Контрольная работа: Логарифмічно-лінійний аналіз
При цьому не виявляється дуже важлива інформація про зміну інтенсивності зв'язку змінних із зміною їх значень: при одних значеннях зв'язок ознак може бути щільним, при інших – слабким і навіть взагалі не спостерігатися. Узагальнюючи різний ступінь інтенсивності зв'язку в єдиному показнику, ми можемо дійти парадоксальних висновків, загубити практично значущі випадки. Щоб уникнути цього, корисно аналізувати окремі фрагменти початкової таблиці. Перехід від таблиці в цілому до окремих її частин доцільний як у разі багатовимірного аналізу, так і за наявності великого числа категорій двовимірного розподілу. На виділення частинних зв'язків заснована ціла низка статистичних методів, наприклад дисперсійний аналіз, логлінійний аналіз.
Використання розкладання статистики χ2 припускає перетворення вихідної таблиці спряженості в безліч таблиць розмірністю 2×2, кожна з яких характеризує особливий аспект зв'язку, що вивчається, – зв'язок між певними значеннями змінних. Число таких таблиць повинне дорівнювати числу ступенів вільності критерію χ2 , при його обчисленні за вихідною таблицею. Кожний з локальних зв'язків у виділеному фрагменті загальної таблиці оцінюється за допомогою критерію χ2 ,що має одну степінь вільності. Зв'язок загальної величини статистики χ2 із значеннями, знайденими по виділених частинах таблиці, виражається рівністю:
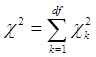 (2.3)
(2.3)
де χk 2 – k –та компонента загальної величини χ2 , знайдена за загальною таблицею 2х2.
Рівність (2.3) справедлива при означенні оцінки χ2 методом максимальної правдоподібності (χML 2 ), яка має вигляд:
![]() (2.4)
(2.4)
Зазвичай вираз (2.4), знайдений відповідно до загального методу найменших квадратів, не має властивості адитивності: в цьому випадку сума окремих χk 2 не обов'язково буде точно дорівнювати загальному χ2 для всієї таблиці. Відмітимо, що властивість адитивності χML 2 використовується в одному з сучасних методів багатовимірного аналізу якісних змінних – логлінійному аналізі.
3. Канонічна кореляція в аналізі таблиць спряженості
Один з напрямів аналізу таблиці спряженості пов'язаний з «оцифруванням» якісних ознак – з приписуванням градаціям якісних змінних числових міток. Такий підхід дозволяє розповсюдити на якісні дані методи багатовимірного статистичного аналізу, розроблені відносно кількісних змінних.
Іноді необхідно побудувати систему міток, що забезпечує максимум коефіцієнта кореляції між двома змінними (оптимальні мітки). Ця система міток і відповідна їй матриця кореляції використовується потім для факторного і регресійного аналізу. Знаходження оптимальних міток пов'язане з перетворенням частот таблиці в частоти двовимірного нормального розподілу, оскільки кореляція перетвореного розподілу не може за абсолютною величиною перевищувати кореляцію двовимірного нормального розподілу. Перетворені таким чином змінні називають канонічними змінними . Розглянемо використання оптимальних міток для аналізу структури даних – виділення в таблиці спряженості лінійних і нелінійних ефектів. Звичайно при вивченні таблиці спряженості не робиться ніяких припущень щодо характеру зв'язку змінних, тоді як в конкретних дослідженнях буває важливо зрозуміти, чи відповідає фактичний розподіл гіпотезі, що висувається, – наприклад, гіпотезі про наявність лінійного зв'язку – чи ні, чи є розузгодження фактичних і теоретичних частот випадковими чи дійсно зв'язок змінних включає ряд складних взаємозв'язків.
Дослідити це питання дозволяє критерій χ2 через адитивні компоненти, які відповідають лінійним і нелінійним ефектам в структурі зв'язку між змінними. При цьому лінійні ефекти пов’язують з першим перетворенням змінних, нелінійні – з другим і т.д. перетвореннями. Адитивність ефектів випливає з ортогональності канонічних змінних.
Покажемо, що канонічний аналіз таблиці зв'язаності відповідає розкладанню статистики χ2 на ряд доданків, число яких залежить від розмірності таблиці. Перетворимо вираз таким чином:
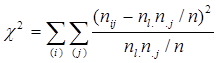 (3.1)
(3.1)
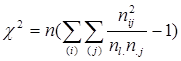 (3.2)
(3.2)
Остання формула може бути подана за допомогою суми діагональних елементів, тобто слід симетричної матриці ![]() , де N - матриця розмірності (m × p) з елементами
, де N - матриця розмірності (m × p) з елементами ![]() (m – число рядків таблиці, p – число стовпців):
(m – число рядків таблиці, p – число стовпців):
![]() (3.3)
(3.3)
Якщо число рядків таблиці не дорівнює числу стовбців, то, як правило, матрицю С формують так, щоб її розмірність була мінімальною (min(m,p)). Оскільки слід матриці дорівнює сумі її власних чисел, то вираз (3.3) приймає наступний вигляд:
![]() (3.4)
(3.4)
де λk - k-е власне число матриці С.
Враховуючи, що власні числа є показниками кореляції (R2 ) між кожною парою канонічних змінних, виділених з вихідних наборів даних, запишемо рівність (3.4) у вигляді:
![]() (3.5)
(3.5)
З m (або p) власних чисел матриці С максимальне завжди дорівнює одиниці, йому відповідає вироджений набір міток 1 = (1,...,1). Тому вираз (3.5) доцільно переписати так :
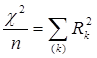 (3.6)
(3.6)
Найбільше з чисел, що залишилися (m - 1) або (p - 1) власних чисел відповідає гіпотезі лінійності зв'язку між категоризованими змінними; наступне за величиною значення λk відповідає гіпотезі про складніший характер взаємозв’язку змінних. Така інтерпретація компонент χ2 представляється можливою з причини того, що кожна подальша пара канонічних змінних є функцією першої перетвореної пари, а все розкладання χ2 є спадаючою послідовністю.
Можна показати, що традиційні методи зв'язків, засновані на критерії χ2 , змішують різні за характером зв'язки і знайдена міра є середньою з різних зв'язків, що ігноруються за однією таблицею. Це випливає з виразу (3.6), який дозволяє будь-який показник щільності зв'язку подати через канонічні кореляції. Наприклад, коефіцієнт взаємної спряженості Чупрова виглядатиме так:
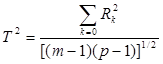 (3.7)
(3.7)
Таблиці 2×2 виділяються два власних числа матриці С. Оскільки перше дорівнює одиниці, то квадрат канонічної кореляції дорівнює квадрату коефіцієнта спряженості Пірсону:
![]() (3.8)
(3.8)
Канонічні змінні дозволяють одержати якнайкраще, в сенсі деякого критерію, наближення коміркових частот таблиці спряженості. Як показали М. Кендалл і А. Стьюард, кожна спостережувана комірка може бути розбита на теоретичну частоту, яка відповідає гіпотезі про незалежність змінних, і адитивний внесок, пов'язаний з канонічною кореляцією:
![]() (3.9)
(3.9)