Контрольная работа: Побудова лінійної регресійної моделі
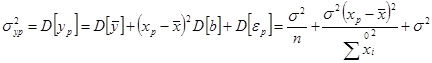
Як і раніше, замість точного значення дисперсії помилок σ2 (яке невідомо в рамках вибіркового спостереження) варто підставити її оцінку, тоді стандартна помилка прогнозу показника стає рівною
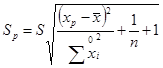
Ця середньоквадратична помилка (чи стандартна помилка), як і випливало очікувати, пропорційна стандартній помилці регресії S і росте зі збільшенням різниці між прогнозним і середнім значеннями фактора ![]() . Гранична помилка для визначення довірчого інтервалу дорівнює
. Гранична помилка для визначення довірчого інтервалу дорівнює
![]()
а границі довірчого інтервалу прогнозованого показника ![]() розширюються пропорційно квантилю tα (n - 2) розподілу Стьюдента з (п - 2) ступенями вільності і рівнем значимості α.
розширюються пропорційно квантилю tα (n - 2) розподілу Стьюдента з (п - 2) ступенями вільності і рівнем значимості α.
Очевидно, з видаленням крапки прогнозного фактора хр від середнього зона довірчого інтервалу розширюється (рис.4). Це відповідає інтуїтивному сприйняттю помилок прогнозу, що звичайно зростають при видаленні від середніх показників. Максимальна точність прогнозу досягається в крапці х – х* .
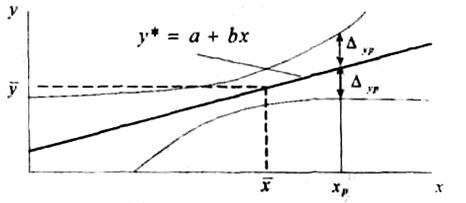
Рис. 4
7. Перевірка простої регресійної моделі на адекватність
Для оцінки знайденої економетричної моделі на адекватність порівнюють розрахункове значення критерію Фішера із табличним.
Розрахункове значення критерію Фішера знаходиться за формулою:
![]() ,
,
де ![]() ,
,
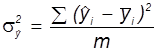 ,
,
n – число спостережень,
m – число включених у регресію факторів, які чинять суттєвий вплив на показник.
Для даної надійної ймовірності р (а=1-р рівня значущості) і числа ступенів вільності k1 =m, k2 =n-m-1 знаходиться табличне значення F(a, k1 , k2 ). Отримане розрахункове значення порівнюється з табличним. При цьому, якщо Fроз > F(a, k1 , k2 ), то з надійністю р = 1-а можна вважати, що розглянута економетрична модель адекватна вихідним даним. У протилежному випадку з надійністю р розглянуту лінійну регресію не можна вважати адекватною.
8. F - критерій Фішера
Теорія статистичної перевірки гіпотез у додатку до регресійного аналізу розроблена англійським математиком Фишером.
Нехай Н0 - гіпотеза про те, що статистичного зв'язку між X і Y немає (чи вона не істотна, статистично не значима), а Н1 - гіпотеза про те, що зв'язок є (чи вона істотна, статистично значима). Припустимо, що виконується основна гіпотеза про відсутність зв'язку. У цьому випадку щире значення коефіцієнта регресії β = 0 і F-статистика стає рівною
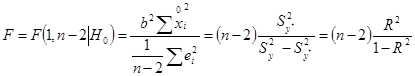
Очевидно, що з ростом значення F (чи коефіцієнта детермінації R2 ) збільшується ступінь статистичного зв'язку між фактором і показником (тому що вона прямо пропорційна коефіцієнту регресії і назад пропорційна випадковим помилкам моделі). Задамо імовірність:
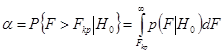
як імовірність того, що при перевищенні розрахунковим значенням F (2.47) деякого критичного значення FKp гіпотеза про відсутність зв'язку Н0 вірна. Очевидно, з імовірністю (1 - α) вона при тім же умові невірна. Закритичну область F > FKp будемо вважати областю дії гіпотези Н1 , а докритичну F < FKp - областю дії гіпотези Н0 . Тоді імовірність є імовірність помилки першого роду: α=P(H0 |H1 ), тобто імовірність прийняття основної гіпотези H0 , тоді як насправді справедлива альтернативна гіпотеза Н1 . Графічно ця імовірність визначається як площа під щільністю імовірності p(F) при F > Fk p . Імовірність α (її іноді називають коефіцієнтом значимості) звичайно вибирають малої (рівної 0,05 чи 0,01), після чого для заданих значень імовірності а розраховуються чисельно критичні значення FKp відповідно з урахуванням залежності. Ці значення табулюються, тобто заносяться в таблиці критичних коефіцієнтів чи детермінації критичних значень F-статистики.
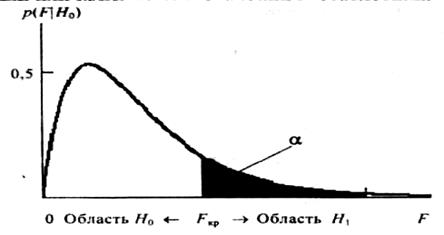
Рис. 5
Визначення значимості статистичного зв'язку для моделі лінійної регресії здійснюється по наступної методики. На основі вибіркових даних будується модель і визначається коефіцієнт детермінації R2 , що потім порівнюється з критичним коефіцієнтом детермінації R2 Kp . Останній знаходять по таблиці критичних значень коефіцієнта детермінації. Вхідними даними таблиці є коефіцієнт значимості α = 0,05 (чи 0,01), номер стовпця таблиці к1 = п - 1, номер рядка к2= п -к, де к - число параметрів моделі (для двовимірної моделі до = 2 і використовується перший стовпчик таблиці). Нагадаємо, що параметр к1 - це число ступенів волі чисельника F-статистики, к2 - число ступенів волі знаменника F-статистики. Коефіцієнт детермінації можна перерахувати в F-статистику (критерій Фишера), у загальному випадку по формулі:
![]()