Реферат: Описание процессоров семейства ADSP
Сигнальный процессор должен быть не только очень быстродействующим, но удовлетворять некоторым требованиям в следующих областях:
· Быстрая и гибкая арифметика – архитектура процессоров ADSP-2100 позволяет в одном производить такие операции, как умножение, умножение с накоплением, произвольное смещение, а так же ряд стандартных арифметических и логических операций в одном цикле процессора.
· Расширенный динамический диапазон – 40-разрядный аккумулятор имеет восемь резервных бит защиты от переполнения при последовательном суммировании, которые гарантируют, что потери данных быть не может.
· Выборка двух операндов за один цикл – при расширенном суммировании на каждом цикле процессора необходимо два операнда. Все члены семейства ADSP-2100 способны поддерживать обработку данных с двумя операндами, сохранены ли данные в памяти или нет.
· Аппаратные циклические буферы – большой класс алгоритмов обработки цифро-аналоговых сигналов, включая цифровые фильтры требуют наличия циклических буферов. Архитектура семейства ADSP-2100 имеет аппаратные средства для обработки указателя адреса wraparound, что упрощает реализацию круговых буферов.
· Переход по нулю – повторяющиеся алгоритмы наиболее логично выражать через циклы. Программа SequenserADSP-2100 поддерживает работу с циклическим кодом с нулем на верху, в объединении со структурой clearestэто повышает эффективность системы. Также нет препядствий для работы с условными переходами.
3. Основная архитектура
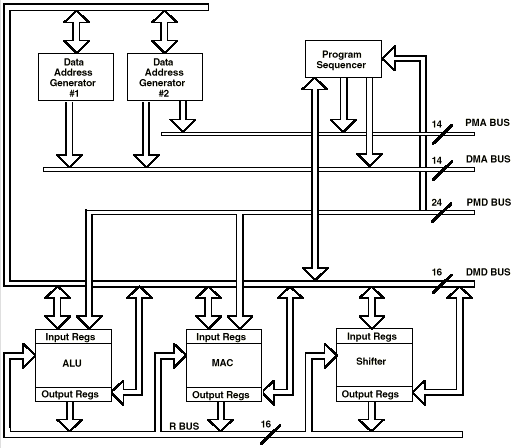
В этом разделе описывается основная архитектура процессоров семейства ADSP-2100, схема которой приведена на рис. 2.1.
3.1. Вычислительные модули
Как уже говорилось выше каждый процессор семейства ADSP-2100 содержит три независимых вычислительных модуля:
- арифметико-логический (ALU);
- умножение с накоплением (MAC);
- расширитель (shiffter).
Эти устройства работают с 16-разрядными данными и обеспечивают аппаратную поддержку мультиточности.
ALU выполняет ряд стандартных арифметических и логических комманд в дополнене к примитивам деления. MACвыполняет одноцикловые операции умножения, умножения/сложения, умножения/вычитания. Shiffter осуществляет логические и арифметические сдвиги, нормализацию, денормализацию и операцию получения порядка, атак же управление форматом данных,разрешая работу с плавоющей точкой. Вычислительные модули размещаются последовательно друг за другом, таким образом чтобы выход одного мог стать входом другого в следующем цикле. Результаты работы модулей собираются на 16-разрядную R-шину.
Все три модуля содержат входные и выходные регистры, которые доступны черех 16-разрядную DMD-шину. Комманда, выполняемые в модулях, берут в качестве операндов данные находящиеся в регистрах ввода и после выполнения записывают результат в регистры вывода. Регистры являются как бы промежуточным хранилищем между памятью и вычислительной схемой. R-шина позволяет результату одного вычисления стать операндом к другой операции. Это позволяет сэкономить время обходясь без лишних пересылок модуль-память.
|
3.2. Генераторы адресов данных и программа sequencer
Два специализированных генератора адресов данных (DAGs) и мощная программа sequencer гарантируют эффективное использование вычислительных модулей. DAGs обеспечивают адреса памяти, когда необходимо поместить данные из памяти в регистры ввода вычислительных модулей, либо сохранить в результат из выхоных регистров. Каждый DAG отвечает за четыре указателя адреса. Если указатель используется для косвенной адресации то измениятся значение некоторого регистра. С двумя генераторами процессор может выдавать два адреса одновременно для выборки из памяти двух операндов.
Для автоматической адресации модуля круговых буферов значение длины операнда может быть связано с каждым указателем. (Круговая буферная особенность также используется последовательными портами для автоматической передачи данных).
DAG1 обеспечивает адреса только для данных, DAG2 – для данных и программ. Когда в регистре состояния (MSTAT) установлен соответствующий бит режима, адрес вывода DAG1 прежде чем попасть на шину адреса инвертируется. Эта особенность облегчает работу в двоичной системе.
Программа Sequenсer обеспечивает последовательность команд и адресацию памяти программы. Sequencer управляется регистром команд, который указывает на команду, которая в данный момент выполняется. Выбранные команды записываются в регистр команд за один такт процессора и выполняются в течении следующего. Чтобы уменьшить количество циклов, sequencer поддерживает работу с условными переходами.
3.3. Шины
Процессоры семейства имеют пять внутренних шин. Шины адреса программы (PMA) и адреса данных (DMA) связаны с адресами памяти данных и программы. Шина данных программы (PMD) и шина данных (DMD) используются для передачи информации связанной с областями памяти. Шины мультиплексированы в одну внешнюю шину адреса и одну внешнюю шину данных. R-шина предназначена для передачи промежуточных результатов непосредственно между вычислительными модулями.
Адресная шина PMA шириной 14 бит обеспечивает достум к 16Кбайтам смешанной системы команд и данных. 24-разрядная шина PMD предназначена для работы с 24-битными командами.
Адресная шина DMA шириной 14 бит, обеспечивает прямой доступ к 16Кбайтам области данных. 16-разрядная шина DMD предназначена для внутренних пересылок между любыми регистрами процессора и регистров с памятью в одиночном цикле. Адрес памяти данных исходит из двух источников: абсолютное значение, определенное в системе команд (прямая адресация) или вывод данных адресует генератор (косвенная адресация). Воспользоваться данными из области команд можно лишь с помощью косвенной адресации.
Шина данных памяти программы (PMD) предназначена для передачи данных в вычислительные модули и считывания результата вычислений через PMD-DMDмодуль обмена. Этот модуль позволяет передавать данные от одной шины к другой. Он имеет аппаратные средства для перехода от 8-разрядной шины к другой.
4. Внутренние переферийные устройства
Этот раздел описывает дополнительные функциональные модули, которые включены в различные процессоры ADSP-2100 семейства.
4.1. Последовательные порты
Большенство процессоров семейства ADSP-2100 имеют по два последовательных двунаправленных порта. Порты – синхронные и используют кадровые сигналы для контроля за приемом-передачей данных. Каждый порт имеет внутренний генератор частоты, но в то же время может использовать внешний генератор. Сигналы синхронизации могут вырабатываться как самим портом, так и внешним устройством. Длина кадра обмена может меняться от трех до шести бит. Последовательный порт SPRT0 имеет многоканальные возможности и пзволяет обмен данными произвольной длины от 24 до 32 байт. Второй порт SPORT1 может быть сконфигурирован с помощью внешних прерываний IRQ0 и IRQ1.
4.2. Таймер
Регистр счета (16-разрядов) определяет время генерации прерываний, прерывание вырабатывается когда значение регистра равно нулю.
4.3. Главный интерфейсный порт (HIP)
Главный интерфейсный порт – параллельный порт ввода-вывода осуществляет прямое соединение с процессором. Через него производится обмен между ADSP-2100 и памятью главной ЭВМ. HIP состоит из регистров, через которые ADSP-2100 и главный процессор обмениваются информацией о состоянии и данными. HIP может быть сконфигурирован следующим образом:
- 8-разрядная или 16-разрядная шина;
- мультиплексная шина данных/шина адреса или отдельно шина данных и шина адреса;