Курсовая работа: Модель распределения ресурсов
На протяжении всей своей истории люди при необходимости принимать решения прибегали к сложным ритуалам. Они устраивали торжественные церемонии, приносили в жертву животных, гадали по звездам и следили за полетом птиц. Они полагались на народные приметы и старались следовать примитивным правилам, облегчающим им трудную задачу принятия решений. В настоящее время для принятия решения используют новый и, по-видимому, более научный «ритуал», основанный на применении электронно-вычислительной машины. Без современных технических средств человеческий ум, вероятно, не может учесть многочисленные и разнообразные факторы, с которыми сталкиваются при управлении предприятием, конструировании ракеты или регулировании движения транспорта. Существующие в настоящее время многочисленные математические методы оптимизации уже достаточно развиты, что позволяет эффективно использовать возможности цифровых и гибридных вычислительных машин. Одним из этих методов является математическое программирование, включающее в себя как частный случай динамическое программирование.
Большинство практических задач имеет несколько (а некоторые, возможно, даже бесконечное число) решений. Целью оптимизации является нахождение наилучшего решения среди многих потенциально возможных в соответствии с некоторым критерием эффективности или качества. Задача, допускающая лишь одно решение, не требует оптимизации. Оптимизация может быть осуществлена при помощи многих стратегий, начиная с весьма сложных аналитических и численных математических процедур и кончая разумным применением простой арифметики.
Динамическое программирование – метод оптимизации, приспособленный к операциям, в которых процесс принятия решений может быть разбит на отдельные этапы (шаги). Такие операции называются многошаговыми.
Как раздел математического программирования, динамическое программирование (ДП) начало развиваться в 50-х годах XX в. благодаря работам Р. Беллмана и его сотрудников. Впервые этим методом решались задачи оптимального управления запасами, затем класс задач значительно расширился. Как практический метод оптимизации, метод динамического программирования стал возможен лишь при использовании современной вычислительной техники.
В основе метода динамического программирования лежит принцип оптимальности, сформулированный Беллманом. Этот принцип и идея включения конкретной задачи оптимизации в семейство аналогичных многошаговых задач приводят к рекуррентным соотношениям — функциональным уравнениям — относительно оптимального значения целевой функции. Их решение позволяет последовательно получить оптимальное управление для исходной задачи оптимизации.
1. Основные понятия
1.1 Модель динамического программирования
Дадим общее описание модели динамического программирования.
Рассматривается управляемая система, которая под влиянием управления переходит из начального состояния ![]() в конечное состояние
в конечное состояние ![]() . Предположим, что процесс управления системой можно разбить на п шагов. Пусть
. Предположим, что процесс управления системой можно разбить на п шагов. Пусть ![]() ,
, ![]() ,…,
,…, ![]() — состояния системы после первого, второго,..., п -го шага. Схематически это показано на рис. 1.
— состояния системы после первого, второго,..., п -го шага. Схематически это показано на рис. 1.
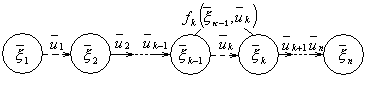
Рисунок 1
Состояние ![]() системы после k-го шага ( k = 1,2 …,n ) характеризуется параметрами
системы после k-го шага ( k = 1,2 …,n ) характеризуется параметрами ![]() ,
, ![]() ,…,
,…, ![]() которые называются фазовыми координатами. Состояние
которые называются фазовыми координатами. Состояние ![]() можно изобразить точкой s-мерного пространства называемого фазовым пространством. Последовательное преобразование системы (по шагам) достигается с помощью некоторых мероприятий
можно изобразить точкой s-мерного пространства называемого фазовым пространством. Последовательное преобразование системы (по шагам) достигается с помощью некоторых мероприятий ![]() ,
, ![]() ,…,
,…, ![]() , которые составляют управление системой
, которые составляют управление системой ![]() , где
, где ![]() — управление на k -м шаге, переводящее систему из состояния
— управление на k -м шаге, переводящее систему из состояния ![]() в состояние
в состояние ![]() (рис. 1). Управление
(рис. 1). Управление ![]() на k -ом шаге заключается в выборе значений определенных управляющих переменных*
на k -ом шаге заключается в выборе значений определенных управляющих переменных* ![]() .
.
Предполагаем впредь, что состояние системы в конце k-го шага зависит только от предшествующего состояния системы ![]() и управления
и управления ![]() на данном шаге (рис. 1). Такое свойство получило название отсутствия последействия. Обозначим эту зависимость в виде
на данном шаге (рис. 1). Такое свойство получило название отсутствия последействия. Обозначим эту зависимость в виде
![]() , (1.1)
, (1.1)
Равенства (1.1) получили название уравнений состояний. Функции ![]() полагаем заданными.
полагаем заданными.
Варьируя управление U , получим различную «эффективность» процесса** , которую будем оценивать количественно целевой функцией Z , зависящей от начального состояния системы ![]() и от выбранного управления U :
и от выбранного управления U :
![]() . (1.2)
. (1.2)
Показатель эффективности k-го шага процесса управления, который зависит от состояния ![]() в начале этого шага и управления
в начале этого шага и управления ![]() , выбранного на этом шаге, обозначим через
, выбранного на этом шаге, обозначим через ![]() рассматриваемой задаче пошаговой оптимизации целевая функция (1.2) должна быть аддитивной, т. е.
рассматриваемой задаче пошаговой оптимизации целевая функция (1.2) должна быть аддитивной, т. е.
![]() . (1.3)
. (1.3)
Если свойство аддитивности целевой функции Z не выполняется, то этого иногда можно добиться некоторыми преобразованиями функции. Например, если Z— мультипликативная функция, заданная в виде ![]() , то можно рассмотреть функцию
, то можно рассмотреть функцию ![]() , которая является аддитивной.
, которая является аддитивной.
Обычно условиями процесса на управление на каждом шаге ![]() накладываются некоторые ограничения. Управления, удовлетворяющие этим ограничениям называются допустимыми .
накладываются некоторые ограничения. Управления, удовлетворяющие этим ограничениям называются допустимыми .
Задачу пошаговой оптимизации можно сформулировать так: определить совокупность допустимых управлении ![]() ,
, ![]() ,…,
,…, ![]() , переводящих систему из начального состояния
, переводящих систему из начального состояния ![]() в конечное состояние
в конечное состояние ![]() и максимизирующих или минимизирующих показатель эффективности (1.3).
и максимизирующих или минимизирующих показатель эффективности (1.3).
Для единообразия формулировок (но не вычислительных процедур!) в дальнейшем мы будем говорить только о задаче максимизации, имея в виду, что если необходимо минимизировать Z , то, заменив Z на Z ' = —Z перейдем к максимизации Z ' .
Начальное состояние ![]() и конечное состояние
и конечное состояние ![]() могут быть заданы однозначно или могут быть указаны множество
могут быть заданы однозначно или могут быть указаны множество ![]() начальных состояний множество
начальных состояний множество ![]() конечных состояний так, что
конечных состояний так, что ![]() ,
, ![]() . В последнем случае в задаче пошаговой оптимизации требуется определить совокупность допустимых управлений, переводящих систему из начального состояния
. В последнем случае в задаче пошаговой оптимизации требуется определить совокупность допустимых управлений, переводящих систему из начального состояния ![]() в конечное состояние
в конечное состояние ![]() и максимизирующих целевую функцию (1.3). Управление, при котором достигается максимум целевой функции (1.3), называется оптимальным управлением и обозначается через
и максимизирующих целевую функцию (1.3). Управление, при котором достигается максимум целевой функции (1.3), называется оптимальным управлением и обозначается через ![]() .
.
Если переменные управления ![]() принимают дискретные значения, то модель ДП называется дискретной. Если же указанные переменные изменяются непрерывно, то модель ДП называется непрерывной. В зависимости от числа параметров состояний (s) и числа управляющих переменных на каждом шаге (r ) различают одномерные и многомерные модели ДП. Число шагов в задаче может быть либо конечным, либо бесконечным.
принимают дискретные значения, то модель ДП называется дискретной. Если же указанные переменные изменяются непрерывно, то модель ДП называется непрерывной. В зависимости от числа параметров состояний (s) и числа управляющих переменных на каждом шаге (r ) различают одномерные и многомерные модели ДП. Число шагов в задаче может быть либо конечным, либо бесконечным.
Динамическое программирование применяется при оптимизации как детерминированных, так и стохастических процессов.
В некоторых задачах, решаемых методом ДП, процесс управления естественно разбивается на шаги. Например, при распределении на несколько лет ресурсов деятельности предприятия шагом естественно считать временной период; при распределении средств между n предприятиями номером шага естественно считать номер очередного предприятия. В других задачах разбиение на шаги вводится искусственно. Например, непрерывный управляемый процесс можно рассматривать как дискретный, условно разбив его на некоторые временные отрезки — шаги. Исходя из условий каждой конкретной задачи, длину шага выбирают таким образом, чтобы на каждом шаге получить простую задачу оптимизации и обеспечить требуемую точность вычислений.
1.2 Принцип оптимальности. Уравнение Беллмана
Метод динамического программирования состоит в том, что оптимальное управление строится постепенно, шаг за шагом. На каждом шаге оптимизируется управление только этого шага. Вместе с тем на каждом шаге управление выбирается с учетом последствий, так как управление, оптимизирующее целевую функцию только для данного шага, может привести к неоптимальному эффекту всего процесса. Управление на каждом шаге должно быть оптимальным с точки зрения процесса в целом.
Иллюстрацией к сказанному выше может служить задача о выборе кратчайшего пути для перехода из точки A в точку B, если маршрут должен пройти через некоторые пункты. На рис. 2 эти пункты обозначены кружками, а соединяющие их дороги — отрезками, рядом с которыми проставлены соответствующие расстояния.

Рисунок 2
--> ЧИТАТЬ ПОЛНОСТЬЮ <--