Курсовая работа: Алгоритмы преобразования ключей
· отношения между элементами просты настолько, что можно исключить потребность в средствах хранения информации об их отношениях в какой бы то ни было форме.
Исходя из этих свойств, данные структуры данных и называют статическими. Снять подобные ограничения можно, используя другой тип данных — списки. Для них подобных ограничений не существует.
Преобразование ключей
Наиболее часто встречается операция поиска записи по идентифицирующему его полю - ключу . Поэтому файл, как правило, индексируется по ключевому полю. Поиск по ключу в общем виде может рассматриваться как преобразование значения ключевого поля в адрес записи в файле (или номер записи), то есть как функция вида f(key) -> m.
Очевидно, можно сформулировать обратную задачу: если некоторым образом подобрать функцию f(), то ее можно использовать для определения места в файле, куда следует поместить запись с ключом key. Основное требование к такой функции: она должна как можно более равномерно распределять записи с различными значениями ключа по файлу, то есть иметь "случайный" вид. Кроме того, необходимо каким-то образом решить проблему "коллизий", то есть попадания нескольких записей с различными ключами в один физический адрес (номер записи).
Функция f() называется распределяющей или рассеивающей функцией. Пример одной из таких функций: берется квадрат значения ключа, из него извлекаются n значащих цифр из середины, которые и дают значение номера записи в файле:
int Place1024(key) // Функция рассеивания для файла из
unsigned key; // 1024 записей и 16 разрядного
{ // ключа
unsigned long n,n1;
int m;
n = (unsigned long)key * key;
for (m=0, n1 = n; n1 !=0; m++, n1 >>= 1); // Подсчет количества значащих
if (m < 10) return(n); // битовв n
m = (m - 10) / 2; // m - количество битов по краям
return( (n >> m) & 0x3FF);
}
Известны два способа решения проблемы коллизий. В первом случае файл содержит область переполнения . Если функция f() вычисляет адрес записи в файле, а соответствующее место уже заполнено записью с другим значением ключа, то новая запись помещается в область переполнения. При этом возможны два варианта:
- записи в области переполнения не связаны между собой, и для поиска в ней используется последовательный просмотр всех записей;
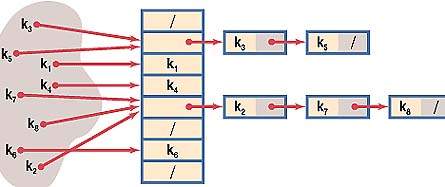
- в области переполнения организуются списки записей, участвующих в коллизии: то есть запись в основной области является заголовком списка записей в области переполнения, куда попадают все записи, вступающие в коллизию.
В другом случае запись, вступившая в коллизию, помещается в некоторое свободное место файла, начиная от текущей занятой позиции. Возможные варианты поиска:
- первая свободная позиция, начиная от текущей;
- проверяются позиции, пропорциональные квадрату шага относительно текущей занятой, то есть m = ( f(key) + i * i ) mod n, где i - номер шага, n - размер таблицы. Такое размещение позволяет лучше "рассеивать" записи при коллизии.
Рассматриваемый метод обозначается терминами расстановка или хеширование (от hash - смешивать, перемалывать).
Одним из существенных недостатков метода является необходимость заранее резервировать файл для размещения записей с номерами от 0 до m - в диапазоне возможных значений функции рассеивания. Кроме того, при заполнении файла увеличивается количество коллизий и эффективность метода падает. Если же количество записей возрастает настолько, что файл необходимо расширять, то это связано с изменением функции рассеивания и перераспределением (перезаписью) уже имеющихся записей в соответствии с новой функцией.
ГЛАВА 2. ПРАКТИЧЕСКАЯ ЧАСТЬ
2.1. Вставка элемента в в-дерево
Рассмотрим структуру узла B-дерева.
В каждом узле мы будем хранить не более NumberOfItems записей. Также нам надо будет хранить текущее количество записей в узле. Для удобства возврата назад к корню дерева будем запоминать для каждого узла указатель на его узел-предок.
Type