной степени риска.
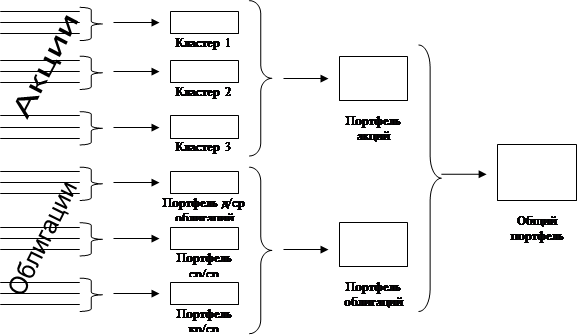 Рис.1 Группировка ценных бумаг со сходными тенденциями
Рис.1 Группировка ценных бумаг со сходными тенденциями
Как теоретики, так и практики, занимающиеся оптимизацией портфеля ценных бумаг, регулярно сталкиваются с трудностями, когда перед ними возникает практически неизбежная задача разбиения множества существующих ценных бумаг на различные группы с относительно однородной структурой. Краеугольным камнем проблемы является вопрос подбора и согласования выбранных факторов так, чтобы их представление в многомерной системе координат достаточно точно производило разбиение на кластеры, характеризующиеся максимально схожими тенденциями. При этом нужно учитывать, что даже если бы и удалось подобрать точные коэффициенты для существующих количественных факторов, всегда найдутся не менее важные качественные показатели, выразить которые в количественной форме практически невозможно. В связи с этим принято группирование ценных бумаг на основе существующих индустриальных и прочих классификаций, а также отталкиваясь от априорной доходности (ex ante).
Разбиение множества ценных бумаг на отдельные кластеры в зависимости от динамики доходности осуществляется следующим образом: данные по доходности ценных бумаг на протяжении базы прогноза компонуются в общую матрицу вида:
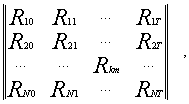 [1,стр.143]
[1,стр.143]
где Rkm – доходность по k -й ценной бумаге за m -й период,
![]()
Далее, разбиение на кластеры происходит через вычисление евклидова расстояния между ценными бумагами p и q по формуле
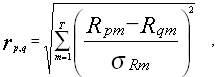 [1,стр.144]
[1,стр.144]
где m – номер периода,
s Rm – среднеквадратическое отклонение доходности за период m .
Критическая величина разбиения предполагается равной квадратному корню из количества периодов T , то есть средней величине евклидового расстояния:
![]() [1,стр.144]
[1,стр.144]
Преимущество данной методики заключается, во-первых, в том, что она позволяет с крайне высокой степенью точности группировать ценные бумаги со сходными тенденциями в изменении доходности на протяжении всего периода, определяющего базу прогноза, что дает основания рассчитывать на сохранение подобной тенденции и в дальнейшем.
Вторым ее преимуществом является возможность полной автоматизации, что значительно облегчает работу, позволяя использовать современные вычислительные средства, а также обрабатывать однородную информацию, получаемую из электронных баз данных. Поэтому она может быть без особых затруднений внедрена не только в компьютерных системах отдельных фирм, занимающихся инвестированием, но также и на соответствующих ресурсах сети интернет.
Пожалуй, наиболее острой проблемой, возникающей перед специалистами по факторному анализу, является подбор четких и ясных критериев, позволяющих отсеять малозначимые факторы, повышающие размерность модели без увеличения ее точности, и при этом правильно определить вес для остальных факторов. Доказательством важности этого вопроса, а также отсутствия однозначно оптимальных решений, является изобилие всевозможных критериев отбора значимых компонент. Достаточно назвать такие известные методы, как расчет варимакс-критерия, n-критерий, отбор при помощи t-критерия Стьюдента и т.п.
Очевидно, что вводить в модель очередной фактор целесообразно только в том случае, если он в достаточной степени понижает уровень энтропии, а, следовательно, увеличивает значение R -квадрат. Каким образом численно выразить прирост данной величины в зависимости от количества вводимых факторов? Рассмотрим эту проблему в свете коэффициентов последовательной детерминации.
Пусть имеются N факторов X1 ...XN , предположительно влияющих на доходность инвестиционного портфеля. При вводе в уравнение регрессии фактора Xi показатель R -квадрат принимает некоторое определенное значение. Выберем фактор, при котором оно будет наибольшим:
![]() [1,стр.145]
[1,стр.145]
где P1 2 - коэффициент последовательной детерминации для данного фактора,