Реферат: Кластерный анализ в портфельном инвестировании
![]() [2,стр.245]
[2,стр.245]
а ожидаемая в следующем периоде доходность будет равна
![]() [2,стр.249]
[2,стр.249]
При этом коэффициент неопределенности для каждой ценной бумаги равняется
![]() [2,стр.251]
[2,стр.251]
а величина риска -
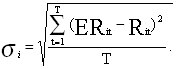 [2,стр.253]
[2,стр.253]
5.Определение оптимального набора ценных бумаг и их долевого весам в инвестиционном портфеле для максимизации доходности.
После всех проведенных преобразований получена для каждой ценной бумаги величину ожидаемой доходности и оценку имеющегося риска. Теперь задача сводится к тому, чтобы определить долевой вес этих ценных бумаг в инвестиционном портфеле с целью максимизации прибыли при заданном уровне риска s п .
Как известно, множество эффективных портфелей расположено на так называемой эффективной границе, не ниже точки минимизации риска. Следовательно, в случае наличия определенности относительно желаемого уровня риска оптимальная точка для заданного набора ценных бумаг может быть определена однозначно:
Основываясь на данных, полученных на трех предыдущих этапах, исходные формулы выглядят следующим образом:
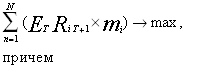
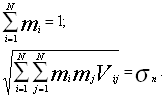 [2,стр.260]
[2,стр.260]
Как уже отмечалось, в случае необходимости добавляется условие не отрицательности долей mi .
Вывод: полученная задача легко решается как при помощи стандартно используемых вычислительных методов, так и большинством математических и экономических программных пакетов (MathCAD, SAS, Solver for MS Excel и т.д.).
4. Кластеризация «голубых фишек» российского фондового рынка
В данном разделе проведен анализ наличия кластеров наиболее ликвидных акций российского рынка. Результаты кластеризации отражены на рис. 2.
Т.к. данный анализ построен на корреляции переменных, то мы видим, что наиболее близкие друг другу переменные это РАО ЕЭС (EESR), Мосэнерго (MSNG), Сургутнефтегаз (SNGS), Газпром (GSPBEX) и Татнефть (TATN). То есть на протяжении больше чем одного года, котировки данных акций кореллировали друг с другом, причем очень сильно. Учитывая, что это происходило в прошлом, скорее всего так будет и в будущем.
Следующий кластер - Сибнефть (SIBN) и Ростелеком (RTKM).Также очень зависимы друг от друга.
Рис. 2 «Результаты кластеризации».
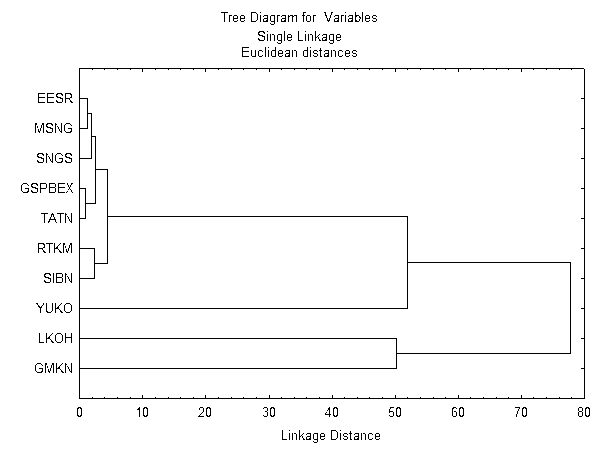
Остальные два кластера имеют большое расстояние в Евклидовом пространстве, т.е. котировки этих акций не кореллируют между собой.
Для оценки надежности данных высказываний используем метод корелляции Спирмена непараметрической статистики.
Таблица 2 – Насколько надежен первый кластер.
| Сравниваемые эмитенты | Коэффициент корреляции Спирмена R | Уровень значимости p-level |
| EESR & GSPBEX | 0,806077 | 0,000000 |
| EESR & TATN | 0,785205 | 0,000000 |
| EESR & MSNG | 0,943979 | 0,000000 |
| EESR & SNGS | 0,903574 | 0,000000 |
| SNGS & EESR | 0,903574 | 0,000000 |
| SNGS & MSNG | 0,863814 | 0,000000 |
| TATN & GSPBEX | 0,779617 | 0,000000 |
| TATN & MSNG | 0,753098 | 0,000000 |
| TATN & SNGS | 0,874308 | 0,000000 |
Корелляция достаточно сильная, с уровнем значимости менее 0.05. Вывод : Кластер надежен
Таблица 2 – Насколько надежен второй кластер (Сибнефть и Ростелеком)
| Сравниваемые эмитенты | Коэффициент корелляции Спирмена R | Уровень значимости p-level |
| RTKM & SIBN | 0,946897 | 0,00 |
Вывод : Кластер надежен, корелляция достаточно высокая, с уровнем значимости менее 0.05
Таким образом, при оптимизации структуры портфеля, можно объединить некоторые акции в отдельные кластеры, что при большом количестве активов существенно упрощает расчеты.
ЗАКЛЮЧЕНИЕ
Кластерный анализ включает в себя набор различных алгоритмов классификации. Общий вопрос, задаваемый исследователями во многих областях, состоит в том, как организовать наблюдаемые данные в наглядные структуры. В общем, всякий раз, когда необходимо классифицировать "горы" информации к пригодным для дальнейшей обработки группам, кластерный анализ оказывается весьма полезным и эффективным. Кластерный анализ необходим для классификации информации, с его помощью можно определенным образом структурировать переменные и узнать, какие переменные объединяются в первую очередь, а какие следует рассматривать отдельно.
Большое достоинство кластерного анализа в том, что он позволяет производить разбиение объектов не по одному параметру, а по целому набору признаков. Кроме того, кластерный анализ в отличие от большинства математико-статистических методов не накладывает никаких ограничений на вид рассматриваемых объектов, и позволяет рассматривать множество исходных данных практически произвольной природы. Это имеет большое значение, например, для прогнозирования конъюнктуры, когда показатели имеют разнообразный вид, затрудняющий применение традиционных эконометрических подходов.
Как и любой другой метод, кластерный анализ имеет определенные недостатки и ограничения: В частности, состав и количество кластеров зависит от выбираемых критериев разбиения. При сведении исходного массива данных к более компактному виду могут возникать определенные искажения, а также могут теряться индивидуальные черты отдельных объектов за счет замены их характеристиками обобщенных значений параметров кластера. При проведении классификации объектов игнорируется очень часто возможность отсутствия в рассматриваемой совокупности каких-либо значений кластеров. Первоначально неизвестно число кластеров, на которое необходимо разбить исходную совокупность элементов, и визуальные наблюдения в многомерном случае просто не приводят к успеху.
Описанная методика позволяет оптимально решить сразу две важнейшие проблемы: разбиение множества ценных бумаг на отдельные однородные группы, а также выявление факторов воздействия внешней среды, влияющих на данные группы с последующим нахождением факторных весов. Это позволяет избежать искусственной дискретности, возникающей при жестком выборе факторов внешней среды и сортировке компаний исключительно по отраслям (например, с использованием сектор-факторов).